7.6.1 微调路线图:数据、LoRA、评估
微调通过样本训练来改变模型行为。它适合稳定任务模式、重复格式、领域表达风格或行为习惯。它通常不是补充私有知识的第一选择,那类问题更常见的路线是 RAG。
从 Prompt 到微调的历史演进
Section titled “从 Prompt 到微调的历史演进”大模型应用不是一开始就“直接微调”。更常见的演进顺序是:
预训练模型-> Prompt-> Instruction Tuning / SFT-> RLHF / DPO-> LoRA / QLoRA / PEFT| 阶段 | 解决什么 | 什么时候不够 |
|---|---|---|
| 预训练模型 | 获得通用语言能力 | 不一定听懂具体指令和产品格式 |
| Prompt | 不改参数,快速约束任务和输出 | 行为长期不稳、格式反复漂移 |
| Instruction Tuning / SFT | 让模型学会按指令完成任务 | 只能模仿示例,不一定知道人更偏好哪种回答 |
| RLHF / DPO | 用偏好数据塑造更有帮助、诚实、安全的行为 | 成本高,需要稳定偏好和评估 |
| LoRA / QLoRA / PEFT | 低成本适配稳定任务或风格 | 不适合频繁更新知识,仍需数据和验证 |
先记住边界:知识更新优先 RAG,格式问题优先 Prompt/结构化输出,长期稳定行为问题才进入微调候选。
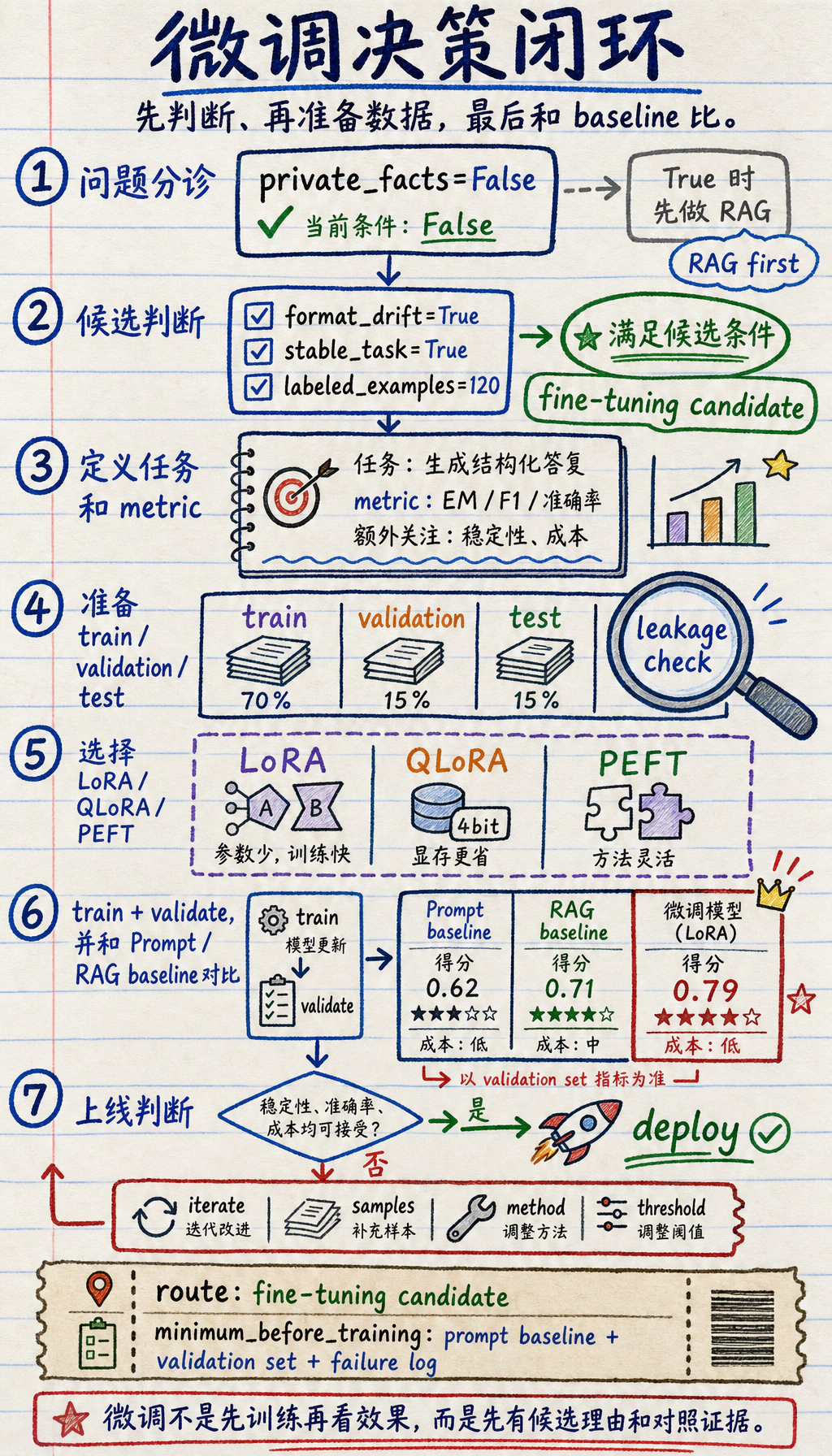
先看决策闭环
Section titled “先看决策闭环”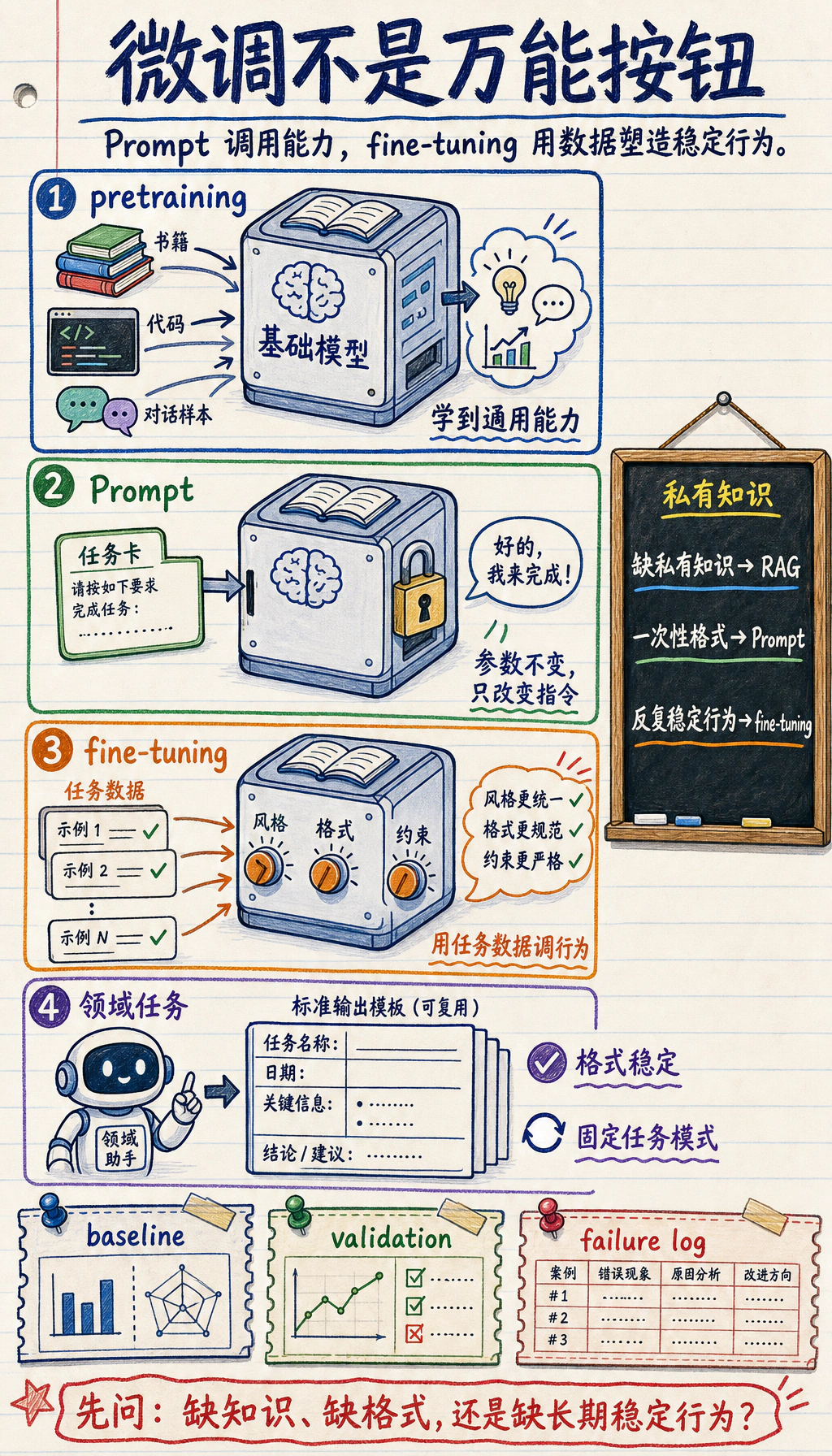
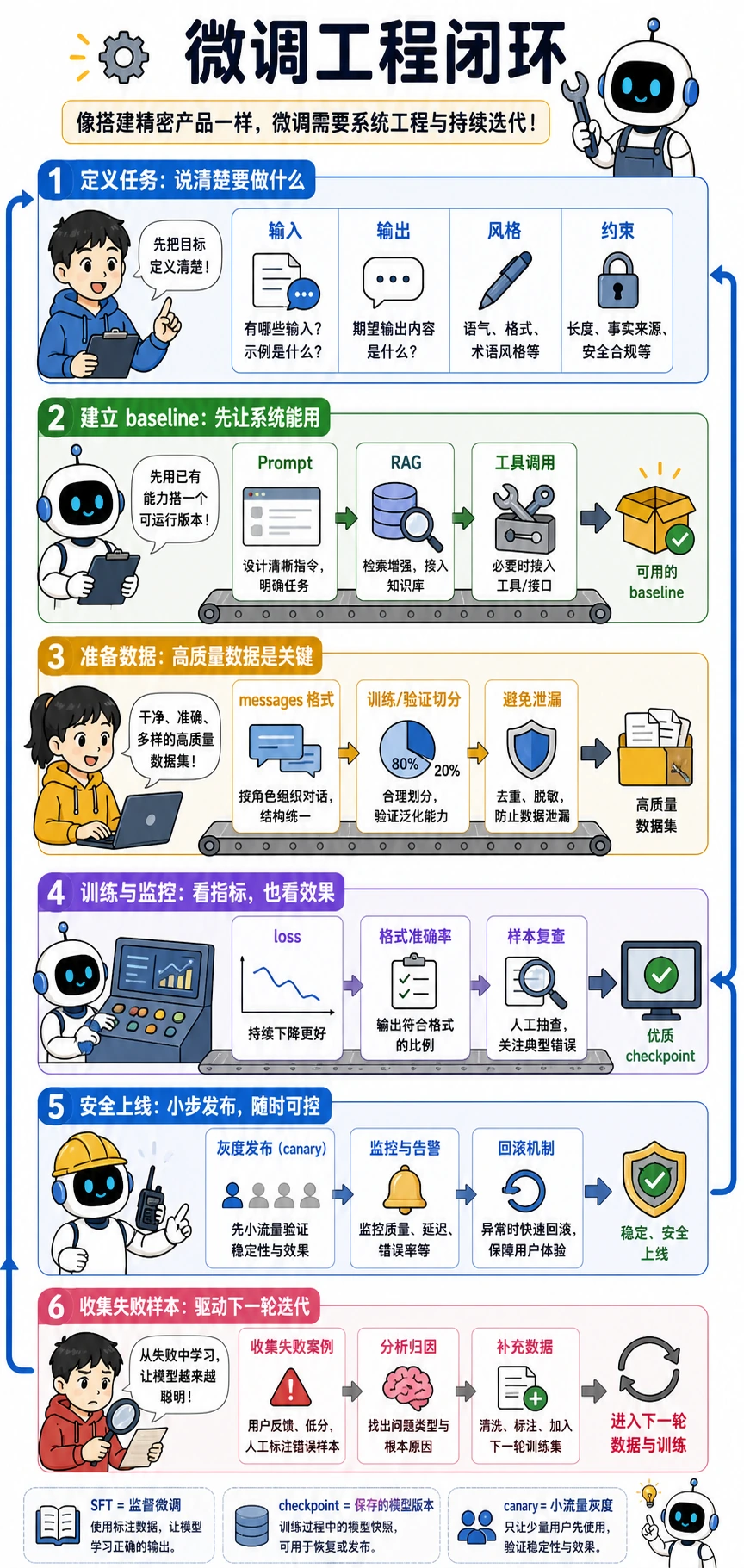
关键术语:LoRA 指低秩适配器,QLoRA 指量化版 LoRA,PEFT 指参数高效微调。它们通过训练少量新增参数,而不是更新全部模型权重,来降低成本。
跑一个微调路线检查
Section titled “跑一个微调路线检查”开始训练前先跑这个检查。没有 Prompt 基线、验证集和失败记录的微调,很难判断到底有没有变好。
case = { "private_facts": False, "format_drift": True, "stable_task": True, "labeled_examples": 120,}
if case["private_facts"]: route = "RAG first"elif case["format_drift"] and case["stable_task"] and case["labeled_examples"] >= 50: route = "fine-tuning candidate"else: route = "prompt baseline first"
print("route:", route)print("minimum_before_training:", ["prompt baseline", "validation set", "failure log"])预期输出:
route: fine-tuning candidateminimum_before_training: ['prompt baseline', 'validation set', 'failure log']每次只改一个值再重新运行。例如把 private_facts 改成 True,路线就应该先转向 RAG。
按这个顺序学
Section titled “按这个顺序学”| 步骤 | 阅读 | 实操产出 |
|---|---|---|
| 1 | 微调概览 | 写清什么时候用 Prompt、RAG 或微调 |
| 2 | LoRA / QLoRA | 解释训练哪些参数,以及为什么成本下降 |
| 3 | 其他 PEFT 方法 | 知道全量微调不是唯一选择 |
| 4 | 微调实战 | 准备训练/验证样本和一条运行命令 |
| 5 | 数据标注 | 检查格式、重复、泄漏和边界样本 |
学完这一页,至少保留这张证据卡:
- 决策
- 说明为什么 Prompt/RAG/工具化还不够
- 数据形状
- 指令、输入、输出、元数据
- 方法
- 全量微调、LoRA、QLoRA 或其他 PEFT
- 评估集
- 训练开始前的固定案例
- 风险
- 过拟合、风格漂移、安全回归,或成本过高
如果你能说明为什么微调值得尝试,展示它击败的基线,并保留没有参与训练的验证集,就通过了本章。
本章出口小项目是一份小型指令微调计划:选择一个固定任务,准备几十到几百条样本,定义 Prompt 基线,并在 LoRA/QLoRA 运行后比较格式稳定性或准确率。
检查思路与讲解
- 合格答案要说明 token、上下文、attention、prompt 和生成行为如何组成一次请求到回答的路径。
- 证据至少包含一个可复现 prompt 或结构化输出测试,并说明输出为什么通过或失败。
- 自检时要区分 prompt、RAG、微调和对齐:优先使用能解决已观察问题的最轻方案。