11.7.3 项目:文本摘要系统
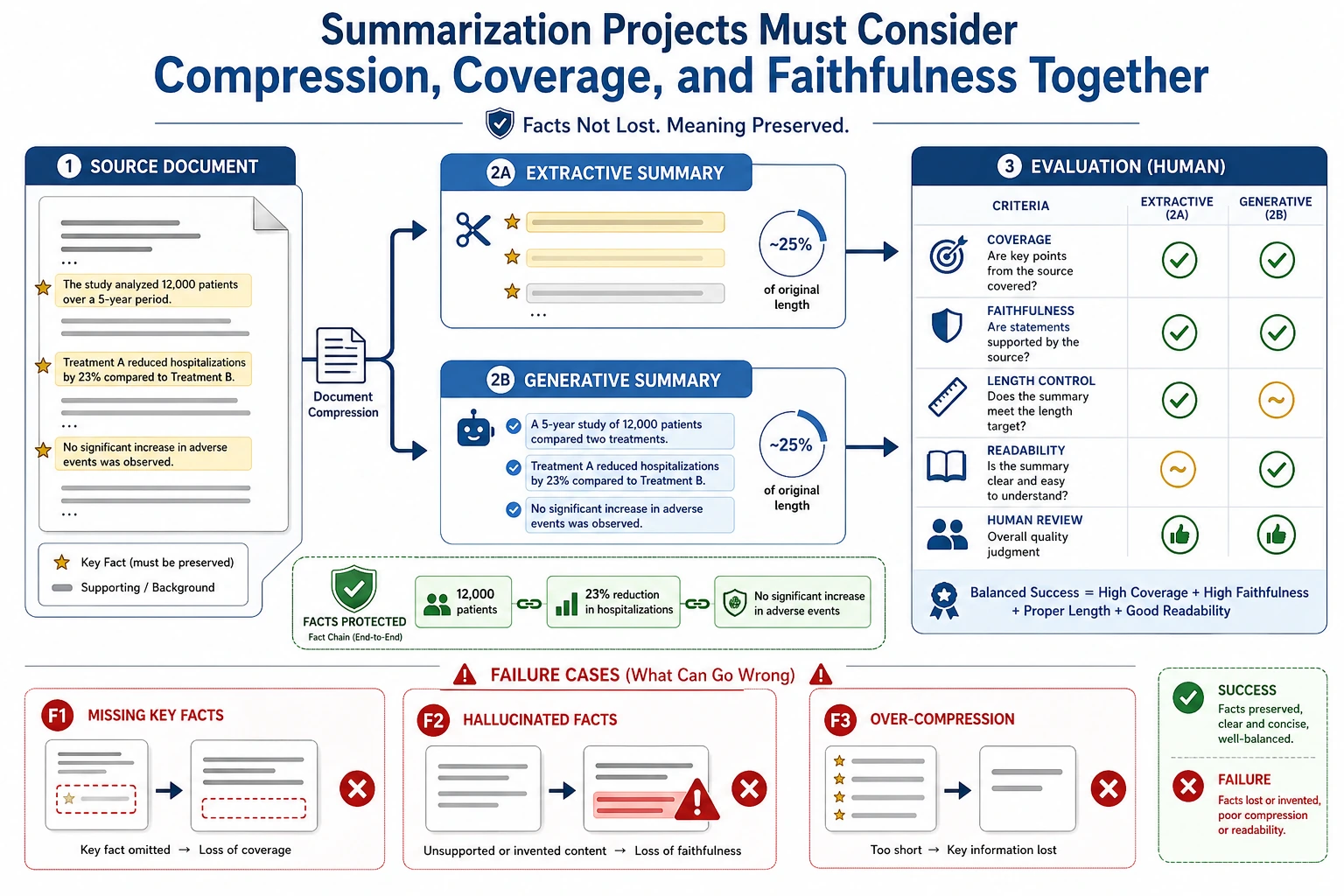
- 学会定义一个摘要项目的最小闭环
- 学会把抽取式 baseline 做成可解释系统
- 学会设计最小评估和失败分析
- 学会把这个题材包装成一个完整的 NLP 项目
先建立一张地图
Section titled “先建立一张地图”文本摘要项目最适合新人的理解顺序不是“先追更强模型”,而是先看清项目闭环:
flowchart LR A["原文"] --> B["切句"] B --> C["打分 / 选择关键信息"] C --> D["生成摘要"] D --> E["评估与失败分析"]所以这节真正想解决的是:
- 什么叫“保住主线”
- 摘要项目到底怎样评估和展示
一个更适合新人的总类比
Section titled “一个更适合新人的总类比”你可以把文本摘要理解成:
- 给一篇长文章做读书卡片
真正困难的地方不是“把字数变短”,而是:
- 不能把主线压没了
- 不能只留下边角信息
- 还要让最后的摘要读起来顺
一、项目题目怎么收窄?
Section titled “一、项目题目怎么收窄?”一个适合练手的题目可以是:
给课程长文介绍生成 2 句摘要。
这类题目好在:
- 领域清晰
- 文本长度适中
- 摘要目标比较直观
第一次做摘要项目,题目怎么选更稳?
Section titled “第一次做摘要项目,题目怎么选更稳?”更稳的起点通常有三个特点:
- 原文结构比较清楚
- 主线信息比较集中
- 读者比较容易判断“有没有漏重点”
所以像:
- 课程介绍
- 新闻简报
- 会议纪要
这类文本通常都很适合作为练手题目。
一个新人很适合先记的判断
Section titled “一个新人很适合先记的判断”第一次做摘要项目时,最值得先挑的是:
- 读者比较容易判断“哪些才是重点”的文本
因为摘要最难的一层,本来就是:
- 关键信息到底是什么
二、作品级摘要项目最小闭环
Section titled “二、作品级摘要项目最小闭环”- 选文本集合
- 切句
- 句子打分
- 选 top-k 句子
- 做人工评估
- 总结失败模式
一个很适合初学者先记的项目检查表
Section titled “一个很适合初学者先记的项目检查表”| 环节 | 你最该先确认什么 |
|---|---|
| 切句 | 句子边界是不是稳定 |
| 打分 | 是按什么标准判断“更重要” |
| 生成摘要 | top-k 句子有没有保住主线 |
| 评估 | 是不是只看“读起来顺”,还是也看“有没有漏重点” |
这个表很适合新人,因为它会把摘要项目从“抽几句就结束”,重新变成一条可以检查的项目链。
三、推荐推进顺序
Section titled “三、推荐推进顺序”对新人来说,更稳的顺序通常是:
- 先做抽取式 baseline
- 再补最小人工评估
- 再做失败案例分析
- 最后再考虑生成式摘要对比
这样你会更容易知道摘要系统到底提升了什么。
四、先做一个更完整的抽取式摘要系统
Section titled “四、先做一个更完整的抽取式摘要系统”import re
article = """人工智能课程的学习路径通常分为基础阶段和进阶阶段。基础阶段包括 Python 编程、数据分析和机器学习。当学习者掌握了这些内容之后,才能更稳地进入深度学习和大模型应用开发。很多人一开始就想直接学大模型,但往往因为基础不牢而很快卡住。如果学习目标是做 AI 应用工程,理解数据处理、模型训练和系统部署都很重要。""".strip()
def split_sentences(text): parts = re.split(r"[。!?\n]+", text) return [p.strip() for p in parts if p.strip()]
def sentence_score(sentence, all_sentences): # 极简词频打分:句子中的高频词越多,分数越高 tokens = "".join(all_sentences) return sum(tokens.count(ch) for ch in sentence if ch.strip())
def summarize(text, top_k=2): sentences = split_sentences(text) scored = [ (sentence_score(sent, sentences), idx, sent) for idx, sent in enumerate(sentences) ] top = sorted(sorted(scored, reverse=True)[:top_k], key=lambda x: x[1]) return "。".join(item[2] for item in top) + "。", scored
summary, scored = summarize(article, top_k=2)print("summary:", summary)print("top scored:", sorted(scored, reverse=True)[:2])预期输出:
summary: 当学习者掌握了这些内容之后,才能更稳地进入深度学习和大模型应用开发。如果学习目标是做 AI 应用工程,理解数据处理、模型训练和系统部署都很重要。top scored: [(66, 2, '当学习者掌握了这些内容之后,才能更稳地进入深度学习和大模型应用开发'), (65, 4, '如果学习目标是做 AI 应用工程,理解数据处理、模型训练和系统部署都很重要')]不要把分数当成真理。它更像调试信号:如果选出来的句子奇怪,就先检查打分规则,再考虑换模型。
这个示例为什么更像项目?
Section titled “这个示例为什么更像项目?”因为它不只给你结果, 还保留了:
- 切句结果
- 打分结果
这让你能做:
- 解释
- 调试
- 失败分析
为什么摘要项目特别值得展示中间分数?
Section titled “为什么摘要项目特别值得展示中间分数?”因为摘要好不好本来就带主观性。 中间打分过程能帮助别人理解:
- 你是怎样做选择的
再看一个最小“摘要长度控制”示例
Section titled “再看一个最小“摘要长度控制”示例”for k in [1, 2, 3]: summary_k, _ = summarize(article, top_k=k) print(f"top_k={k} -> {summary_k}")预期输出:
top_k=1 -> 当学习者掌握了这些内容之后,才能更稳地进入深度学习和大模型应用开发。top_k=2 -> 当学习者掌握了这些内容之后,才能更稳地进入深度学习和大模型应用开发。如果学习目标是做 AI 应用工程,理解数据处理、模型训练和系统部署都很重要。top_k=3 -> 人工智能课程的学习路径通常分为基础阶段和进阶阶段。当学习者掌握了这些内容之后,才能更稳地进入深度学习和大模型应用开发。如果学习目标是做 AI 应用工程,理解数据处理、模型训练和系统部署都很重要。这个示例很适合初学者,因为它会帮助你立住一个关键感觉:
- 摘要不是句子越多越好
- 也不是越短越高级
而是:
- 在长度约束下尽量保住主线
五、一个最小人工评估表该长什么样?
Section titled “五、一个最小人工评估表该长什么样?”eval_cases = [ { "text": article, "gold_focus": ["基础阶段", "深度学习和大模型", "系统部署"], }]
for case in eval_cases: pred_summary, _ = summarize(case["text"], top_k=2) covered = [item for item in case["gold_focus"] if item in pred_summary] print({ "summary": pred_summary, "covered_focus": covered, "coverage_ratio": round(len(covered) / len(case["gold_focus"]), 4), })预期输出:
{'summary': '当学习者掌握了这些内容之后,才能更稳地进入深度学习和大模型应用开发。如果学习目标是做 AI 应用工程,理解数据处理、模型训练和系统部署都很重要。', 'covered_focus': ['深度学习和大模型', '系统部署'], 'coverage_ratio': 0.6667}覆盖率不满分不是坏事,反而是这个练习的重点:一个朴素 baseline 可能读起来还行,但仍会漏掉关键学习路径信息。
这个评估为什么简单但有用?
Section titled “这个评估为什么简单但有用?”因为它逼你回答:
- 摘要到底保没保住主线
这比只看“读起来顺不顺”更具体。
六、摘要项目最值得展示的失败案例
Section titled “六、摘要项目最值得展示的失败案例”例如:
- 选句重复
- 漏掉关键信息
- 句子顺序不自然
为什么这些很值得展示?
Section titled “为什么这些很值得展示?”因为它们恰好体现了抽取式摘要的典型局限。
一个很适合新人的失败分析框架
Section titled “一个很适合新人的失败分析框架”你可以先按这三类去分:
- 漏掉主线信息
- 句子重复或冗余
- 句子本身对,但组合起来不自然
这样比只说“这个摘要不太好”更容易推进下一步改进。
一个新人可直接照抄的错误分桶表
Section titled “一个新人可直接照抄的错误分桶表”| 错误类型 | 你下一步更可能先改什么 |
|---|---|
| 漏掉主线信息 | 句子打分规则 |
| 句子重复 | 去冗余策略 |
| 组合不自然 | 句子排序或生成式改写 |
这个表很适合新人,因为它能帮助你把“摘要不太好”重新拆回具体可改的问题。
七、怎么把这个项目再推成作品级?
Section titled “七、怎么把这个项目再推成作品级?”加一个生成式摘要对比
Section titled “加一个生成式摘要对比”增加更多文本类型
Section titled “增加更多文本类型”例如:
- 新闻
- 课程介绍
- 会议纪要
做一页 before / after 展示
Section titled “做一页 before / after 展示”例如:
- 原文
- baseline 摘要
- 调优后摘要
- 失败分析
项目交付时最好补上的内容
Section titled “项目交付时最好补上的内容”- 原文 / 摘要对照
- 中间句子得分表
- 一组失败摘要案例
- 一段你对“什么叫关键信息”的定义说明
如果把它做成作品集,最值得强调什么
Section titled “如果把它做成作品集,最值得强调什么”最值得强调的通常不是:
- “我做了摘要模型”
而是:
- 你的 baseline 怎么挑句
- 你怎么定义“保住主线”
- 中间句子得分怎么展示
- 错误案例主要是什么
这样别人会更容易看出:
- 你理解的是摘要项目的判断标准
- 不只是把文本压短了
如果继续往上做,这个项目最值得补什么
Section titled “如果继续往上做,这个项目最值得补什么”更值得优先补的通常是:
- 更稳的句子打分特征
- 更好的人工评估标准
- 抽取式和生成式摘要的对比页
这样你的项目就会从“能跑”进一步变成“能比较、能解释、能展示”。
学完这一页,至少保留这张证据卡:
- 任务输出
- 标签、实体字段、摘要、答案、检索结果或语义图
- 工件
- 原始文本、处理后文本、预测、指标和失败案例
- 指标
- 准确率/F1、精确率/召回率、检索命中率、忠实度或 schema 有效性
- 失败检查
- 标签不清、过度清洗、边界错误、幻觉或答案无依据
- 期望产出
- 可复现的文本流程文件夹,包含指标和示例
这节最重要的是建立一个作品级判断:
摘要项目的关键,不只是能抽几句,而是你能否把“切句、打分、生成、评估和失败分析”讲成一个可解释的闭环。
只要这个闭环清楚,文本摘要项目就会非常像一个成熟的 NLP 作品。
版本路线建议
Section titled “版本路线建议”| 版本 | 目标 | 交付重点 |
|---|---|---|
| 基础版 | 跑通最小闭环 | 能输入、能处理、能输出,并保留一组示例 |
| 标准版 | 形成可展示项目 | 增加配置、日志、错误处理、README 和截图 |
| 挑战版 | 接近作品集质量 | 增加评估、对比实验、失败样本分析和下一步路线 |
建议先完成基础版,不要一开始就追求大而全。每提升一个版本,都要把“新增了什么能力、怎么验证、还有什么问题”写进 README。
- 把
top_k改成 1 和 3,观察摘要内容怎么变化。 - 为什么摘要项目特别值得展示“中间打分结果”?
- 想一想:抽取式摘要最容易出现哪类失败?
- 如果你要把这个项目放进作品集,你会优先展示哪 4 部分?
项目交付参考与讲解
top_k=1时摘要更短但可能缺上下文;top_k=3时证据更多,但可能冗余。- 展示中间打分很有价值,因为它解释每句话为什么被选中,也方便做失败分析。
- 抽取式摘要常见失败是漏掉跨句上下文、选出重复句,或遗漏关键条件。
- 作品集版本应展示原文、打分表、选出的摘要、事实检查和失败/改进记录。