3.2.6 线性代数基础操作
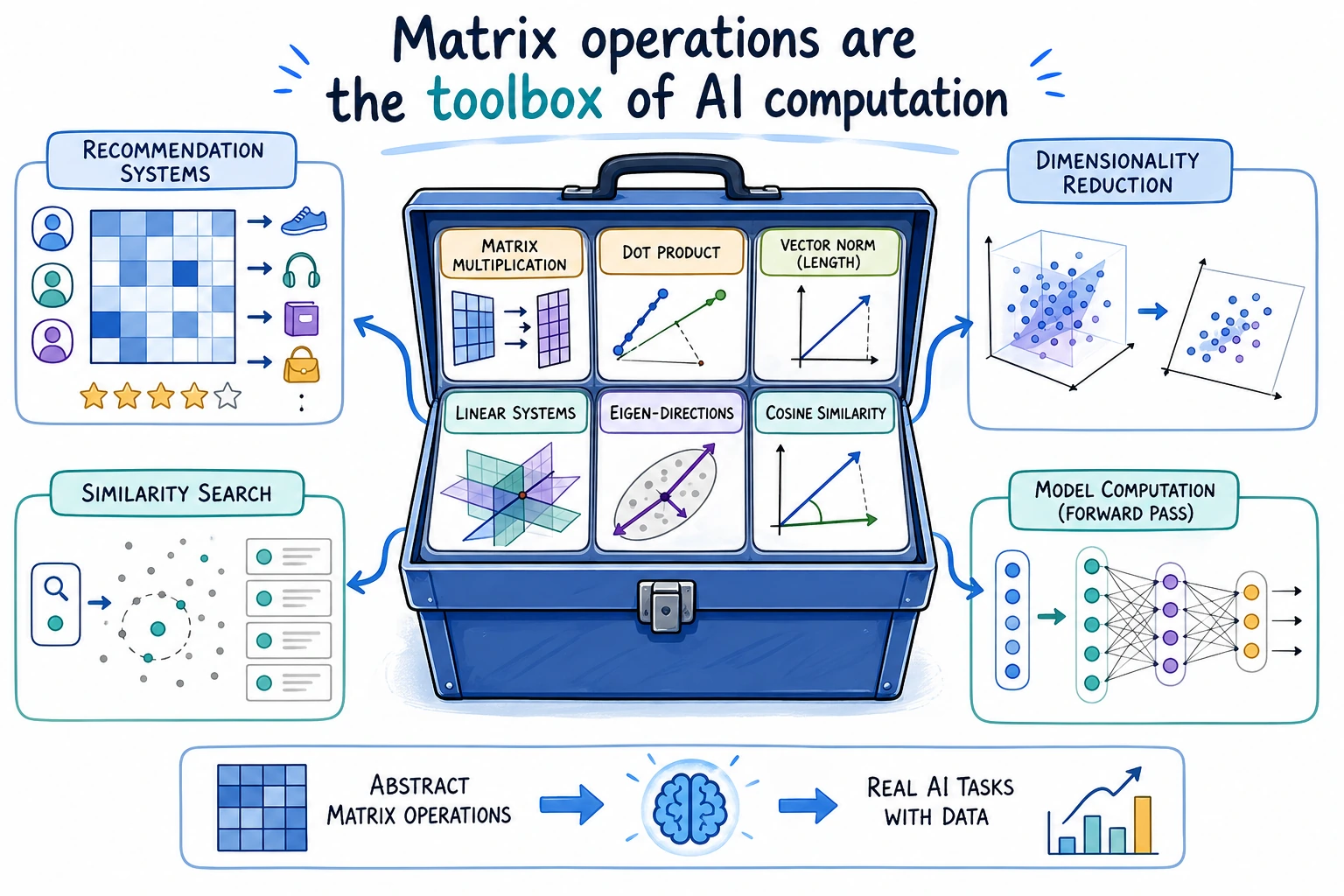
- 掌握矩阵乘法的三种写法(dot、matmul、@)
- 了解逆矩阵、行列式、特征值的含义和计算
- 学会用
numpy.linalg模块进行线性代数运算 - 理解线性代数在 AI 中的重要性
为什么要学线性代数?
Section titled “为什么要学线性代数?”你可能觉得”线性代数”听起来很数学、很抽象。但在 AI 领域,它是最核心的数学基础:
| AI 场景 | 线性代数的角色 |
|---|---|
| 神经网络 | 每一层的运算就是矩阵乘法 |
| 推荐系统 | 用户-商品矩阵分解 |
| 图像处理 | 一张图片就是一个矩阵 |
| 词向量 | 每个词是一个向量,相似度 = 点积 |
| 降维 | PCA 就是求特征值和特征向量 |
现在先用 NumPy 操作一下这些概念,建立直觉。4 AI 数学最小必要基础会更深入地讲解原理。
元素乘法 vs 矩阵乘法
Section titled “元素乘法 vs 矩阵乘法”这是新手最容易搞混的地方:
import numpy as np
A = np.array([[1, 2], [3, 4]])B = np.array([[5, 6], [7, 8]])
# 元素乘法(逐位相乘)print(A * B)# [[ 5 12]# [21 32]]# 计算过程:1×5=5, 2×6=12, 3×7=21, 4×8=32
# 矩阵乘法print(A @ B)# [[19 22]# [43 50]]# 计算过程:# [1×5+2×7, 1×6+2×8] = [19, 22]# [3×5+4×7, 3×6+4×8] = [43, 50]矩阵乘法的三种写法
Section titled “矩阵乘法的三种写法”A = np.array([[1, 2], [3, 4]])B = np.array([[5, 6], [7, 8]])
# 方法 1:@ 运算符(推荐,最简洁)C1 = A @ B
# 方法 2:np.matmulC2 = np.matmul(A, B)
# 方法 3:np.dotC3 = np.dot(A, B)
# 三种方法结果完全一样print(np.array_equal(C1, C2)) # Trueprint(np.array_equal(C2, C3)) # True矩阵乘法的规则
Section titled “矩阵乘法的规则”两个矩阵能相乘的条件:前面的列数 = 后面的行数。
# (2, 3) @ (3, 4) → (2, 4) ✅ 3 == 3A = np.ones((2, 3))B = np.ones((3, 4))C = A @ Bprint(C.shape) # (2, 4)
# (2, 3) @ (2, 4) → ❌ 报错!3 ≠ 2# A = np.ones((2, 3))# B = np.ones((2, 4))# C = A @ B # ValueError!记忆口诀:(m, n) @ (n, p) → (m, p)
一维数组的 @ 或 np.dot 计算的是点积(内积):
a = np.array([1, 2, 3])b = np.array([4, 5, 6])
# 点积 = 1×4 + 2×5 + 3×6 = 32print(a @ b) # 32print(np.dot(a, b)) # 32点积在 AI 中非常重要——后面学到余弦相似度和注意力机制时都会用到。
numpy.linalg 模块
Section titled “numpy.linalg 模块”NumPy 的 linalg 子模块提供了完整的线性代数功能:
矩阵的逆满足 A × A⁻¹ = 单位矩阵:
A = np.array([[1, 2], [3, 4]])
# 求逆矩阵A_inv = np.linalg.inv(A)print(A_inv)# [[-2. 1. ]# [ 1.5 -0.5]]
# 验证:A × A_inv ≈ 单位矩阵print(A @ A_inv)# [[1.0000000e+00 0.0000000e+00]# [8.8817842e-16 1.0000000e+00]]# 对角线是 1,其余接近 0(浮点精度误差)行列式是一个标量值,表示矩阵的”缩放因子”:
A = np.array([[1, 2], [3, 4]])det = np.linalg.det(A)print(f"行列式: {det:.1f}") # -2.0
# 2×2 矩阵的行列式 = ad - bc# [[a, b], [c, d]] → 1×4 - 2×3 = -2特征值和特征向量
Section titled “特征值和特征向量”特征值和特征向量是矩阵的”DNA”——揭示矩阵的内在性质:
A = np.array([[4, 2], [1, 3]])
# 求特征值和特征向量eigenvalues, eigenvectors = np.linalg.eig(A)print(f"特征值: {eigenvalues}") # [5. 2.]print(f"特征向量:\n{eigenvectors}")# [[ 0.894 -0.707]# [ 0.447 0.707]]解线性方程组
Section titled “解线性方程组”解方程:2x + y = 5x + 3y = 7用矩阵形式:Ax = b
A = np.array([[2, 1], [1, 3]])b = np.array([5, 7])
# 解方程x = np.linalg.solve(A, b)print(f"x = {x[0]:.2f}, y = {x[1]:.2f}") # x = 1.60, y = 1.80
# 验证print(A @ x) # [5. 7.] ← 等于 b,说明解正确其他实用操作
Section titled “其他实用操作”范数(向量的长度)
Section titled “范数(向量的长度)”v = np.array([3, 4])
# L2 范数(欧几里得距离)l2 = np.linalg.norm(v)print(f"L2 范数: {l2}") # 5.0 (3² + 4² = 25, √25 = 5)
# L1 范数(绝对值之和)l1 = np.linalg.norm(v, ord=1)print(f"L1 范数: {l1}") # 7.0 (|3| + |4| = 7)
# 矩阵的范数M = np.array([[1, 2], [3, 4]])print(f"矩阵 Frobenius 范数: {np.linalg.norm(M):.2f}") # 5.48A = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])rank = np.linalg.matrix_rank(A)print(f"矩阵的秩: {rank}") # 2(不是满秩,因为第三行 = 第一行×(-1) + 第二行×2)常用函数速查
Section titled “常用函数速查”| 函数 | 作用 | 示例 |
|---|---|---|
A @ B | 矩阵乘法 | np.array([[1,2],[3,4]]) @ np.eye(2) |
np.linalg.inv(A) | 逆矩阵 | |
np.linalg.det(A) | 行列式 | |
np.linalg.eig(A) | 特征值和特征向量 | |
np.linalg.solve(A, b) | 解方程 Ax=b | |
np.linalg.norm(v) | 范数 | |
np.linalg.matrix_rank(A) | 矩阵的秩 | |
A.T | 转置 | |
np.trace(A) | 迹(对角线之和) |
实战:计算余弦相似度
Section titled “实战:计算余弦相似度”余弦相似度是 AI 中衡量两个向量”相似程度”的常用方法。后面在词向量、推荐系统、RAG 中都会反复使用。
公式:cos(θ) = (a · b) / (||a|| × ||b||)
import numpy as np
def cosine_similarity(a, b): """计算两个向量的余弦相似度""" dot_product = a @ b # 点积 norm_a = np.linalg.norm(a) # a 的长度 norm_b = np.linalg.norm(b) # b 的长度 return dot_product / (norm_a * norm_b)
# 示例:比较模型服务画像# 维度代表:[准确率, 吞吐, 低延迟, 低内存, 稳定性]baseline = np.array([4, 3, 2, 2, 4])quantized = np.array([4, 3, 3, 3, 4])experimental = np.array([2, 5, 5, 4, 2])
print(f"Baseline vs quantized: {cosine_similarity(baseline, quantized):.4f}") # 0.9857print(f"Baseline vs experimental: {cosine_similarity(baseline, experimental):.4f}") # 0.8137print(f"Quantized vs experimental: {cosine_similarity(quantized, experimental):.4f}") # 0.8778学完这一页,至少保留这张证据卡:
- 数组状态
- 操作前的形状、dtype、轴和样本值
- 操作
- 索引、切片、广播、reshape、线性代数,或随机/统计函数
- 输出
- 结果数组形状、值,或统计量
- 失败检查
- 轴混淆、视图/副本陷阱、广播不匹配或形状错误
- 期望产出
- 打印的形状和值,便于检查数组运算
| 概念 | 说明 | NumPy 函数 |
|---|---|---|
| 矩阵乘法 | (m,n) @ (n,p) → (m,p) | A @ B 或 np.matmul |
| 逆矩阵 | A × A⁻¹ = I | np.linalg.inv() |
| 行列式 | 矩阵的缩放因子 | np.linalg.det() |
| 特征值/向量 | 矩阵的”DNA” | np.linalg.eig() |
| 解方程 | 解 Ax = b | np.linalg.solve() |
| 范数 | 向量的长度 | np.linalg.norm() |
练习 1:矩阵乘法
Section titled “练习 1:矩阵乘法”# 3 个流水线阶段的单请求资源成本cost_per_stage = np.array([4, 12, 6]) # [embed, rerank, generate]
# 3 个请求批次的阶段调用次数stage_counts = np.array([ [3, 1, 2], # 批次 1 [0, 2, 5], # 批次 2 [5, 0, 3] # 批次 3])
# 用矩阵乘法计算每个批次的总成本# totals = ?练习 2:解方程
Section titled “练习 2:解方程”# 解方程组:# 3x + 2y - z = 1# x - y + 2z = 5# 2x + 3y - z = 0## 提示:写成 Ax = b 的形式练习 3:余弦相似度应用
Section titled “练习 3:余弦相似度应用”# 假设有几个模型服务画像# 维度代表:[准确率, 吞吐, 低延迟, 低内存, 稳定性]profiles = { "baseline": np.array([4, 3, 2, 2, 4]), "quantized": np.array([4, 3, 3, 3, 4]), "experimental": np.array([2, 5, 5, 4, 2]),}
# 用余弦相似度找出和 "baseline" 最相似的画像# 提示:计算 "baseline" 和其他每个画像的余弦相似度参考实现与讲解
- 资源成本示例里,
stage_counts @ cost_per_stage是最清晰的向量化答案。若成本为[4, 12, 6],调用次数行是[3,1,2]、[0,2,5]、[5,0,3],总成本分别是36、54、38。 - 线性方程组
3x + 2y - z = 1、x - y + 2z = 5、2x + 3y - z = 0用np.linalg.solve应得到x=1、y=0、z=2。 - 画像余弦相似度练习中,要用向量长度归一化后的结果比较。最相似的是余弦值最大的画像,而不是原始点积最大的画像。