6.2.8 实用技巧
- 写出兼容 CPU、CUDA、Apple MPS 的 device 安全代码。
- 固定常见随机来源,方便复现和调试。
- 梯度爆炸时使用梯度裁剪。
- CUDA 可用时使用 AMP,并在其他设备上安全降级。
- 保存和恢复 checkpoint。
- loss 不下降时按顺序排查。
先看排查顺序
Section titled “先看排查顺序”训练坏掉时,先查简单工程问题,不要一上来重设计模型。
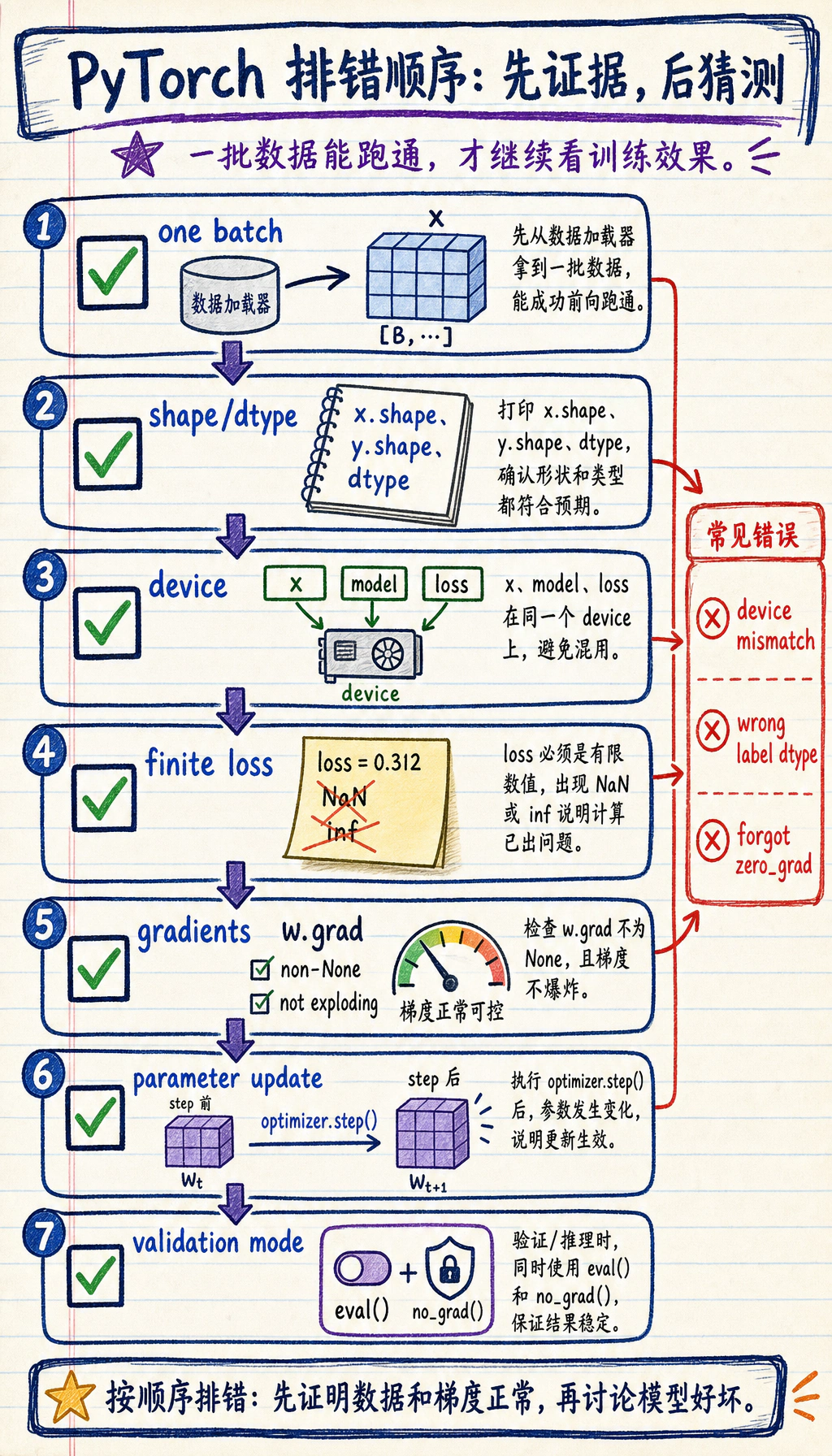
按这个顺序:
- 一个 batch 是否加载正确?
- shape 和 dtype 是否匹配模型与 loss?
- 模型和数据是否在同一个 device?
- loss 是否是有限数?
- 梯度是否非
None,并且没有爆炸? optimizer.step()后参数是否真的更新?- 验证和预测是否用了
eval()和no_grad()?
实验 1:Device 和 Seed
Section titled “实验 1:Device 和 Seed”这个实验可在 CPU、CUDA 或 Apple Silicon MPS 上运行。
import random
import numpy as npimport torch
if torch.cuda.is_available(): device = torch.device("cuda")elif torch.backends.mps.is_available(): device = torch.device("mps")else: device = torch.device("cpu")
def set_seed(seed=42): random.seed(seed) np.random.seed(seed) torch.manual_seed(seed) if torch.cuda.is_available(): torch.cuda.manual_seed_all(seed)
print("device_seed_lab")print("device:", device)
set_seed(42)a = torch.randn(3)set_seed(42)b = torch.randn(3)
print("same random:", torch.equal(a, b))print("sample:", a)示例输出:
device_seed_labdevice: mpssame random: Truesample: tensor([0.3367, 0.1288, 0.2345])你的 device 可能是 cpu、cuda 或 mps。
复现性说明:
- Seed 会让调试容易很多。
- 某些 GPU 算子和并行细节仍可能带来微小差异。
- 目标是“足够可复现,便于调试”,不是所有环境都数学上完全一致。
实验 2:梯度裁剪
Section titled “实验 2:梯度裁剪”梯度裁剪会在 optimizer 更新前限制梯度范数。RNN、Transformer 和不稳定深层网络里很常见。
import torchfrom torch import nn
torch.manual_seed(42)
model = nn.Sequential( nn.Linear(10, 20), nn.ReLU(), nn.Linear(20, 1),)
x = torch.randn(32, 10)y = torch.randn(32, 1) * 50
loss = nn.MSELoss()(model(x), y)loss.backward()
def grad_norm(model): total = 0.0 for param in model.parameters(): if param.grad is not None: total += param.grad.norm(2).item() ** 2 return total ** 0.5
print("grad_clip_lab")before = grad_norm(model)torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0)after = grad_norm(model)
print("before:", round(before, 4))print("after:", round(after, 4))预期输出:
grad_clip_labbefore: 38.7677after: 1.0裁剪放在这里:
zero_gradbackwardclip gradientsoptimizer.step
不要在 backward() 前裁剪,因为那时梯度还不存在。
实验 3:AMP 与安全降级
Section titled “实验 3:AMP 与安全降级”AMP 是自动混合精度。在 CUDA GPU 上,它可以减少显存占用并加速训练。在 CPU 或 MPS 上,这个例子会退回普通精度。
import torchfrom torch import nn
if torch.cuda.is_available(): device = torch.device("cuda")elif torch.backends.mps.is_available(): device = torch.device("mps")else: device = torch.device("cpu")
model = nn.Sequential(nn.Linear(16, 32), nn.ReLU(), nn.Linear(32, 1)).to(device)optimizer = torch.optim.Adam(model.parameters(), lr=0.01)loss_fn = nn.MSELoss()
x = torch.randn(64, 16, device=device)y = torch.randn(64, 1, device=device)
print("amp_lab")if device.type == "cuda": scaler = torch.amp.GradScaler("cuda") for _ in range(3): optimizer.zero_grad() with torch.amp.autocast("cuda"): loss = loss_fn(model(x), y) scaler.scale(loss).backward() scaler.step(optimizer) scaler.update() print("used AMP on cuda")else: for _ in range(3): optimizer.zero_grad() loss = loss_fn(model(x), y) loss.backward() optimizer.step() print("used standard precision on", device.type)示例输出:
amp_labused standard precision on mps适合使用 AMP 的情况:
- 使用 CUDA 训练;
- 显存紧张;
- 模型适合混合精度。
保留普通精度的情况:
- 正在排查数值问题;
- 在 CPU 上跑很小的例子;
- 需要最简单的 baseline。
实验 4:保存和恢复 Checkpoint
Section titled “实验 4:保存和恢复 Checkpoint”Checkpoint 通常应包含:
model.state_dict();optimizer.state_dict();- epoch;
- 最佳验证指标;
- 必要时还包括配置或标签映射。
这个实验使用临时目录,不会留下文件。
import osimport tempfile
import torchfrom torch import nn
model = nn.Linear(2, 1)optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
print("checkpoint_lab")with tempfile.TemporaryDirectory() as tmp: checkpoint_path = os.path.join(tmp, "demo_checkpoint.pt")
torch.save( { "model_state_dict": model.state_dict(), "optimizer_state_dict": optimizer.state_dict(), "epoch": 5, "best_val": 0.123, }, checkpoint_path, )
new_model = nn.Linear(2, 1) new_optimizer = torch.optim.SGD(new_model.parameters(), lr=0.1)
ckpt = torch.load(checkpoint_path, map_location="cpu") new_model.load_state_dict(ckpt["model_state_dict"]) new_optimizer.load_state_dict(ckpt["optimizer_state_dict"])
print("restored epoch:", ckpt["epoch"]) print("restored best_val:", ckpt["best_val"])预期输出:
checkpoint_labrestored epoch: 5restored best_val: 0.123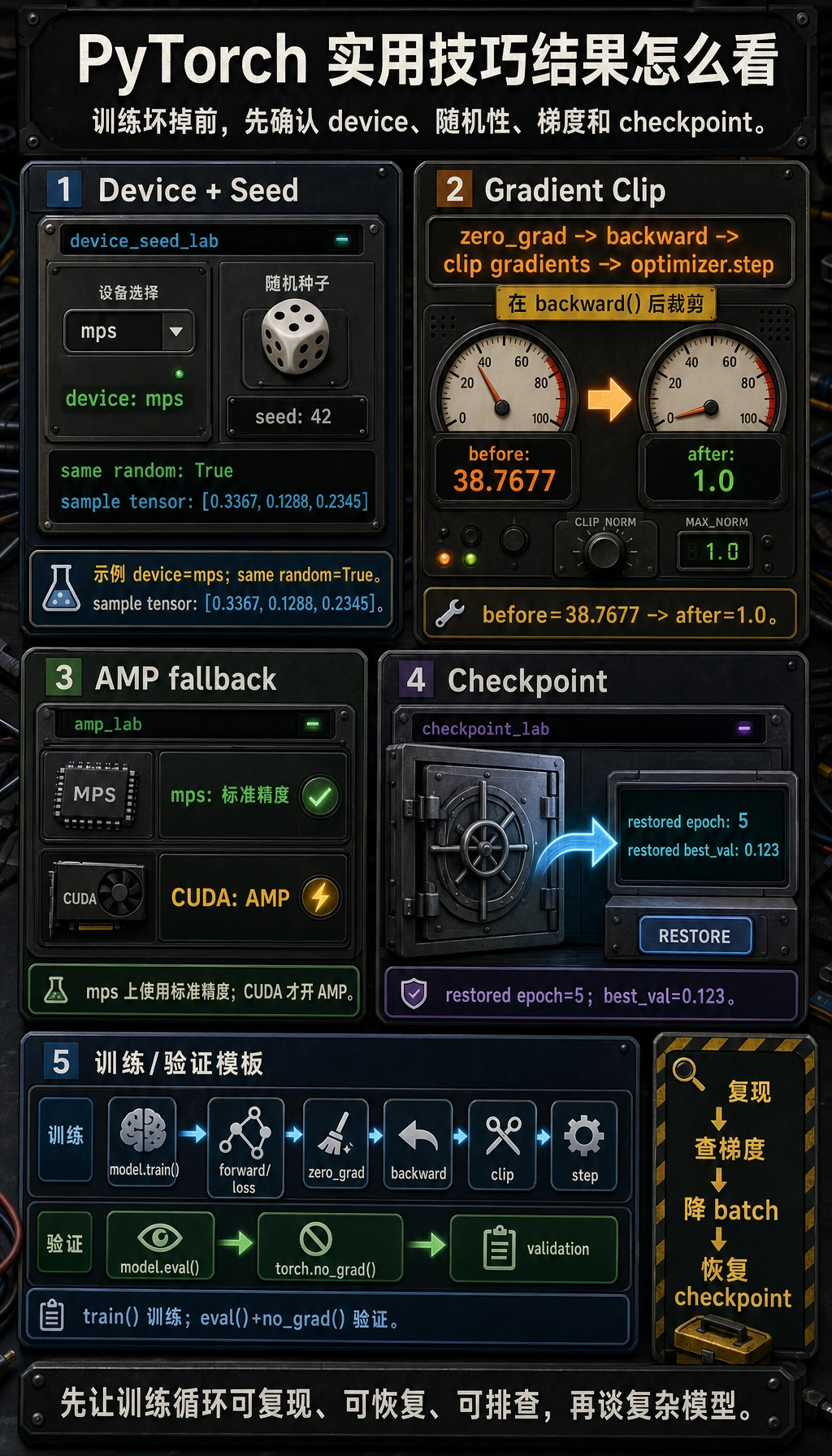
真实项目里通常保存到稳定路径,比如:
checkpoints/best_model.pt每个 PyTorch 项目都保留一条运行安全笔记:
- 设备
- cpu/cuda/mps,且模型与数据匹配
- 种子
- 在调试前设置
- 梯度范数
- 在不稳定时,于裁剪前后测量
- 精度
- 仅在支持时使用 AMP,回退也能工作
- 检查点
- model_state_dict、optimizer_state_dict、epoch、best_val
- 调试顺序
- 批次 → 形状 → 设备 → 损失 → 梯度 → 更新 → 验证
内存和稳定性排查
Section titled “内存和稳定性排查”| 现象 | 第一反应 | 下一步 |
|---|---|---|
| out of memory | 降低 batch_size | CUDA 上用 AMP,再考虑梯度累积 |
loss 变成 nan | 降低学习率 | 检查输入,加入梯度裁剪 |
| 验证很慢 | 加 model.eval() 和 torch.no_grad() | 降低验证频率 |
| 每次训练结果差很多 | 设置 seed | 记录配置和数据切分 |
| checkpoint 加载失败 | 检查架构和 key 名 | 查看 state_dict().keys() |
梯度累积的直觉:
大有效 batch = 多次小 forward/backward + 一次 optimizer step当显存放不下一整个大 batch 时,它很有用。
可保存训练模板
Section titled “可保存训练模板”model.train()for batch_x, batch_y in train_loader: batch_x = batch_x.to(device) batch_y = batch_y.to(device)
pred = model(batch_x) loss = loss_fn(pred, batch_y)
optimizer.zero_grad() loss.backward() torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0) optimizer.step()
model.eval()with torch.no_grad(): for batch_x, batch_y in val_loader: batch_x = batch_x.to(device) batch_y = batch_y.to(device) pred = model(batch_x) val_loss = loss_fn(pred, batch_y)这个模板不花哨,但能防住最常见的 PyTorch 训练错误。
- 给你之前的训练循环加入 device 处理,确认模型和数据在同一设备。
- 在自己的模型里打印梯度裁剪前后的梯度范数。
- 为最佳验证 loss 加入 checkpoint 保存。
- 临时提高学习率直到 loss 不稳定,再通过降低学习率和裁剪梯度恢复。
解题思路与讲解
- 模型、输入 tensor、标签,以及训练循环内部新建的 tensor 都要移动到同一个
device。打印 device 或加一个简单断言,能提前拦住很多运行时错误。 - 裁剪后,梯度范数应该被限制在你设置的阈值附近。如果裁剪前范数非常大,还要检查 learning rate、loss scale 和数据取值。
- 至少保存
model.state_dict()、最佳 validation loss 和 epoch。若要恢复训练,还应保存 optimizer state 和配置。 - 过高 learning rate 常见表现是 loss 尖峰、震荡或
nan。降低 learning rate 和 gradient clipping 能稳定训练,但不能修复错误标签、错误 shape 或数据泄漏。
- 不要硬编码
.cuda();选择 device,并同时移动模型和数据。 - 调试训练行为前先设置 seed。
- 梯度裁剪放在
backward()后、step()前。 - AMP 主要用于 CUDA,同时保留简单降级路径。
- checkpoint 应保存模型状态、优化器状态、epoch 和验证指标。