10.3.5 检测实战
- 学会定义一个最小目标检测项目
- 理解检测项目里的标注、框匹配和评估逻辑
- 通过可运行示例建立 IoU 驱动的评估直觉
- 建立检测项目的展示骨架
先建立一张地图
Section titled “先建立一张地图”如果你刚学完检测概述、经典检测器和 YOLO,这一节最自然的续接就是:
- 前面你已经知道检测任务在解决什么
- 这一节开始问“如果把它做成一个真的项目,第一步到底该怎么下手”
所以这节真正重要的不是新模型,而是:
- 类别定义
- 标注规范
- 评估口径
- 错例复盘
检测实战这节最适合新人的理解顺序不是“先训模型”,而是先看清项目闭环:
flowchart LR A["定义类别和边界"] --> B["统一标注规范"] B --> C["先做 baseline"] C --> D["按 IoU / mAP 评估"] D --> E["分析漏检与误检"]所以这节真正想解决的是:
- 检测项目到底该怎么推进
- 哪些地方比模型结构更容易先出问题
一、一个检测项目最先要定什么?
Section titled “一、一个检测项目最先要定什么?”例如安防场景里你可能只先做:
- person
- helmet
而不是一开始就把所有目标都做进来。
必须先说清:
- 框紧不紧
- 遮挡怎么标
- 小目标怎么算
至少要明确:
- IoU 阈值
- 召回 / 精确率
新人第一次做检测项目,题目怎么选更稳?
Section titled “新人第一次做检测项目,题目怎么选更稳?”更稳的题目通常有这几个特点:
- 类别数不要太多
- 目标定义清楚
- 误检和漏检能肉眼看懂
所以第一次做项目时, “少类别、强定义、易解释”通常比“任务更炫”更重要。
这一步为什么比“先选模型”更重要?
Section titled “这一步为什么比“先选模型”更重要?”因为如果你最开始这些东西没定稳:
- 类别边界
- 标注规则
- 框口径
- IoU 阈值
后面你做再多模型比较,也可能是在混乱标准上空转。
二、先跑一个最小匹配评估示例
Section titled “二、先跑一个最小匹配评估示例”ground_truth = [ {"label": "person", "box": (10, 10, 30, 50)}, {"label": "helmet", "box": (14, 8, 24, 18)},]
predictions = [ {"label": "person", "box": (11, 12, 31, 48), "score": 0.92}, {"label": "helmet", "box": (15, 9, 23, 17), "score": 0.81}, {"label": "helmet", "box": (40, 40, 50, 50), "score": 0.30},]
def iou(box_a, box_b): ax1, ay1, ax2, ay2 = box_a bx1, by1, bx2, by2 = box_b
inter_x1 = max(ax1, bx1) inter_y1 = max(ay1, by1) inter_x2 = min(ax2, bx2) inter_y2 = min(ay2, by2)
inter_w = max(0, inter_x2 - inter_x1) inter_h = max(0, inter_y2 - inter_y1) inter_area = inter_w * inter_h
area_a = (ax2 - ax1) * (ay2 - ay1) area_b = (bx2 - bx1) * (by2 - by1) union = area_a + area_b - inter_area return inter_area / union if union else 0.0
matches = []for pred in predictions: best_iou = 0.0 best_gt = None for gt in ground_truth: if gt["label"] != pred["label"]: continue cur_iou = iou(pred["box"], gt["box"]) if cur_iou > best_iou: best_iou = cur_iou best_gt = gt matches.append( { "label": pred["label"], "score": pred["score"], "best_iou": round(best_iou, 4), "matched": best_iou >= 0.5, } )
print(matches)预期输出:
[{'label': 'person', 'score': 0.92, 'best_iou': 0.8182, 'matched': True}, {'label': 'helmet', 'score': 0.81, 'best_iou': 0.64, 'matched': True}, {'label': 'helmet', 'score': 0.3, 'best_iou': 0.0, 'matched': False}]按行理解这个输出:前两个预测都找到同类真实框,而且 IoU 超过 0.5;最后一个 helmet 预测没有匹配到真实 helmet 框,所以它是误检。
这段代码最重要的地方是什么?
Section titled “这段代码最重要的地方是什么?”它让你看到检测评估不是:
- 分类对了就行
而是:
- 类别对
- 框也要足够准
为什么这就是很多检测项目的核心判断?
Section titled “为什么这就是很多检测项目的核心判断?”因为真实检测结果好不好, 最终常常就体现在:
- 匹配阈值
- 框质量
为什么检测项目特别需要“误检 / 漏检”视角?
Section titled “为什么检测项目特别需要“误检 / 漏检”视角?”因为检测系统很少只有“对或错”两种结果。 更常见的是:
- 框偏了
- 目标漏了
- 多报了一个框
这也是为什么检测项目展示时,最好不要只放几张成功样例。
第一次做检测项目时,最值得先分哪几类错?
Section titled “第一次做检测项目时,最值得先分哪几类错?”一个很实用的错误分类方式是:
-
漏检 明明有目标,系统没报出来。
-
误检 没目标也报了。
-
定位不准 类别对了,但框偏差太大。
这三类一分开,你后面很多迭代方向就会立刻更清楚。
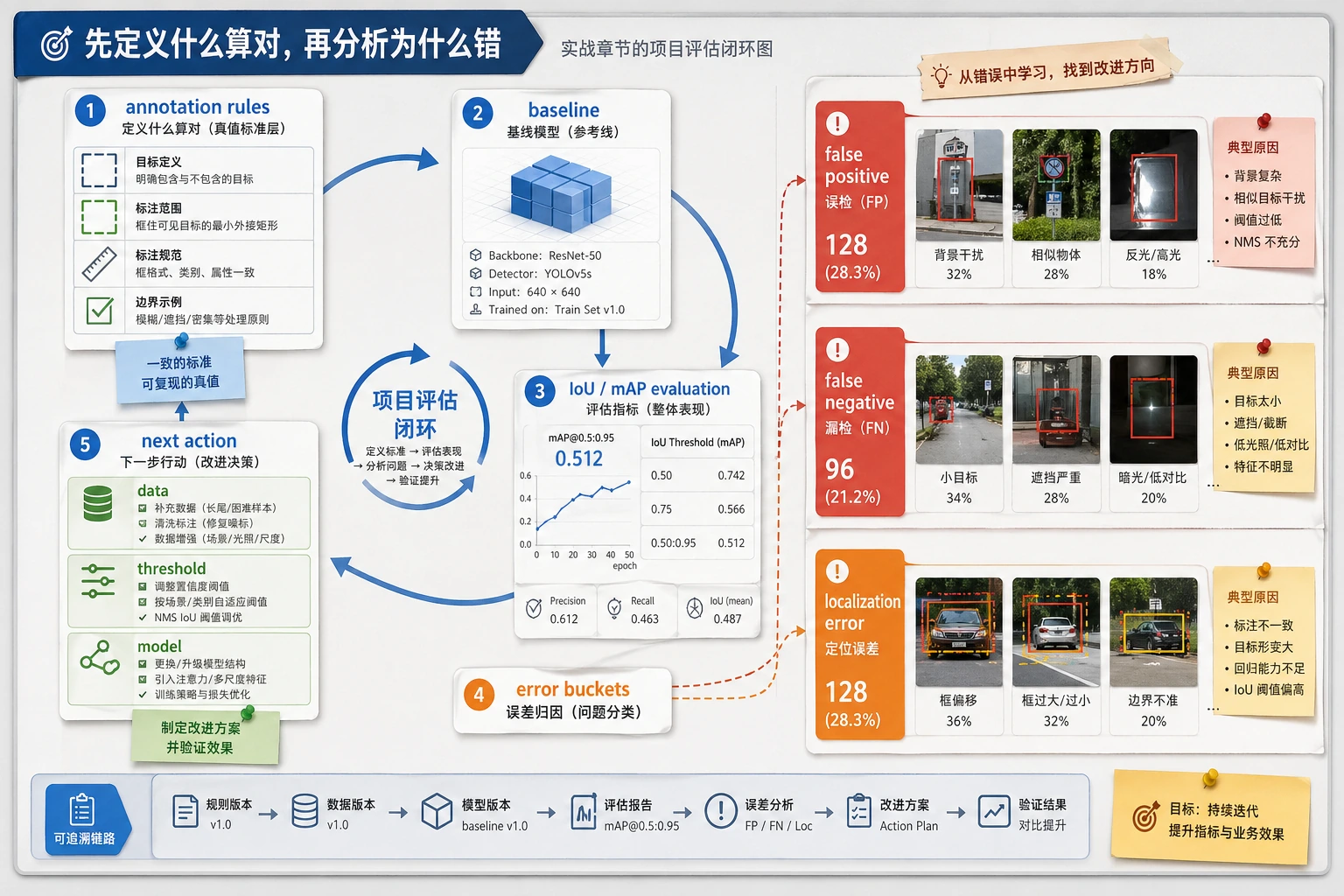
三、检测项目最容易踩的坑
Section titled “三、检测项目最容易踩的坑”标注标准不一致
Section titled “标注标准不一致”这会直接把训练和评估一起拖乱。
小目标和遮挡没单独分析
Section titled “小目标和遮挡没单独分析”很多系统在这些场景下会明显掉表现。
只展示一两张漂亮图
Section titled “只展示一两张漂亮图”真实项目更该展示:
- 哪些情况容易漏检
- 哪些情况容易误检
四、一个新人可直接照抄的推进顺序
Section titled “四、一个新人可直接照抄的推进顺序”更建议这样做:
- 先定类别和标注规则
- 再抽样检查标注质量
- 先做一个最小 baseline
- 再统一 IoU / mAP 评估口径
- 最后挑典型漏检 / 误检做分析
如果把它做成作品集,最值得展示什么?
Section titled “如果把它做成作品集,最值得展示什么?”比起只展示一张“预测效果图”,更值得展示的是:
- 类别定义和标注规则
- baseline 的 IoU / mAP
- 一组典型误检和漏检案例
- 你如何解释这些失败
- 下一步你会优先改数据、阈值还是模型
学完这一页,至少保留这张证据卡:
- 输入图像
- 带有真实或期望目标的检测样本
- 预测
- 框、标签、置信分数、IoU 和阈值设置
- 指标
- 精确率/召回率、mAP、误报和漏报
- 失败检查
- 小目标、重叠、NMS、标签差或置信度阈值问题
- 期望产出
- 带标注的图片,以及检测指标或错误分组
这节最重要的是建立一个项目意识:
检测项目的关键,不只是模型名,而是类别定义、标注规范和框级评估方法是否清楚。
这节最该带走什么
Section titled “这节最该带走什么”- 检测项目首先是标注和评估项目,其次才是模型项目
- IoU 阈值和标注口径会直接影响你怎么判断“检测对没对”
- 误检 / 漏检分析是检测项目最值得展示的部分之一
如果再压成一句话,那就是:
检测项目真正的难点,往往不是把模型跑起来,而是把“什么算检对了”这件事定义清楚。
- 调整 IoU 阈值到
0.7,看看匹配结果会怎么变。 - 想一想:为什么检测项目比分类项目更依赖清晰标注规范?
- 如果项目里总漏小目标,你会优先检查数据、输入分辨率还是模型结构?
- 你会如何把这个检测项目包装成作品集?
项目交付参考与讲解
- 把 IoU 阈值改成
0.7会让匹配更严格。原来在0.5下算 true positive 的框,可能变成 false positive 或 false negative。 - 检测非常依赖标注标准,因为框本身就是标签的一部分。框规则的小差异就会改变 IoU 和 mAP。
- 如果项目反复漏检小目标,先查数据、标注质量和输入分辨率。目标缺失、标错或被缩放到太小,换模型也解决不了根因。
- 作品集版本应包含类别定义、标注样例、baseline 指标、典型误检/漏检案例,以及清晰的下一步改进计划。