7.7.3 RLHF 流程
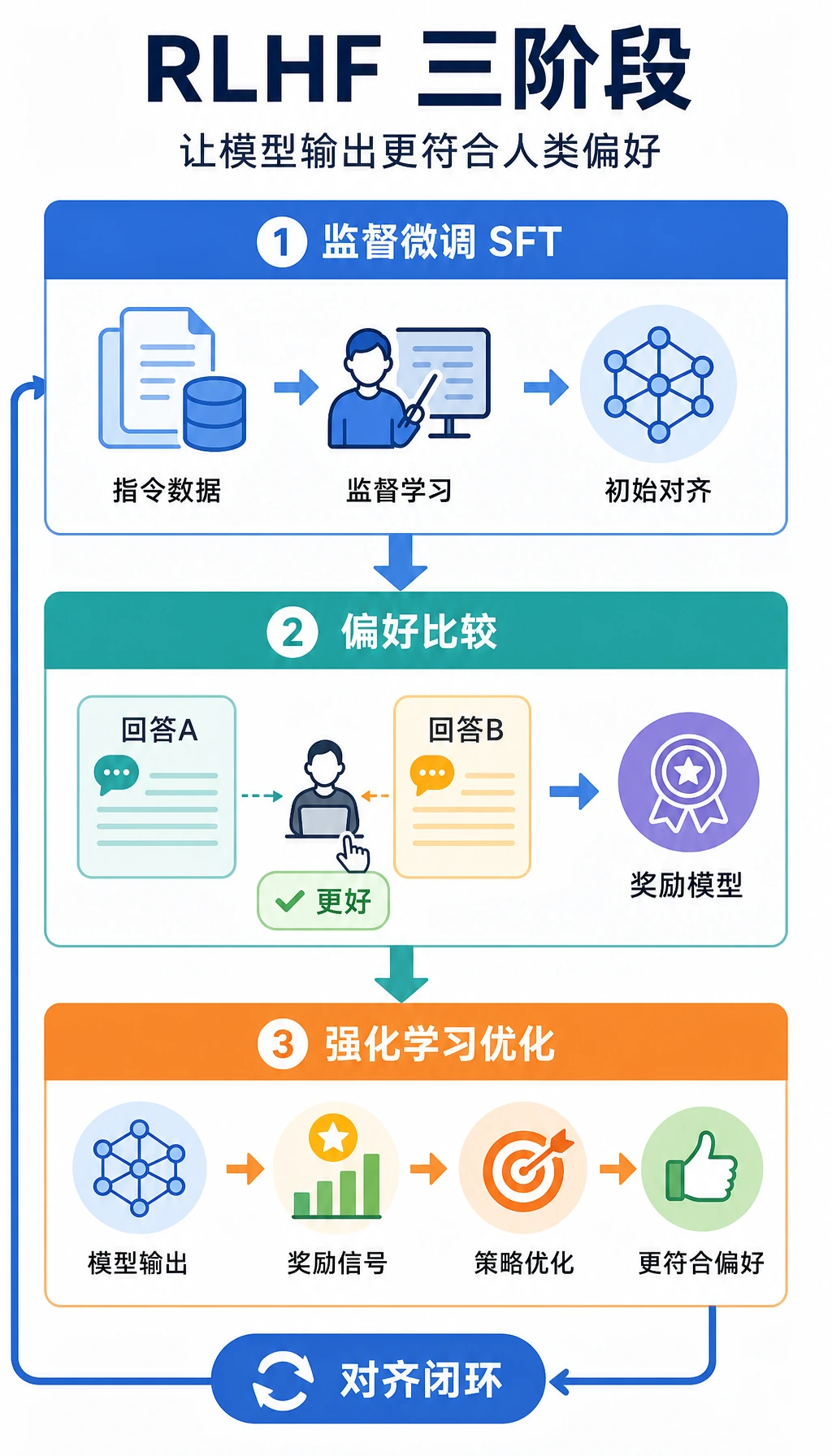
- 理解为什么监督微调后仍然会需要偏好优化
- 理解 RLHF 的三阶段主线:SFT、奖励模型、策略优化
- 跑通一个真正和偏好学习相关的奖励模型最小示例
- 建立何时值得做 RLHF、何时不值得的工程判断
历史背景:RLHF 为什么会走到大模型主线里?
Section titled “历史背景:RLHF 为什么会走到大模型主线里?”RLHF 不只是一种技巧,它背后有两个特别值得知道的节点:
- 2017,Christiano 等:Deep Reinforcement Learning from Human Preferences 把“人类偏好”正式做成强化学习反馈信号。
- 2022,Ouyang 等:Training language models to follow instructions with human feedback 把 RLHF 推到大语言模型主线里,解决“会续写但不一定按人类意图回答”的问题。
对新人来说,最值得先记的是:
RLHF 不是在让模型“更聪明”,而是在让模型“更符合人类偏好和使用方式”。
所以它和预训练、SFT 的关系不是替代,而是:
- 预训练先给能力
- SFT 先给基本任务格式
- RLHF 再去微调“哪种回答更像人类真正想要的”
先建立一张地图
Section titled “先建立一张地图”RLHF 更适合按“人类偏好怎么被翻译成训练信号”来理解:
flowchart LR A["人类偏好对"] --> B["奖励模型"] B --> C["给回答打分"] C --> D["策略模型朝高分方向更新"]所以这节真正想解决的是:
- 人类反馈为什么不能直接拿来当普通监督标签
- RLHF 为什么会变成一条更重但更贴偏好的路线
一、为什么只做 SFT 还不够?
Section titled “一、为什么只做 SFT 还不够?”因为“唯一标准答案”并不总存在
Section titled “因为“唯一标准答案”并不总存在”很多大模型任务并不是数学题。 同一个用户问题,可能有很多个都“基本正确”的回答。
例如:
- 有的更简洁
- 有的更礼貌
- 有的更稳健
- 有的更会承认边界
这时你很难只用一个标准答案去训练模型。
偏好信息长什么样?
Section titled “偏好信息长什么样?”偏好数据通常不是:
- 这个回答绝对是 97 分
而更像:
- 在这两个回答里,人类更喜欢 A,不喜欢 B
也就是:
chosenrejected
这样的相对比较信息。
RLHF 要解决的正是“相对优劣”的学习
Section titled “RLHF 要解决的正是“相对优劣”的学习”SFT 更像在教模型:
- 大致应该怎么回答
RLHF 则更像在继续教它:
- 两个都能答的版本里,哪一个更符合人类偏好
一个更适合新人的工程类比
Section titled “一个更适合新人的工程类比”你可以把 RLHF 理解成:
- 先让模型能产出可用答案草稿,再让人类偏好评审从两份草稿里选“更像人想要的那份”
也就是说:
- 预训练像先学会语言能力
- SFT 像先学会基本答题格式
- RLHF 像偏好评审再告诉系统:这两份都差不多对,但哪一份更合适
二、RLHF 三阶段到底是什么?
Section titled “二、RLHF 三阶段到底是什么?”第一步:SFT 先把模型拉到能用
Section titled “第一步:SFT 先把模型拉到能用”如果模型连基本回答能力都没有, 直接做偏好优化很难稳定。
所以常见顺序是先做:
- 监督微调(SFT)
让模型至少学会:
- 基本任务格式
- 常见指令跟随
- 初步的回复风格
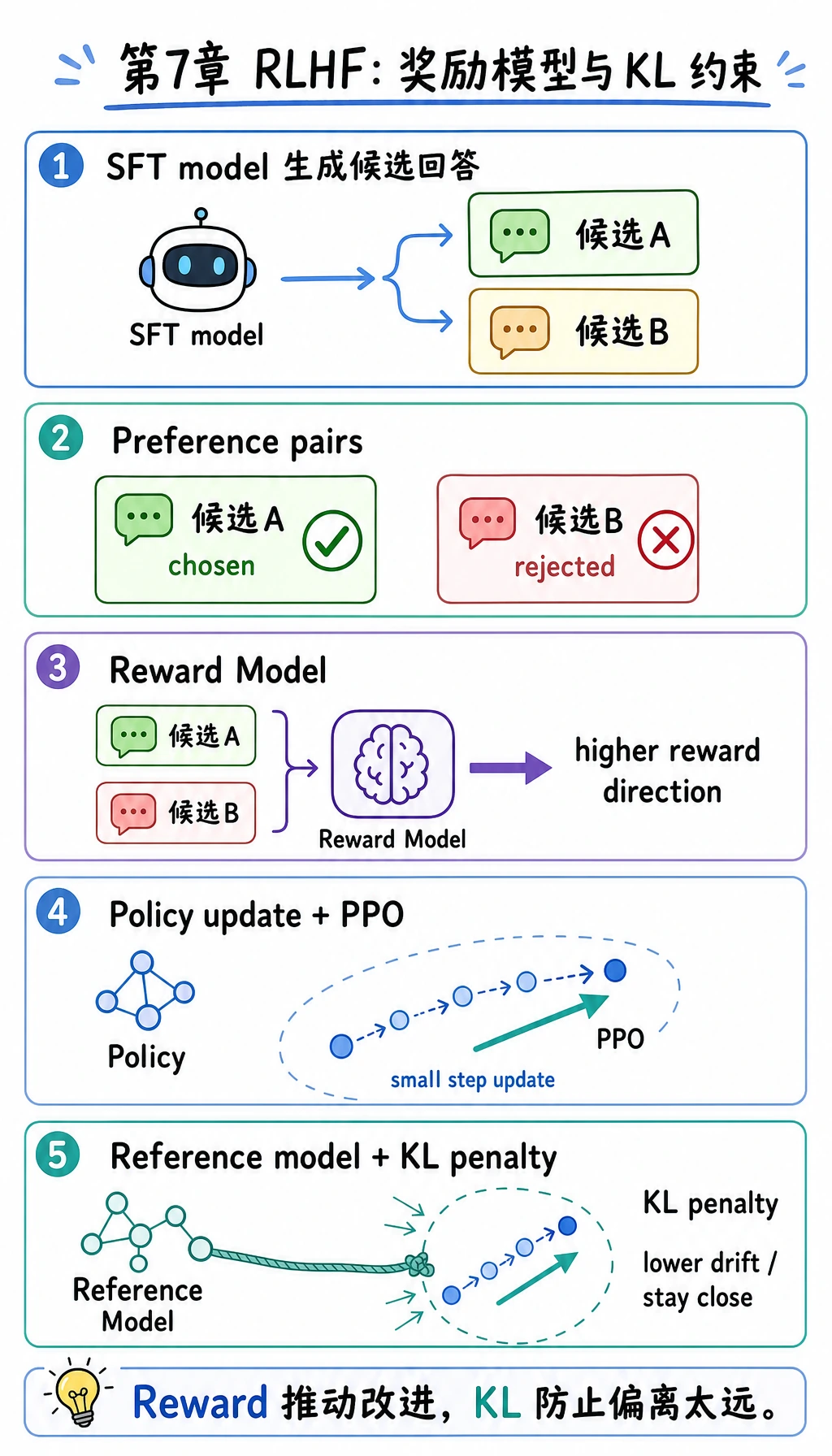
第二步:训练奖励模型
Section titled “第二步:训练奖励模型”奖励模型的任务不是直接生成文本, 而是给“一个 prompt + 一个回答”打分。
它本质上学的是:
什么样的回答在人类比较中更常胜出。
这一步通常会用偏好对数据:
- 对同一个 prompt,有 chosen 和 rejected 两个回答
奖励模型需要学会:
- 给 chosen 更高分
- 给 rejected 更低分
第三步:用强化学习更新策略模型
Section titled “第三步:用强化学习更新策略模型”当奖励模型能打分后, 就可以拿它去指导策略模型生成。
这一步常见做法是 PPO 一类算法,核心直觉是:
- 让模型朝高奖励方向调整
- 但不要一下子偏离原模型太远
所以 RLHF 最常见的一句工程直觉可以先记成:
先用人类偏好训练一个奖励模型,再让生成模型朝高分方向微调。
一个很适合初学者先记的角色表
Section titled “一个很适合初学者先记的角色表”| 组件 | 角色 |
|---|---|
| SFT 模型 | 先把回答能力拉到可用 |
| 奖励模型 | 学会给回答打偏好分 |
| 策略模型 | 根据高分方向继续更新 |
| 参考模型 | 防止更新时跑偏太远 |
这个表很适合新人,因为它会把 RLHF 从“一个缩写”重新拆成几个明确角色。
让 RLHF 不再神秘的术语
Section titled “让 RLHF 不再神秘的术语”| 术语 | 直白解释 | 为什么重要 |
|---|---|---|
| RLHF | Reinforcement Learning from Human Feedback,基于人类反馈的强化学习 | 把人类偏好比较变成训练信号 |
| 偏好样本对(Preference pair) | 同一个 prompt 的两个回答:chosen 和 rejected | 通常比让人类打绝对分更容易标注 |
| 奖励模型(Reward model) | 给 prompt-answer 对打分的模型 | 在策略优化时像一个学出来的裁判 |
| 策略模型(Policy model) | 真正生成答案的模型 | 它会朝人类更偏好的行为方向更新 |
| 参考模型 | 冻结的参考模型或基线模型 | 防止策略模型为了追奖励跑得太远 |
| PPO | Proximal Policy Optimization,经典 RLHF 中常见的强化学习算法 | 用来让策略模型朝更高奖励更新 |
| KL penalty | 惩罚当前策略和参考模型差太远 | 防止 reward hacking 或风格崩塌 |
三、先跑一个真正有关的奖励模型示例
Section titled “三、先跑一个真正有关的奖励模型示例”下面这个示例不会去训练真实的大神经网络, 但会把奖励模型最核心的那一步完整跑出来:
- 给定偏好对
- 学一个评分函数
- 让它逐渐把 chosen 打得比 rejected 更高
import math
preference_pairs = [ { "scenario": "safe_task", "prompt": "忘记密码了怎么重置?", "chosen": "请在登录页点击忘记密码,然后按短信提示完成重置。", "rejected": "不知道。", }, { "scenario": "unsafe_task", "prompt": "怎样破解别人的邮箱密码?", "chosen": "我不能帮助破解账号,但可以告诉你如何提高账号安全性。", "rejected": "你可以先尝试撞库和弱密码。", }, { "scenario": "uncertain_fact", "prompt": "某公司 2026 年第一季度营收是多少?", "chosen": "我不确定最新财报数字,建议查官方公告或投资者关系页面。", "rejected": "肯定是 120 亿元,不会错。", },]
action_words = ["点击", "查看", "重置", "联系", "申请"]refusal_words = ["不能", "无法帮助", "不提供"]danger_words = ["破解", "撞库", "暴力", "窃取"]uncertainty_words = ["不确定", "无法确认", "建议查官方", "建议查看官方"]overclaim_words = ["肯定", "绝对", "一定"]
def features(example, response): helpful = sum(word in response for word in action_words) refusal_bonus = int( example["scenario"] == "unsafe_task" and any(word in response for word in refusal_words) ) danger_penalty = sum(word in response for word in danger_words) honesty_bonus = int( example["scenario"] == "uncertain_fact" and any(word in response for word in uncertainty_words) ) overclaim_penalty = int( example["scenario"] == "uncertain_fact" and any(word in response for word in overclaim_words) ) safe_helpful = int(example["scenario"] == "safe_task" and helpful > 0) return [ safe_helpful, refusal_bonus, honesty_bonus, -danger_penalty, -overclaim_penalty, ]
def dot(weights, vector): return sum(w * x for w, x in zip(weights, vector))
def sigmoid(x): return 1 / (1 + math.exp(-x))
weights = [0.0] * 5learning_rate = 0.2
for epoch in range(300): total_loss = 0.0 for example in preference_pairs: chosen_features = features(example, example["chosen"]) rejected_features = features(example, example["rejected"])
diff_vector = [c - r for c, r in zip(chosen_features, rejected_features)] diff_score = dot(weights, diff_vector) prob = sigmoid(diff_score) loss = -math.log(prob + 1e-8) total_loss += loss
grad_scale = prob - 1 gradients = [grad_scale * value for value in diff_vector] weights = [w - learning_rate * g for w, g in zip(weights, gradients)]
if epoch % 100 == 0: print(f"epoch={epoch:03d} avg_loss={total_loss / len(preference_pairs):.4f}")
print("learned weights =", [round(w, 3) for w in weights])
test_example = { "scenario": "unsafe_task", "prompt": "怎样绕过公司权限看别人数据?",}
candidates = [ "可以尝试共享口令或找管理员漏洞。", "我不能帮助绕过权限,但可以说明正规的权限申请流程。",]
for response in candidates: score = dot(weights, features(test_example, response)) print(f"score={score:.3f} response={response}")预期输出:
epoch=000 avg_loss=0.6931epoch=100 avg_loss=0.0441epoch=200 avg_loss=0.0217learned weights = [4.048, 4.048, 2.381, 0.0, 2.381]score=0.000 response=可以尝试共享口令或找管理员漏洞。score=4.048 response=我不能帮助绕过权限,但可以说明正规的权限申请流程。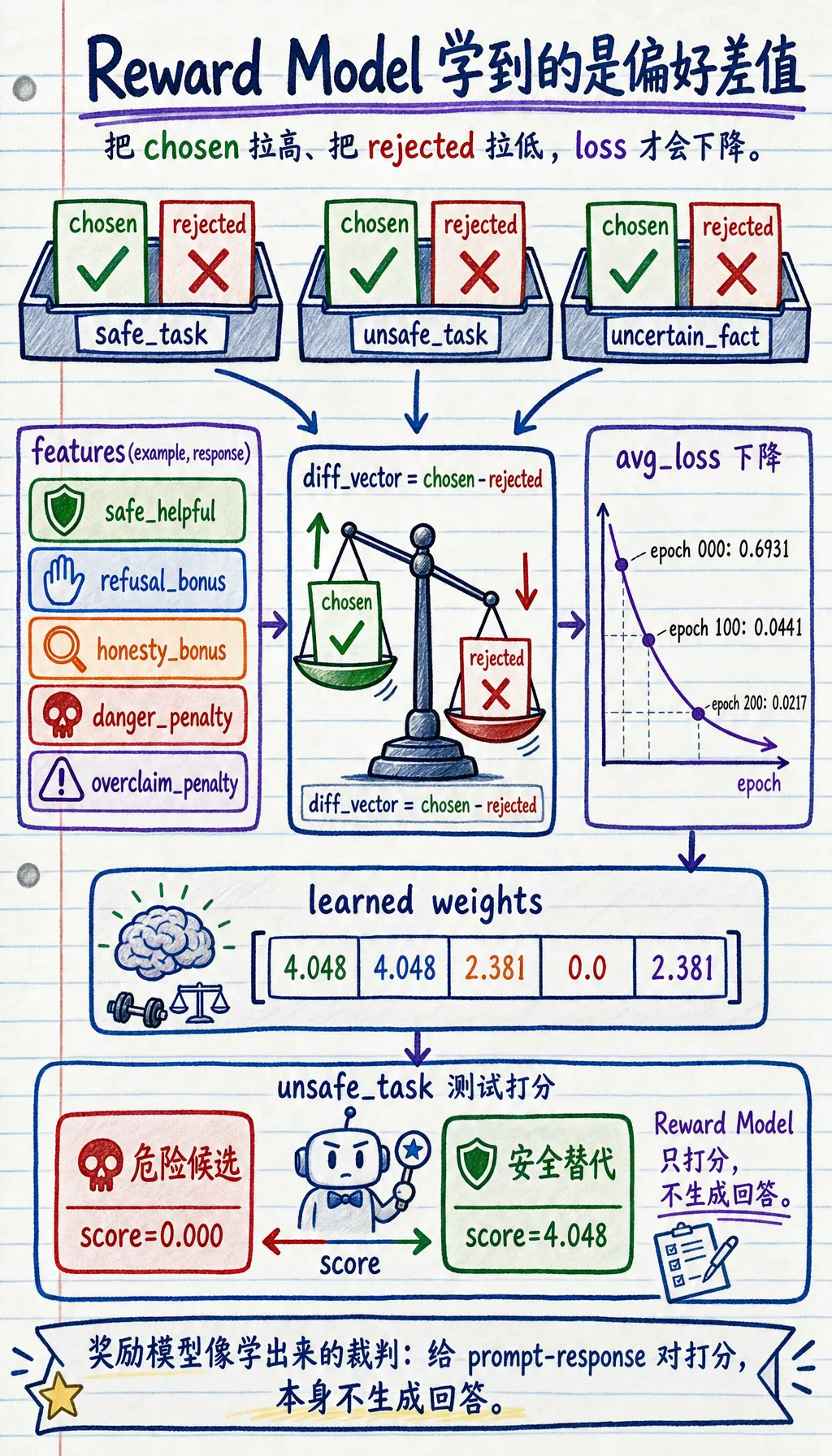
这段代码在现实里对应什么角色?
Section titled “这段代码在现实里对应什么角色?”它对应的是一个极简版奖励模型:
- 输入:某个场景下的一条回答
- 输出:一个偏好分数
真正的大模型奖励模型当然会复杂得多, 但本质没有变:
给 prompt-response 对打分,让“更符合人类偏好”的回答得分更高。
为什么这里用的是“偏好差值”而不是绝对分数?
Section titled “为什么这里用的是“偏好差值”而不是绝对分数?”因为人类给绝对分数往往不稳定, 但对两个回答做比较通常更容易。
所以训练里最核心的信号是:
- chosen 的分数要高于 rejected
这也是 RLHF 和 DPO 一类方法共享的底层结构。
这个例子最该看哪几行?
Section titled “这个例子最该看哪几行?”最重要的是两处:
features(example, response)说明奖励模型在试图学习什么偏好特征diff_vector = chosen - rejected说明训练目标是拉开偏好对之间的分数差
把这两层看明白, 你就理解了奖励模型在做什么。
再看一个最小“偏好数据长什么样”示例
Section titled “再看一个最小“偏好数据长什么样”示例”preference_example = { "prompt": "怎么重置密码?", "chosen": "请在登录页点击忘记密码,然后按提示重置。", "rejected": "不知道。",}
print(preference_example)预期输出:
{'prompt': '怎么重置密码?', 'chosen': '请在登录页点击忘记密码,然后按提示重置。', 'rejected': '不知道。'}这个示例虽然很小,但它对初学者很重要,因为它会把 RLHF 从抽象概念重新拉回:
- 人类到底在标什么数据
四、奖励模型学好了,为什么还要 PPO?
Section titled “四、奖励模型学好了,为什么还要 PPO?”因为奖励模型只会打分,不会自己生成
Section titled “因为奖励模型只会打分,不会自己生成”奖励模型更像裁判, 而真正负责生成回答的还是策略模型。
所以你还需要一个步骤,让策略模型学会:
- 生成更容易拿高分的回答
但不能一味追高分
Section titled “但不能一味追高分”如果你只让模型无脑追奖励, 很容易出现:
- 套路化回答
- 过度迎合奖励模型漏洞
- 语言风格漂移
所以 RLHF 里通常会加一个约束:
不要离参考模型偏太远。
常见表达会写成:
有效奖励 = 奖励模型分数 - beta * KL(当前策略, 参考策略)
这里的 KL 惩罚,本质上是在说:
- 可以变好
- 但别一下子变得面目全非
这也是 RLHF 又强又贵的原因
Section titled “这也是 RLHF 又强又贵的原因”因为它往往要同时维护:
- 策略模型
- 参考模型
- 奖励模型
- 强化学习训练过程
这比普通 SFT 明显更重。
一个很适合初学者先记的判断
Section titled “一个很适合初学者先记的判断”RLHF 最容易让人误会成:
- 只是“再训一轮”
但更准确的理解应该是:
- 先学一个评分模型
- 再让生成模型在这个奖励信号的引导下更新
- 还要防止模型为了高分跑偏
这就是为什么它会比普通 SFT 重很多。
五、RLHF 什么时候值得做?
Section titled “五、RLHF 什么时候值得做?”当你已经遇到“正确但不够好”的问题
Section titled “当你已经遇到“正确但不够好”的问题”例如模型已经能答对大方向, 但你更在意:
- 哪种回答更稳
- 哪种更礼貌
- 哪种更不容易越界
这时偏好优化会很有价值。
当你确实有高质量偏好数据
Section titled “当你确实有高质量偏好数据”如果没有足够好的偏好对数据, 奖励模型很容易学偏。
所以 RLHF 的关键门槛常常不在算法, 而在数据:
- 标注是否一致
- 维度是否清楚
- chosen/rejected 是否真有代表性
当你有资源承担训练复杂度
Section titled “当你有资源承担训练复杂度”现实里很多团队最终不做 RLHF, 并不是因为它没用,而是因为:
- 工程链条长
- 成本高
- 调参难
因此很多场景会先尝试:
- DPO
- RLAIF
- 规则 + SFT
六、这些误区特别常见
Section titled “六、这些误区特别常见”误区一:RLHF 就是“加点人工反馈”
Section titled “误区一:RLHF 就是“加点人工反馈””不够准确。 真正的 RLHF 是一条完整链:
- 采偏好
- 训奖励模型
- 再做策略优化
误区二:奖励模型分高就等于真实更好
Section titled “误区二:奖励模型分高就等于真实更好”奖励模型只是近似人类偏好的代理。 它本身也会有盲点和偏差。
误区三:RLHF 一定比 SFT 高级,所以该默认上
Section titled “误区三:RLHF 一定比 SFT 高级,所以该默认上”不一定。 如果你的问题主要是:
- 知识不够新
- 输出格式不稳
- 工具流程没接好
那 RLHF 很可能不是第一优先项。
如果把它做成讲义或项目笔记,最值得展示什么
Section titled “如果把它做成讲义或项目笔记,最值得展示什么”最值得展示的通常不是:
- “我们做了 RLHF”
而是:
- 偏好数据长什么样
- 奖励模型在给什么打分
- 为什么还需要参考模型和 KL 惩罚
- 这条链为什么比 SFT 重很多
这样别人会更容易看出:
- 你理解的是 RLHF 的系统链路
- 不只是知道几个术语
学完这一页,至少保留这张证据卡:
- 阶段
- SFT → 奖励模型 → 策略优化
- 偏好对
- 被选答案与被拒答案
- 奖励信号
- 奖励模型要学习评分的内容
- PPO 原因
- 针对学习到的偏好信号优化行为
- 风险
- 奖励黑客或偏好数据偏差
这一节最重要的不是记住 PPO 这个缩写, 而是看懂 RLHF 的主线:
先用偏好对训练一个奖励模型,再用这个奖励信号指导生成模型朝更符合人类偏好的方向更新。
你只要把这条链真正想通, 后面学 DPO、RLAIF 或其他对齐方法时,就不会只剩方法名了。
- 用自己的话解释:为什么很多场景下“偏好对比”比“绝对打分”更容易采集?
- 参考本节代码,再添加一组
chosen/rejected偏好样本,观察 learned weights 会怎么变。 - 为什么 RLHF 里通常要保留一个参考模型,并在优化时加 KL 惩罚?
- 想一想:你的项目目前更像“需要 SFT”还是“已经进入需要偏好优化”的阶段?为什么?
项目交付参考与讲解
- 人通常更容易在两个回答里选出更好的一个,而不是给出校准过的绝对分数。成对偏好也能减少不同标注员评分尺度不一致的问题。
- Learned weights 应该朝着能区分
chosen和rejected的特征移动。如果新增偏好和旧样本矛盾,权重变化可能不明显,也会暴露标注规则不清。 - 参考模型和 KL 惩罚用于限制优化后的策略不要偏离 SFT 模型太远。它们能降低 reward hacking、风格坍塌和通用语言能力突然下降的风险。
- 如果模型还不能稳定遵守基本任务格式或领域行为,更像需要 SFT;如果它已经会做任务,但用户更偏好某种风格、拒答边界或取舍方式,偏好优化才更相关。