6.1.2 过渡:从经典机器学习到深度学习
- 看清第 5 站和第 6 站到底是“断开”还是“递进”
- 理解为什么传统 ML 后面还需要学神经网络
- 看懂神经网络和传统模型在“数据、损失、优化、评估”上的共同骨架
- 为后面的神经元、反向传播、PyTorch 训练循环建立心智桥梁
先建立一张地图
Section titled “先建立一张地图”很多新人学完第 5 站会有两个典型疑问:
- 既然线性回归、逻辑回归、树模型已经能做很多事,为什么还要学深度学习?
- 到了第 6 站,为什么一下子多了层、梯度、反向传播、PyTorch 这些新东西?
更稳的理解方式是先看这条演进线:
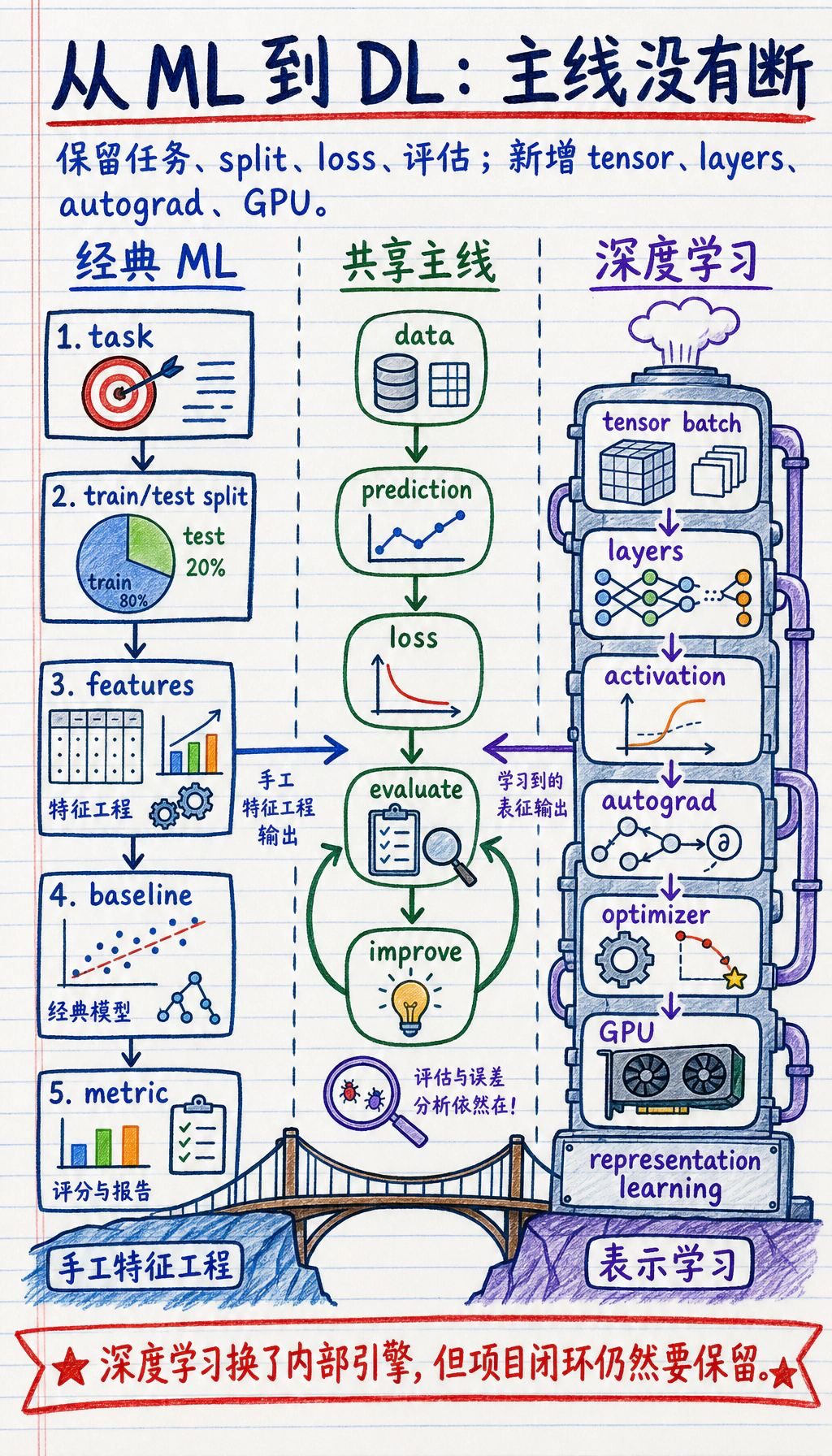
所以第 6 站不是推翻第 5 站,而是在第 5 站已经建立的建模思维上继续往前走。
一、第 5 站到底已经学会了什么
Section titled “一、第 5 站到底已经学会了什么”第 5 站真正教会你的,不只是几个模型名,而是下面这条建模主线:
- 先判断任务类型
- 先立 baseline
- 再选指标
- 再做改进
- 最后做错误分析和复盘
这些东西到了第 6 站并不会消失。
第 6 站真正新增的,不是“有没有评估”
Section titled “第 6 站真正新增的,不是“有没有评估””很多人会误以为到了深度学习就是另一套逻辑。 其实不是。第 6 站仍然会做这些事:
- 还是要切训练集和验证集
- 还是要看 loss 和指标
- 还是要防过拟合
- 还是要做错误分析
真正新增的,是模型表示能力和训练方式。
二、为什么传统 ML 后面还要学神经网络
Section titled “二、为什么传统 ML 后面还要学神经网络”经典机器学习很强,但它也有一些很自然的边界。
传统 ML 更依赖“手工表示”
Section titled “传统 ML 更依赖“手工表示””在第 5 站你已经反复做过这些事:
- 手工构造特征
- 做编码、缩放、筛选
- 想办法把问题整理成模型更容易学的形式
这件事非常重要,但也会带来一个限制:
- 模型的上限,很多时候会被你的特征设计能力卡住
深度学习更强调“自动学表示”
Section titled “深度学习更强调“自动学表示””深度学习最强的一点,可以先朴素地理解成:
不只是学“怎么预测”,还在学“该怎么表示输入”。
比如:
- 图像里,CNN 会自己学边缘、纹理、局部模式
- 文本里,神经网络会自己学词向量、上下文表示
- 序列里,模型会自己学时间依赖或注意力关系
这就是第 6 站真正补上的能力。
一个简单对照
Section titled “一个简单对照”| 问题 | 第 5 站更常见做法 | 第 6 站更常见做法 |
|---|---|---|
| 图像分类 | 先手工提特征,再喂分类器 | 直接让 CNN 学特征 |
| 文本分类 | TF-IDF / 手工统计特征 | 让网络学 embedding 和上下文 |
| 复杂非线性关系 | 试树模型、集成学习 | 让多层网络直接表达复杂函数 |
这不是说第 6 站一定“取代”第 5 站,而是:
- 数据简单、样本不大、表格任务强时,第 5 站的方法仍然非常有价值
- 数据复杂、非结构化、特征难手造时,第 6 站的方法优势会越来越明显
三、第 5 站和第 6 站的共同骨架其实没变
Section titled “三、第 5 站和第 6 站的共同骨架其实没变”看起来第 6 站新词很多,但训练一轮模型的骨架,其实和第 5 站仍然是一条线:
flowchart LR A["输入数据 X"] --> B["模型给出预测 y_hat"] B --> C["计算损失 loss"] C --> D["根据 loss 更新参数"] D --> E["在验证集上看效果"]
style A fill:#e3f2fd,stroke:#1565c0,color:#333 style E fill:#e8f5e9,stroke:#2e7d32,color:#333你可以把它和第 5 站对应起来:
| 第 5 站 | 第 6 站 |
|---|---|
| 线性模型 / 树模型 | 神经网络 |
| 指标和损失 | 指标和损失 |
fit() 背后完成训练 | 你会更显式地看到训练循环 |
| 调参与评估 | 调参与评估 |
所以第 6 站变化最大的地方不是“有没有训练”,而是:
- 你开始更直观地看到训练过程是怎么一步步发生的
四、第 6 站为什么会突然强调梯度和反向传播
Section titled “四、第 6 站为什么会突然强调梯度和反向传播”第 5 站里,很多模型训练细节是被库包起来的。 到了第 6 站,你会开始更直接面对:
- 参数很多
- 模型很多层
- 需要一轮轮更新
这时候就必须真正理解:
- 损失是怎么来的
- 梯度在表达什么
- 参数为什么会更新
可以先把反向传播理解成一句人话
Section titled “可以先把反向传播理解成一句人话”先不要急着背推导,先记住这句:
前向传播负责“算结果”,反向传播负责“算每个参数该怎么改”。
这句话是第 6 站一整章的核心。
第 5 站的优化思路其实已经埋下伏笔
Section titled “第 5 站的优化思路其实已经埋下伏笔”你在第 5 站已经见过:
- 线性回归的损失
- 梯度下降
- 正则化
- 交叉验证和过拟合
所以第 6 站不是从零开始,而是把这些东西变得更显式:
- 模型更深
- 参数更多
- 训练循环更清楚
五、为什么第 6 站会引入 PyTorch
Section titled “五、为什么第 6 站会引入 PyTorch”第 5 站里,scikit-learn 很适合新人,因为它把流程统一封装好了。
但到了深度学习,你会更需要:
- 自定义网络结构
- 自己控制前向和反向
- 更灵活地组织训练循环
- 和 GPU、更大模型、更复杂数据配合
这就是 PyTorch 进场的原因。
先把 sklearn 和 PyTorch 的角色分清
Section titled “先把 sklearn 和 PyTorch 的角色分清”| 工具 | 更擅长什么 |
|---|---|
scikit-learn | 经典 ML、统一接口、快速 baseline |
PyTorch | 深度学习、灵活定义网络、显式训练循环 |
所以不要把它们理解成“谁替代谁”,而应该理解成:
- 第 5 站先用
sklearn建立机器学习工作流 - 第 6 站再用
PyTorch打开深度学习训练过程
一句最重要的桥接理解
Section titled “一句最重要的桥接理解”如果你已经理解了第 5 站里的:
- 数据
- 模型
- 损失
- 评估
那第 6 站你只是在多学一件事:
如何更显式地控制“模型参数是怎么被更新出来的”。
六、进入第 6 站前,最推荐先记住哪几件事
Section titled “六、进入第 6 站前,最推荐先记住哪几件事”- 第 6 站不是推翻第 5 站,而是建立在第 5 站之上
- 深度学习最大的新增能力,是自动学表示
- 第 5 站和第 6 站的训练骨架其实是一样的
PyTorch不是为了更难,而是为了让训练过程更可控
七、进入第 6 站后,最稳的学习顺序
Section titled “七、进入第 6 站后,最稳的学习顺序”如果你刚从第 5 站过来,建议按这个顺序走:
-
先读 6.1.1 学前导读:神经网络基础这一章到底在学什么 先把神经元、前向、反向、优化器这些词的位置放对。
-
再读 6.1.3 从神经元到多层感知机 先理解“一个神经元到底在做什么”。
-
然后进 6.2.1 学前导读:PyTorch 这一章到底在学什么 再把训练流程用
Tensor / Autograd / Module / DataLoader / Training Loop串起来。
这样会比一上来直接冲复杂网络结构更稳。
这节最该带走什么
Section titled “这节最该带走什么”如果只带走一句话,我希望你记住:
第 6 站不是“另一门课”,而是第 5 站那条建模主线在更强表达能力和更显式训练过程上的自然延伸。
所以最重要的收获应该是:
- 知道为什么传统 ML 后面还需要深度学习
- 知道深度学习真正新增的能力是什么
- 知道为什么会出现反向传播和 PyTorch
- 知道第 5 站和第 6 站其实仍然共享一套建模骨架
继续学习前,写一条五行桥接笔记:
- 已有技能
- 我可以训练和评估 sklearn 模型。
- 相同骨架
- 数据 → 模型 → 损失/指标 → 改进 → 错误分析。
- 新能力
- 神经网络学习表征,而不只是最终预测规则。
- 新控制
- PyTorch 提供 forward、backward、optimizer、device 和 checkpoint 逻辑。
- 下一步动作
- 运行一个很小的神经网络,并解释 loss 为什么变化。
如果这条笔记说得清楚,第 6 章就会像原有建模流程的扩展,而不是重新开始。
读完这页后,你的输出是一套心智模型,而不是一个 Python 文件:
I can explain what stays the same from sklearn to PyTorch.I can explain what becomes more explicit in PyTorch.I can point to one reason representation learning matters.I can describe why Chapter 6 prepares me for Transformer and LLMs.如果这四句话还说不出来,先回看这座桥,再进入 CNN、RNN 或 Transformer 架构名词。
复盘要点与通过标准
- 合格的桥接笔记应该保留第 5 站的同一套骨架:数据、模型、损失或指标、改进、错误分析。
- 然后说清楚第 6 站哪些东西变得更显式:forward、backward、optimizer step、device 选择和 checkpoint。
- 跑一次或阅读一个很小的神经网络,并指出“表征学习”发生在哪一行。如果只说“模型更深了”,区别还不够清楚。
- 当你能在选工具前判断一个问题更需要 sklearn 的简单性,还是 PyTorch 的控制力时,本页就算通过。