6.8.5 实操工作坊:构建 PyTorch 训练证据包
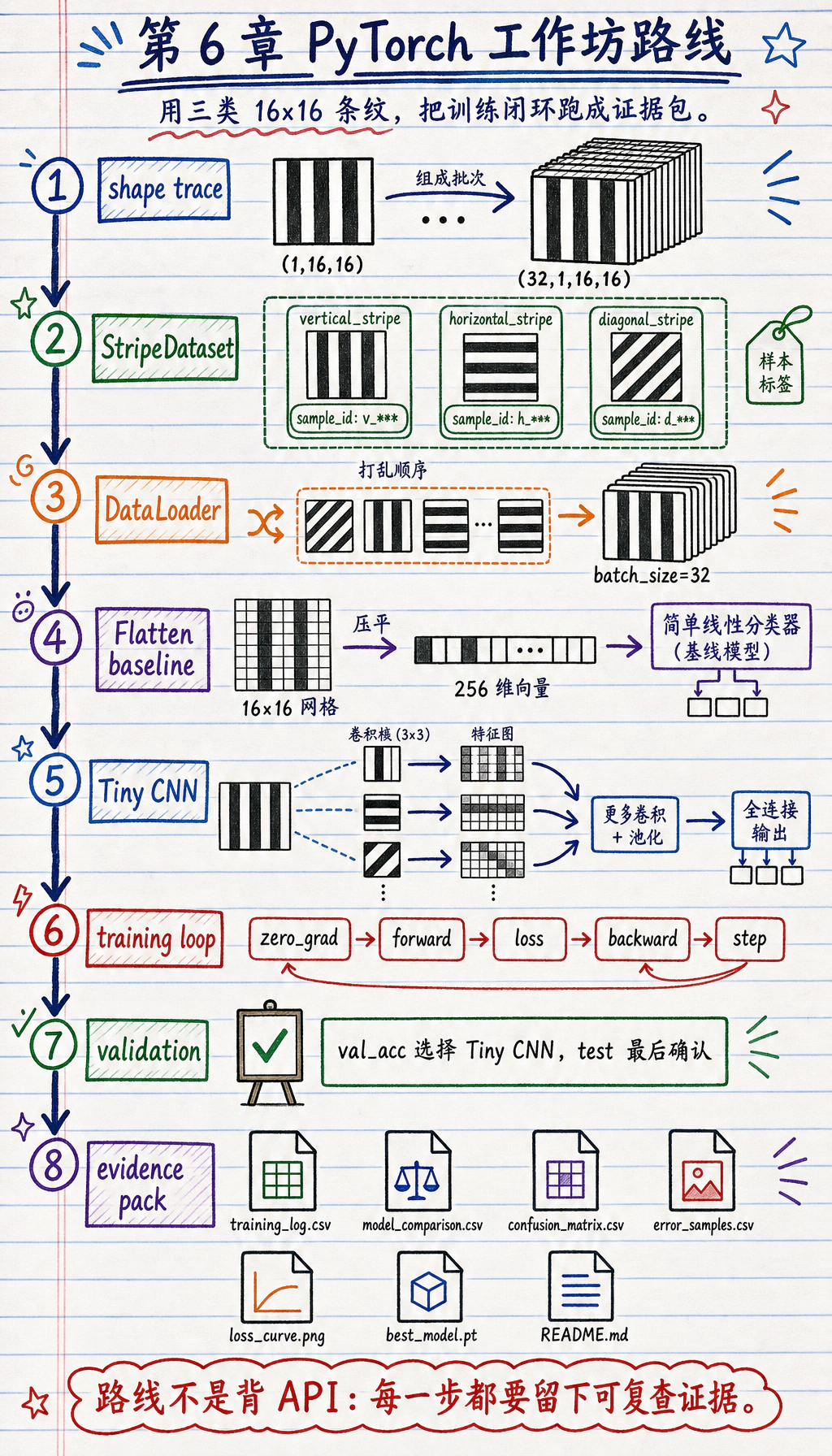
- 本地生成一个不需要下载的小图像分类数据集
- 比较简单的
Flatten + Linearbaseline 和一个小 CNN - 正确使用
Dataset、DataLoader、nn.Module、loss、optimizer 和 validation - 保存训练日志、模型对比、混淆矩阵、复盘样本、loss 曲线和 checkpoint
- 解释深度学习常见失败:shape 不匹配、loss 不下降、过拟合和显存/内存压力
你要构建什么
Section titled “你要构建什么”这个工作坊会创建一个本地文件夹:deep_learning_workshop_run/。
任务是:
把 16x16 的合成灰度小图像分成 vertical stripe、horizontal stripe 和 diagonal stripe 三类。
数据由代码生成。这样可以保证 CPU 也能运行,不需要下载数据集,同时仍然能练到真实图像和文本项目里会反复使用的工程习惯。
| 第 6 章知识点 | 在项目里要做什么 |
|---|---|
| 张量形状 | 训练前追踪 (batch, channel, height, width) |
| Dataset | 用自定义 Dataset 包装图像、标签和 sample id |
| DataLoader | 对训练数据做 batch 和 shuffle |
| 基线 | 先训练 Flatten + Linear 模型 |
| CNN | 训练一个小型卷积网络 |
| 训练循环 | 跑 zero_grad -> forward -> loss -> backward -> step |
| 验证 | 用验证准确率选择最佳模型 |
| 证据 | 保存日志、曲线、错误、checkpoint 和 README |
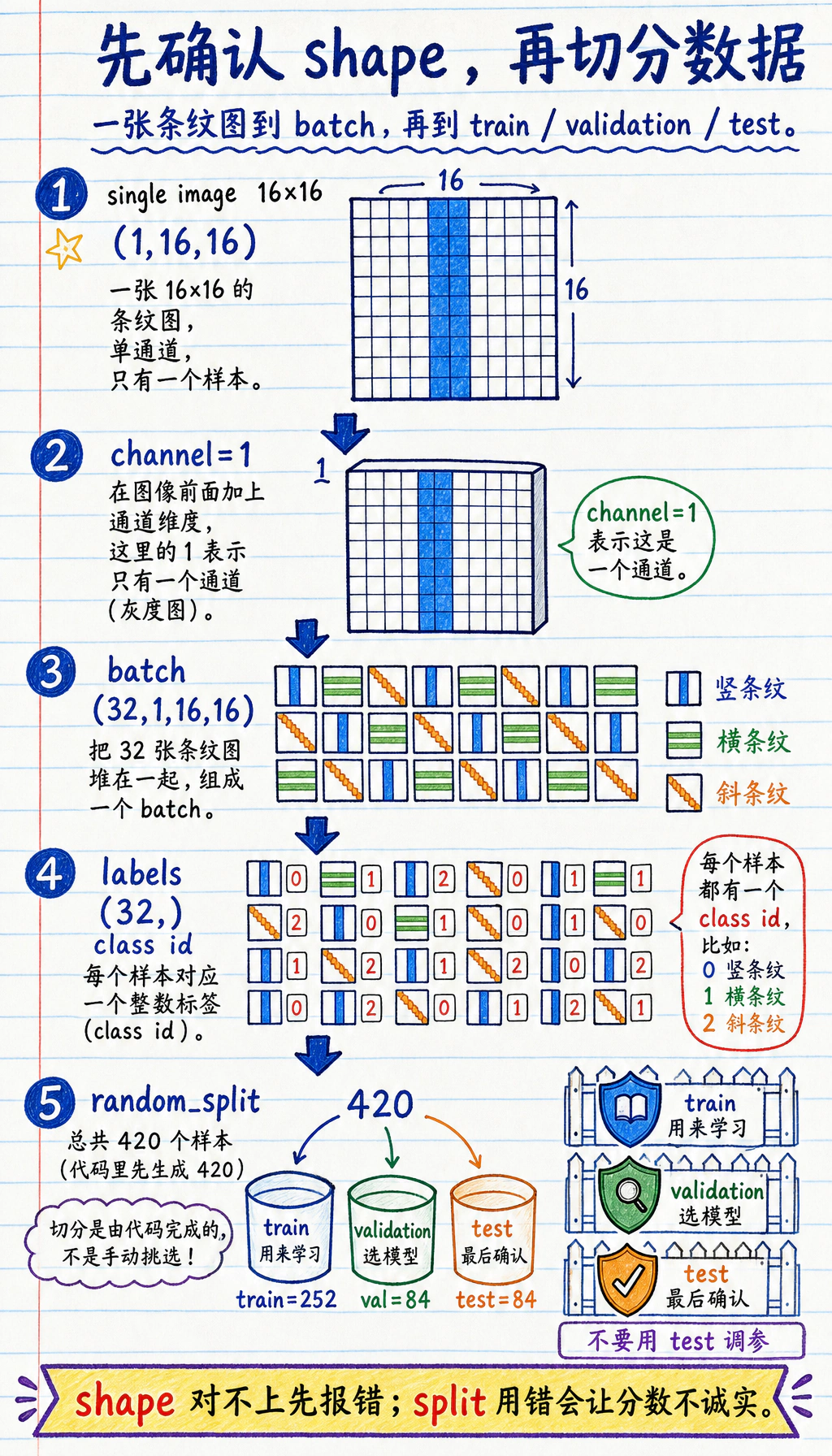
先建立心智模型:一张图、一个 batch、三份数据
Section titled “先建立心智模型:一张图、一个 batch、三份数据”运行脚本前,先记住这张小地图:
- 一张生成图片的 tensor shape 是
(1, 16, 16):1 个灰度通道,高 16,宽 16。 - 一个 mini-batch 会变成
(32, 1, 16, 16):32 张图片一起进入模型。 - 标签 batch 是
(32,):每张图片对应一个整数类别 id。 train_set用来教模型,val_set用来选择模型,test_set留到最后确认分数。
数据划分很重要。如果你反复看 test set 来调学习率、epoch 或模型宽度,test 分数就不再诚实。这个小工作坊用固定 seed 的 random_split,让你每次复跑都能得到一致的教学证据。
证据流程:从训练运行到报告
Section titled “证据流程:从训练运行到报告”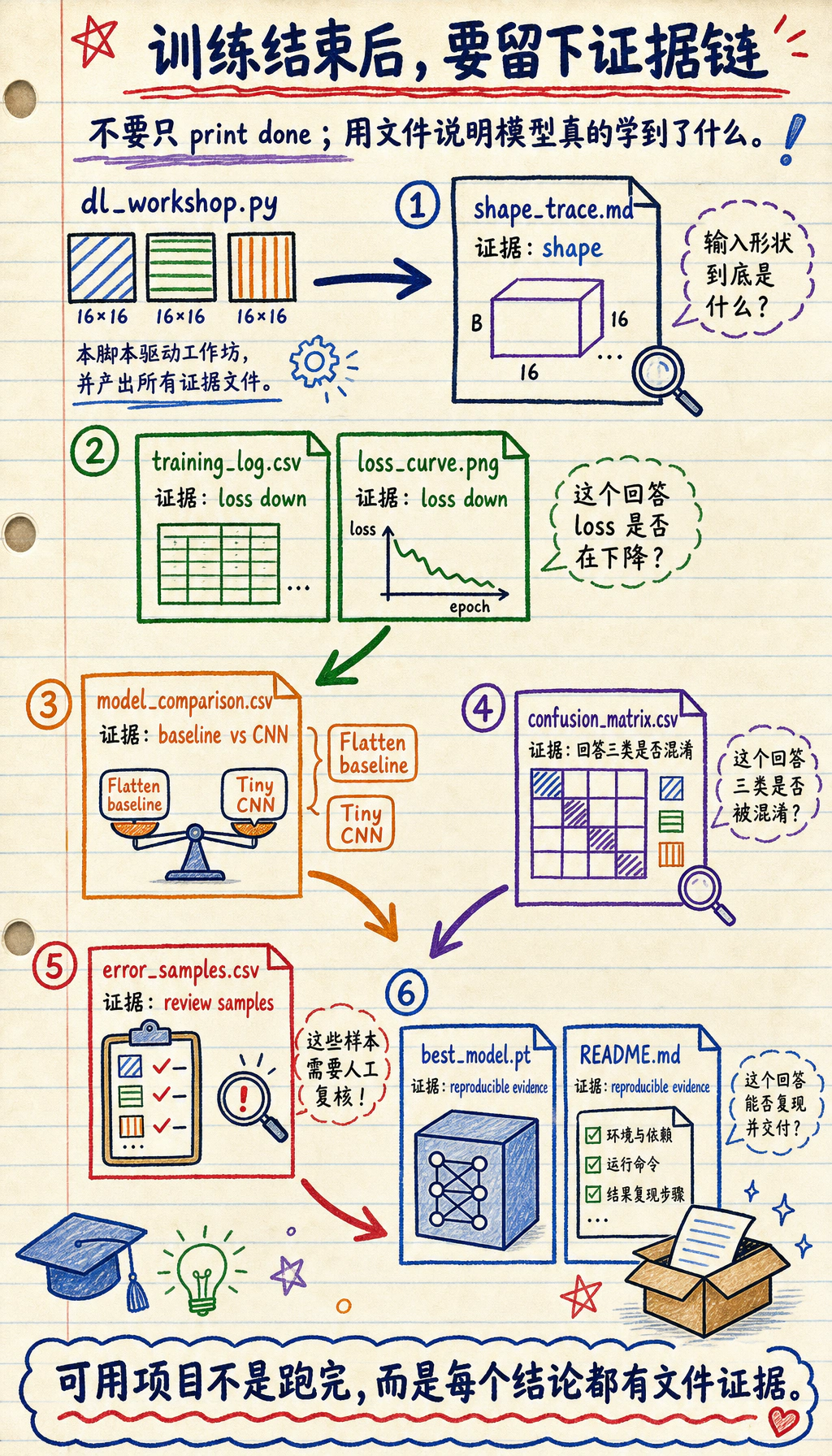
读这张图时,重点看训练证据从 batch shape 开始,到训练日志、曲线、checkpoint、复盘样本和 README 结束。没有这些输出,只有一行 accuracy 很难判断训练是否健康。
新手常见错误是停在:
loss.backward()optimizer.step()print("done")这不能证明训练过程是健康的。一个可用的深度学习项目应该回答:
- 进入模型的 shape 是什么?
- loss 真的下降了吗?
- validation 有改善,还是只有 training 在改善?
- 哪个模型超过了 baseline?
- 哪些样本需要人工复盘?
- 别人能不能从干净目录复跑项目?
下面脚本会生成这套证据包:
outputs/training_log.csv:每个 epoch 的训练和验证指标。outputs/model_comparison.csv:baseline 和 CNN 的对比。outputs/confusion_matrix.csv:类别级错误分布。outputs/error_samples.csv:错误样本或低置信度复盘样本。outputs/metrics_summary.json:最终模型和测试指标摘要。curves/loss_curve.png:训练/验证 loss 曲线。checkpoints/best_model.pt:可加载的最佳模型状态。reports/shape_trace.md:batch、label 和 logits 的 shape 记录。reports/debug_checklist.md:排错清单。README.md:复跑命令、结果摘要和下一步。
这个工作坊完成时,文件夹本身应该能证明完整训练闭环:
- 形状 trace
- 一个批次形状和 logits 形状
- 训练日志
- 训练和验证曲线
- 模型比较
- 基线 vs CNN
- 混淆矩阵
- 类别级错误
- 错误样本
- 需要检查的具体失败案例
- 检查点
- 可以恢复最佳模型
- README 记录
- 命令、指标、限制和下一步
运行前先解码几个术语
Section titled “运行前先解码几个术语”- Tensor:多维数组。本工作坊里,一个图像 batch 的 shape 是
(batch, channel, height, width)。 - Logits:softmax 前的模型原始输出。
CrossEntropyLoss需要 logits,不需要概率。 - Epoch:训练集完整跑一遍。
- Validation set:开发过程中用来选择模型的数据,不等同于最终 test set。
- Checkpoint:保存下来的模型状态,后续可以加载复用。
- CNN:Convolutional Neural Network,用卷积核学习局部视觉模式的网络。
- Overfitting(过拟合):训练集越来越好,但验证集没有变好,模型记住了太多训练细节。
如果你在本课程仓库中,安装核心环境和 AI 环境:
python -m pip install -r requirements-course-core.txt -r requirements-course-ai.txt如果你在单独目录里练习,本工作坊只需要 PyTorch 和 Matplotlib:
python -m pip install torch matplotlibPyTorch 官方安装页把 Stable 版本描述为当前经过测试并受支持的版本。本工作坊使用稳定的 PyTorch 2.x 核心 API,不需要 torchvision、GPU 或任何下载数据集。本地已用 Python 3.13 和 PyTorch 2.11 验证。
跟着跑完整工作坊
Section titled “跟着跑完整工作坊”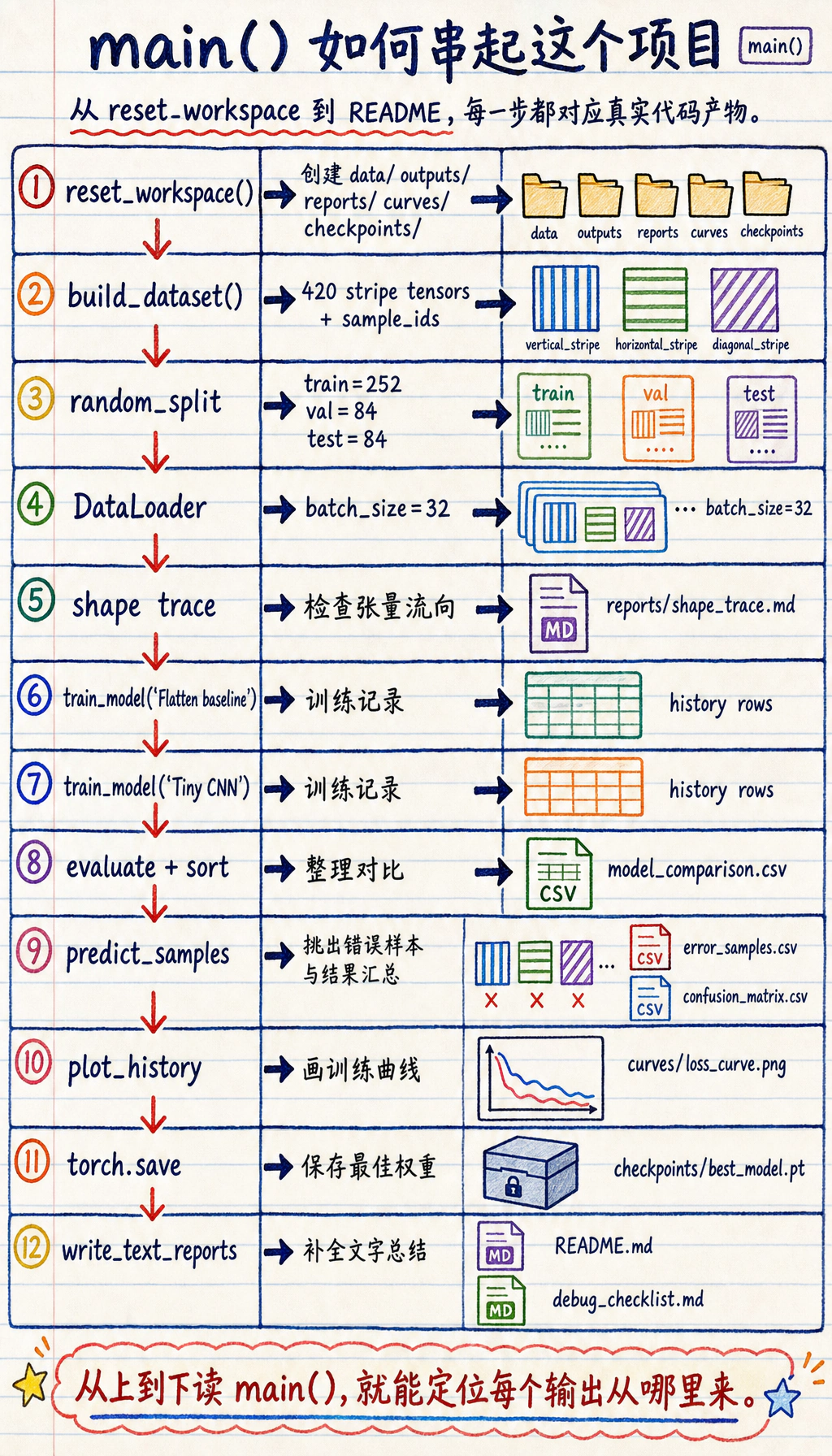
先读执行顺序图:目录、脚本、第一次运行、证据检查要按顺序做。第一轮先不要调参,它是后面实验的参照线。
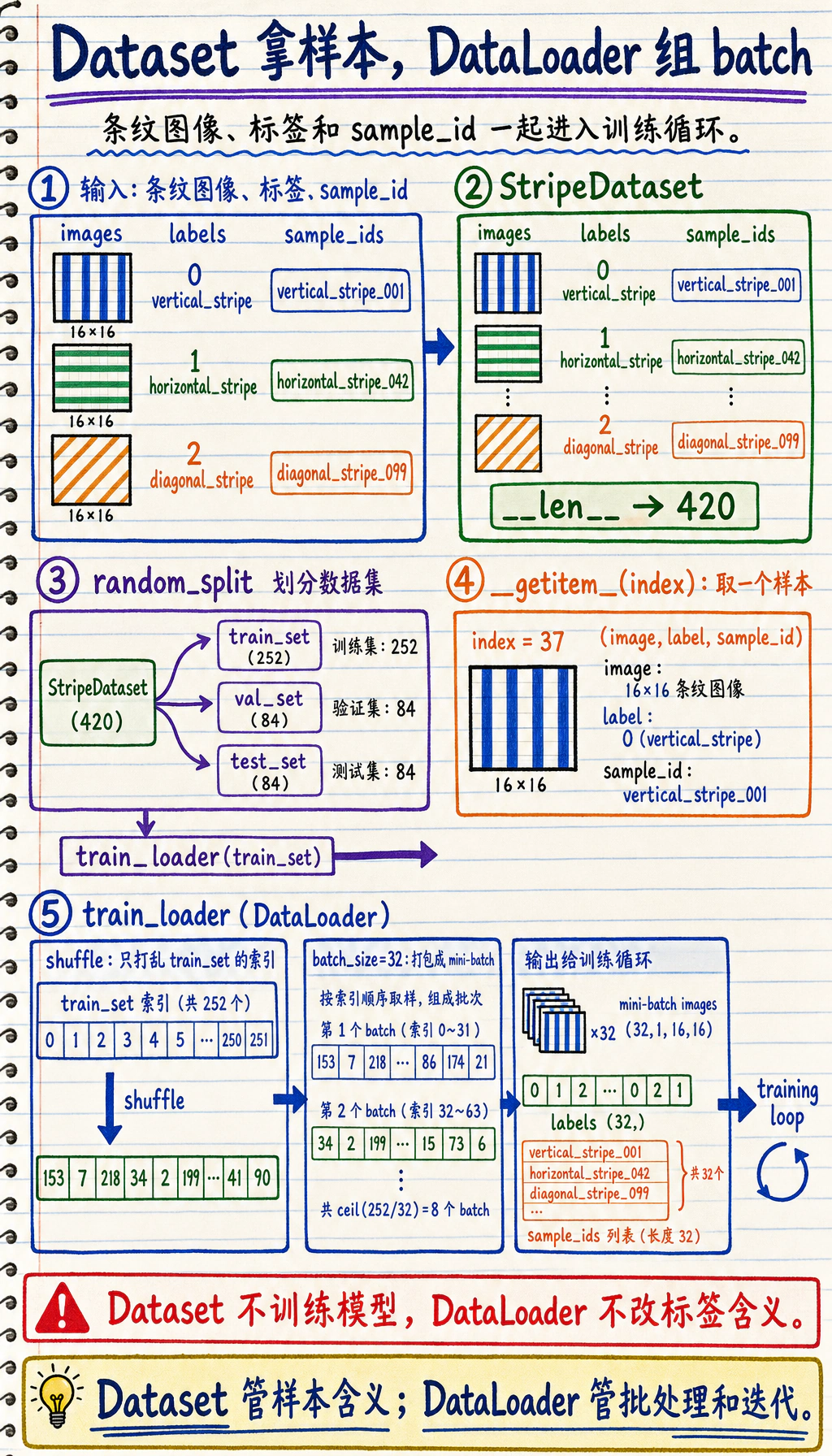
再读批处理图:Dataset 负责单条样本,DataLoader 负责打包成 batch,训练循环只接收已经整理好的 batch。
代码分成三层:
StripeDataset知道有多少样本,也知道如何返回一条(image, label, sample_id)记录。DataLoader把很多单条记录整理成打乱后的 mini-batch。- 训练循环消费这些 mini-batch,并更新模型参数。
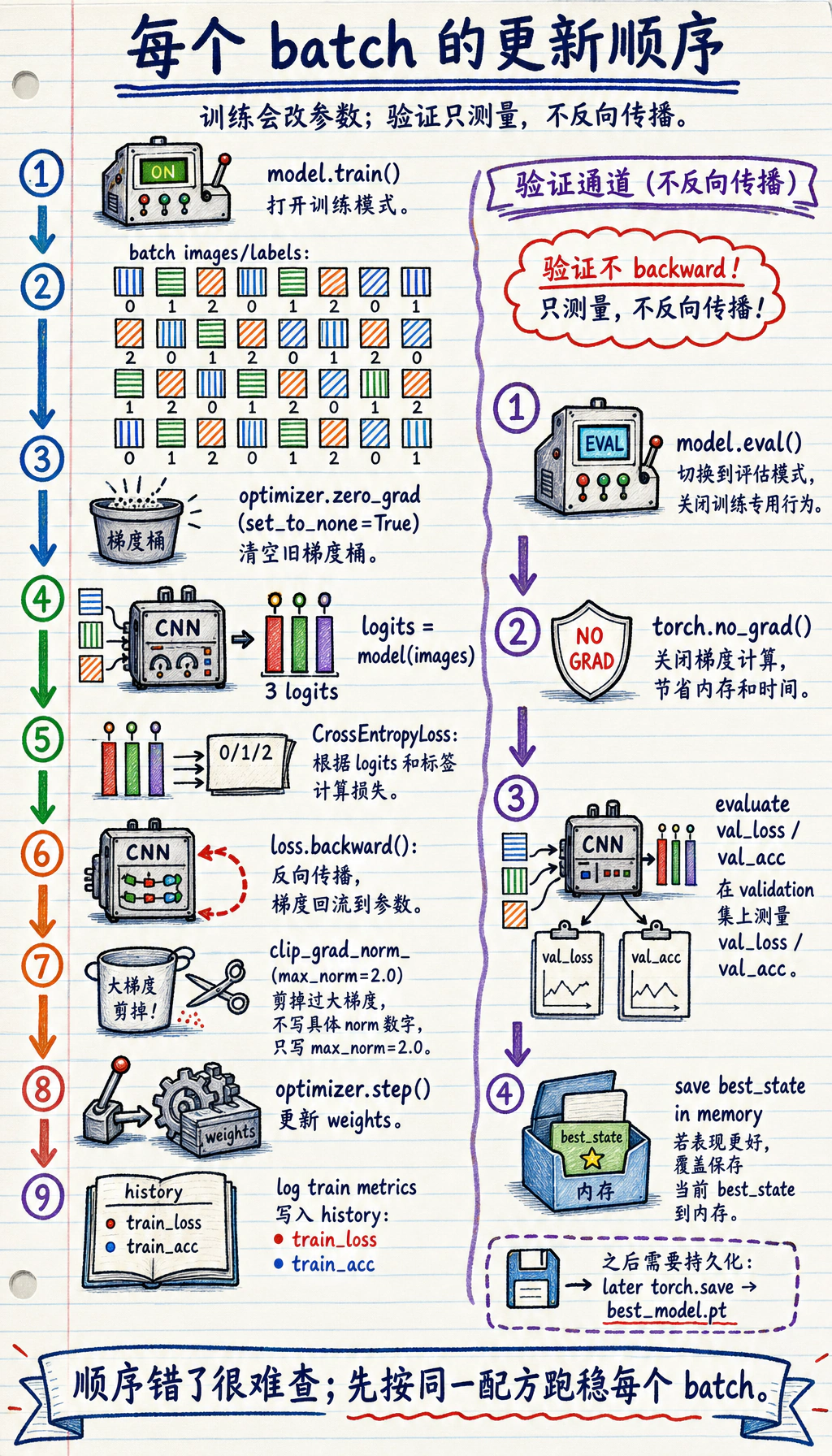
对每个训练 batch,把循环读成一个有顺序的配方:清空旧梯度、运行模型、计算 loss、反向传播、裁剪过大的梯度、让 optimizer 更新参数。验证阶段使用 model.eval() 和 torch.no_grad(),因为它只测量模型,不修改模型。
创建干净目录
Section titled “创建干净目录”mkdir ch06-dl-workshopcd ch06-dl-workshop创建 dl_workshop.py
Section titled “创建 dl_workshop.py”把下面代码保存为 dl_workshop.py。
from __future__ import annotations
import copyimport csvimport jsonimport mathimport shutilfrom pathlib import Path
import matplotlib
matplotlib.use("Agg")import matplotlib.pyplot as pltimport torchfrom torch import nnfrom torch.utils.data import DataLoader, Dataset, random_split
RUN_DIR = Path("deep_learning_workshop_run")DATA_DIR = RUN_DIR / "data"OUTPUT_DIR = RUN_DIR / "outputs"REPORT_DIR = RUN_DIR / "reports"CURVE_DIR = RUN_DIR / "curves"CHECKPOINT_DIR = RUN_DIR / "checkpoints"
CLASSES = ["vertical_stripe", "horizontal_stripe", "diagonal_stripe"]IMAGE_SIZE = 16SAMPLES_PER_CLASS = 140BATCH_SIZE = 32SEED = 42
def reset_workspace() -> None: if RUN_DIR.exists(): shutil.rmtree(RUN_DIR) for folder in (DATA_DIR, OUTPUT_DIR, REPORT_DIR, CURVE_DIR, CHECKPOINT_DIR): folder.mkdir(parents=True, exist_ok=True)
class StripeDataset(Dataset): def __init__(self, images: torch.Tensor, labels: torch.Tensor, sample_ids: list[str]): self.images = images.float() self.labels = labels.long() self.sample_ids = sample_ids
def __len__(self) -> int: return len(self.labels)
def __getitem__(self, index: int): return self.images[index], self.labels[index], self.sample_ids[index]
def make_stripe_image(label: int, generator: torch.Generator) -> torch.Tensor: image = torch.randn((IMAGE_SIZE, IMAGE_SIZE), generator=generator) * 0.20 if label == 0: col = int(torch.randint(1, IMAGE_SIZE - 2, (1,), generator=generator)) image[:, col : col + 2] += 1.0 elif label == 1: row = int(torch.randint(1, IMAGE_SIZE - 2, (1,), generator=generator)) image[row : row + 2, :] += 1.0 else: offset = int(torch.randint(-3, 4, (1,), generator=generator)) for row in range(IMAGE_SIZE): col = row + offset if 0 <= col < IMAGE_SIZE: image[row, col] += 1.1 if col + 1 < IMAGE_SIZE: image[row, col + 1] += 0.8
if float(torch.rand((), generator=generator)) < 0.18: top = int(torch.randint(0, IMAGE_SIZE - 4, (1,), generator=generator)) left = int(torch.randint(0, IMAGE_SIZE - 4, (1,), generator=generator)) image[top : top + 4, left : left + 4] *= 0.25 return image.clamp(-1.0, 1.5).unsqueeze(0)
def build_dataset(seed: int = SEED) -> StripeDataset: generator = torch.Generator().manual_seed(seed) images = [] labels = [] sample_ids = [] for label, class_name in enumerate(CLASSES): for index in range(SAMPLES_PER_CLASS): images.append(make_stripe_image(label, generator)) labels.append(label) sample_ids.append(f"{class_name}_{index:03d}") return StripeDataset(torch.stack(images), torch.tensor(labels), sample_ids)
class FlattenBaseline(nn.Module): def __init__(self): super().__init__() self.net = nn.Sequential(nn.Flatten(), nn.Linear(IMAGE_SIZE * IMAGE_SIZE, len(CLASSES)))
def forward(self, x: torch.Tensor) -> torch.Tensor: return self.net(x)
class TinyCNN(nn.Module): def __init__(self): super().__init__() self.features = nn.Sequential( nn.Conv2d(1, 8, kernel_size=3, padding=1), nn.ReLU(), nn.MaxPool2d(2), nn.Conv2d(8, 16, kernel_size=3, padding=1), nn.ReLU(), nn.AdaptiveAvgPool2d((1, 1)), ) self.classifier = nn.Linear(16, len(CLASSES))
def forward(self, x: torch.Tensor) -> torch.Tensor: x = self.features(x) x = torch.flatten(x, 1) return self.classifier(x)
def evaluate(model: nn.Module, loader: DataLoader, loss_fn: nn.Module) -> tuple[float, float]: model.eval() total_loss = 0.0 total_correct = 0 total_examples = 0 with torch.no_grad(): for images, labels, _sample_ids in loader: logits = model(images) loss = loss_fn(logits, labels) total_loss += float(loss.item()) * len(labels) total_correct += int((logits.argmax(dim=1) == labels).sum().item()) total_examples += len(labels) return total_loss / total_examples, total_correct / total_examples
def train_model(name: str, model: nn.Module, train_loader: DataLoader, val_loader: DataLoader, *, epochs: int, lr: float): loss_fn = nn.CrossEntropyLoss() optimizer = torch.optim.Adam(model.parameters(), lr=lr) history = [] best_state = copy.deepcopy(model.state_dict()) best_val_acc = -math.inf
for epoch in range(1, epochs + 1): model.train() total_loss = 0.0 total_correct = 0 total_examples = 0 for images, labels, _sample_ids in train_loader: optimizer.zero_grad(set_to_none=True) logits = model(images) loss = loss_fn(logits, labels) loss.backward() torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=2.0) optimizer.step()
total_loss += float(loss.item()) * len(labels) total_correct += int((logits.argmax(dim=1) == labels).sum().item()) total_examples += len(labels)
train_loss = total_loss / total_examples train_acc = total_correct / total_examples val_loss, val_acc = evaluate(model, val_loader, loss_fn) history.append( { "model": name, "epoch": epoch, "train_loss": round(train_loss, 4), "train_acc": round(train_acc, 4), "val_loss": round(val_loss, 4), "val_acc": round(val_acc, 4), } ) if val_acc > best_val_acc: best_val_acc = val_acc best_state = copy.deepcopy(model.state_dict())
model.load_state_dict(best_state) return history, best_val_acc
def predict_samples(model: nn.Module, loader: DataLoader) -> list[dict]: model.eval() rows = [] with torch.no_grad(): for images, labels, sample_ids in loader: logits = model(images) probabilities = torch.softmax(logits, dim=1) confidence, predictions = probabilities.max(dim=1) for sample_id, actual, pred, conf in zip(sample_ids, labels.tolist(), predictions.tolist(), confidence.tolist()): rows.append( { "sample_id": sample_id, "actual": CLASSES[actual], "predicted": CLASSES[pred], "confidence": round(float(conf), 4), "correct": actual == pred, } ) return rows
def confusion_matrix_rows(prediction_rows: list[dict]) -> list[list[str | int]]: matrix = [[0 for _ in CLASSES] for _ in CLASSES] name_to_index = {name: index for index, name in enumerate(CLASSES)} for row in prediction_rows: matrix[name_to_index[row["actual"]]][name_to_index[row["predicted"]]] += 1 return [["actual/predicted", *CLASSES], *[[CLASSES[i], *matrix[i]] for i in range(len(CLASSES))]]
def write_csv(path: Path, rows: list[dict]) -> None: with path.open("w", newline="", encoding="utf-8") as file: writer = csv.DictWriter(file, fieldnames=list(rows[0].keys())) writer.writeheader() writer.writerows(rows)
def write_matrix_csv(path: Path, rows: list[list[str | int]]) -> None: with path.open("w", newline="", encoding="utf-8") as file: csv.writer(file).writerows(rows)
def plot_history(history: list[dict]) -> None: grouped = {} for row in history: grouped.setdefault(row["model"], []).append(row)
plt.figure(figsize=(8, 5)) for name, rows in grouped.items(): epochs = [row["epoch"] for row in rows] plt.plot(epochs, [row["train_loss"] for row in rows], label=f"{name} train_loss") plt.plot(epochs, [row["val_loss"] for row in rows], linestyle="--", label=f"{name} val_loss") plt.xlabel("epoch") plt.ylabel("loss") plt.title("Training and validation loss") plt.legend() plt.tight_layout() plt.savefig(CURVE_DIR / "loss_curve.png", dpi=140) plt.close()
def write_text_reports(summary: dict, shape_trace: str) -> None: (REPORT_DIR / "shape_trace.md").write_text(shape_trace, encoding="utf-8") (REPORT_DIR / "debug_checklist.md").write_text( "\n".join( [ "# Debug Checklist", "", "- If the loss does not decrease, lower the learning rate and verify labels.", "- If shapes do not match, print one batch and one logits tensor first.", "- If training accuracy rises but validation accuracy stalls, suspect overfitting.", "- If results change every run, check random seeds and DataLoader shuffle settings.", "- If GPU memory is exhausted, reduce batch size or image size before changing the model.", ] ) + "\n", encoding="utf-8", ) (RUN_DIR / "README.md").write_text( "\n".join( [ "# 深度学习工作坊证据包", "", "运行命令:", "", "```bash", "python dl_workshop.py", "```", "", f"最佳模型:{summary['best_model']}", f"测试准确率:{summary['test_accuracy']}", "", "证据文件:", "- outputs/training_log.csv", "- outputs/model_comparison.csv", "- outputs/confusion_matrix.csv", "- outputs/error_samples.csv", "- curves/loss_curve.png", "- reports/shape_trace.md", "- reports/debug_checklist.md", ] ) + "\n", encoding="utf-8", )
def main() -> None: torch.manual_seed(SEED) reset_workspace()
dataset = build_dataset() generator = torch.Generator().manual_seed(SEED) train_set, val_set, test_set = random_split(dataset, [252, 84, 84], generator=generator) train_loader = DataLoader(train_set, batch_size=BATCH_SIZE, shuffle=True, generator=generator) val_loader = DataLoader(val_set, batch_size=BATCH_SIZE) test_loader = DataLoader(test_set, batch_size=BATCH_SIZE)
sample_images, sample_labels, _sample_ids = next(iter(train_loader)) shape_trace = "\n".join( [ "# Shape Trace", "", f"- One image batch: `{tuple(sample_images.shape)}` means batch, channel, height, width.", f"- One label batch: `{tuple(sample_labels.shape)}` means one class id per image.", f"- Model output should be `(batch, {len(CLASSES)})`, one logit per class.", ] ) + "\n"
configs = [ {"name": "Flatten baseline", "model": FlattenBaseline(), "epochs": 4, "lr": 0.01}, {"name": "Tiny CNN", "model": TinyCNN(), "epochs": 10, "lr": 0.006}, ] all_history = [] comparison_rows = [] trained_models = {} loss_fn = nn.CrossEntropyLoss()
for config in configs: history, best_val_acc = train_model( config["name"], config["model"], train_loader, val_loader, epochs=config["epochs"], lr=config["lr"], ) test_loss, test_acc = evaluate(config["model"], test_loader, loss_fn) all_history.extend(history) comparison_rows.append( { "model": config["name"], "epochs": config["epochs"], "best_val_acc": round(best_val_acc, 4), "test_loss": round(test_loss, 4), "test_accuracy": round(test_acc, 4), } ) trained_models[config["name"]] = config["model"]
comparison_rows = sorted(comparison_rows, key=lambda row: (row["test_accuracy"], row["best_val_acc"]), reverse=True) best_name = comparison_rows[0]["model"] best_model = trained_models[best_name] predictions = predict_samples(best_model, test_loader) errors = [row for row in predictions if not row["correct"]] review_rows = errors[:10] if errors else sorted(predictions, key=lambda row: row["confidence"])[:10] for row in review_rows: row["review_reason"] = "wrong prediction" if not row["correct"] else "lowest-confidence correct prediction"
summary = { "best_model": best_name, "test_accuracy": comparison_rows[0]["test_accuracy"], "classes": CLASSES, "train_samples": len(train_set), "val_samples": len(val_set), "test_samples": len(test_set), }
write_csv(OUTPUT_DIR / "training_log.csv", all_history) write_csv(OUTPUT_DIR / "model_comparison.csv", comparison_rows) write_matrix_csv(OUTPUT_DIR / "confusion_matrix.csv", confusion_matrix_rows(predictions)) write_csv(OUTPUT_DIR / "error_samples.csv", review_rows) (OUTPUT_DIR / "metrics_summary.json").write_text(json.dumps(summary, indent=2), encoding="utf-8") torch.save({"model_name": best_name, "model_state": best_model.state_dict(), "classes": CLASSES}, CHECKPOINT_DIR / "best_model.pt") plot_history(all_history) write_text_reports(summary, shape_trace)
print("STEP 1: data prepared") print(f"train_samples: {len(train_set)}") print(f"val_samples: {len(val_set)}") print(f"test_samples: {len(test_set)}") print(f"classes: {len(CLASSES)}") print("STEP 2: model comparison") print(f"baseline_val_acc: {next(row['best_val_acc'] for row in comparison_rows if row['model'] == 'Flatten baseline'):.3f}") print(f"cnn_val_acc: {next(row['best_val_acc'] for row in comparison_rows if row['model'] == 'Tiny CNN'):.3f}") print(f"best_model: {best_name}") print(f"test_accuracy: {comparison_rows[0]['test_accuracy']:.3f}") print("STEP 3: evidence files") print(RUN_DIR / "README.md") print(OUTPUT_DIR / "training_log.csv") print(OUTPUT_DIR / "model_comparison.csv") print(CURVE_DIR / "loss_curve.png") print(REPORT_DIR / "shape_trace.md")
if __name__ == "__main__": main()python dl_workshop.py预期输出:
STEP 1: data preparedtrain_samples: 252val_samples: 84test_samples: 84classes: 3STEP 2: model comparisonbaseline_val_acc: 0.929cnn_val_acc: 1.000best_model: Tiny CNNtest_accuracy: 1.000STEP 3: evidence filesdeep_learning_workshop_run/README.mddeep_learning_workshop_run/outputs/training_log.csvdeep_learning_workshop_run/outputs/model_comparison.csvdeep_learning_workshop_run/curves/loss_curve.pngdeep_learning_workshop_run/reports/shape_trace.md确认证据文件确实生成了:
find deep_learning_workshop_run -maxdepth 2 -type f | sort预期输出:
deep_learning_workshop_run/README.mddeep_learning_workshop_run/checkpoints/best_model.ptdeep_learning_workshop_run/curves/loss_curve.pngdeep_learning_workshop_run/outputs/confusion_matrix.csvdeep_learning_workshop_run/outputs/error_samples.csvdeep_learning_workshop_run/outputs/metrics_summary.jsondeep_learning_workshop_run/outputs/model_comparison.csvdeep_learning_workshop_run/outputs/training_log.csvdeep_learning_workshop_run/reports/debug_checklist.mddeep_learning_workshop_run/reports/shape_trace.md按顺序读取输出
Section titled “按顺序读取输出”
读这张输出图时,不要从最终 test accuracy 开始。先看 shape trace,再看训练曲线和模型对比,最后才读错误样本和 checkpoint。
先看 shape_trace.md
Section titled “先看 shape_trace.md”运行:
sed -n '1,20p' deep_learning_workshop_run/reports/shape_trace.md预期输出:
# Shape Trace
- One image batch: `(32, 1, 16, 16)` means batch, channel, height, width.- One label batch: `(32,)` means one class id per image.- Model output should be `(batch, 3)`, one logit per class.可以这样读:
32:batch size1:灰度通道16:图像高度16:图像宽度
如果这个 shape 和 Conv2d 期望的不一致,模型还没开始学习就会报错。
读取 training_log.csv
Section titled “读取 training_log.csv”不要只用肉眼扫完整 CSV,先跑一个小读取器:
python - <<'PY'import csvfrom collections import defaultdictfrom pathlib import Path
rows = list(csv.DictReader((Path("deep_learning_workshop_run") / "outputs" / "training_log.csv").open()))by_model = defaultdict(list)for row in rows: by_model[row["model"]].append(row)
for model, model_rows in by_model.items(): first = model_rows[0] last = model_rows[-1] print( f"{model}: " f"first_train_loss={float(first['train_loss']):.4f}, " f"last_train_loss={float(last['train_loss']):.4f}, " f"last_val_acc={float(last['val_acc']):.4f}" )PY预期输出:
Flatten baseline: first_train_loss=0.8555, last_train_loss=0.1929, last_val_acc=0.9286Tiny CNN: first_train_loss=1.0961, last_train_loss=0.0711, last_val_acc=1.0000重点看三件事:
train_loss有没有下降?val_loss是否也在下降?val_acc是否在提升,而且 train/validation 差距不大?
这些问题比只问最终准确率高不高更有价值。
比较 baseline 和 CNN
Section titled “比较 baseline 和 CNN”运行:
python - <<'PY'import csvimport jsonfrom pathlib import Path
run = Path("deep_learning_workshop_run")summary = json.loads((run / "outputs" / "metrics_summary.json").read_text())print(f"best_model={summary['best_model']}")print(f"test_accuracy={summary['test_accuracy']:.3f}")
with (run / "outputs" / "model_comparison.csv").open() as file: for row in csv.DictReader(file): print( f"{row['model']}: " f"best_val_acc={float(row['best_val_acc']):.3f}, " f"test_accuracy={float(row['test_accuracy']):.3f}" )PY预期输出:
best_model=Tiny CNNtest_accuracy=1.000Tiny CNN: best_val_acc=1.000, test_accuracy=1.000Flatten baseline: best_val_acc=0.929, test_accuracy=0.917Flatten baseline 没有利用局部视觉模式。Tiny CNN 能学习小的局部卷积核,因此更适合条纹类图像数据。这就是“模型结构要匹配数据结构”的实践含义。
复盘 error_samples.csv
Section titled “复盘 error_samples.csv”先读混淆矩阵:
cat deep_learning_workshop_run/outputs/confusion_matrix.csv预期输出:
actual/predicted,vertical_stripe,horizontal_stripe,diagonal_stripevertical_stripe,25,0,0horizontal_stripe,0,28,0diagonal_stripe,0,0,31再查看复盘样本文件:
python - <<'PY'import csvfrom pathlib import Path
rows = list(csv.DictReader((Path("deep_learning_workshop_run") / "outputs" / "error_samples.csv").open()))print(f"review_rows={len(rows)}")first = rows[0]print( f"first_review={first['sample_id']} " f"predicted={first['predicted']} " f"confidence={float(first['confidence']):.4f} " f"reason={first['review_reason']}")PY预期输出:
review_rows=10first_review=diagonal_stripe_099 predicted=diagonal_stripe confidence=0.4211 reason=lowest-confidence correct prediction如果模型预测错了,这个文件会保存错误预测。如果测试集全部预测正确,它会保存置信度最低的正确样本。两者都有价值:真实项目需要复盘样本,而不只是最终分数。
看 loss 曲线
Section titled “看 loss 曲线”打开 deep_learning_workshop_run/curves/loss_curve.png。
问自己:
- training 和 validation 是否朝同一个方向移动?
- 哪个模型收敛更快?
- validation 停止改善时,training 是否还在继续变好?
这个习惯会在迁移学习、微调和大模型训练中反复用到。
加载一次 checkpoint
Section titled “加载一次 checkpoint”checkpoint 只有能被加载才有价值。跑一个快速 smoke test:
python - <<'PY'from pathlib import Pathimport torch
checkpoint = torch.load(Path("deep_learning_workshop_run") / "checkpoints" / "best_model.pt", map_location="cpu")print(checkpoint["model_name"])print(", ".join(checkpoint["classes"]))PY预期输出:
Tiny CNNvertical_stripe, horizontal_stripe, diagonal_stripe这一步还没有重建完整模型,只是确认文件里包含后续写推理脚本会用到的模型名、参数和类别列表。
常见错误和排错闭环
Section titled “常见错误和排错闭环”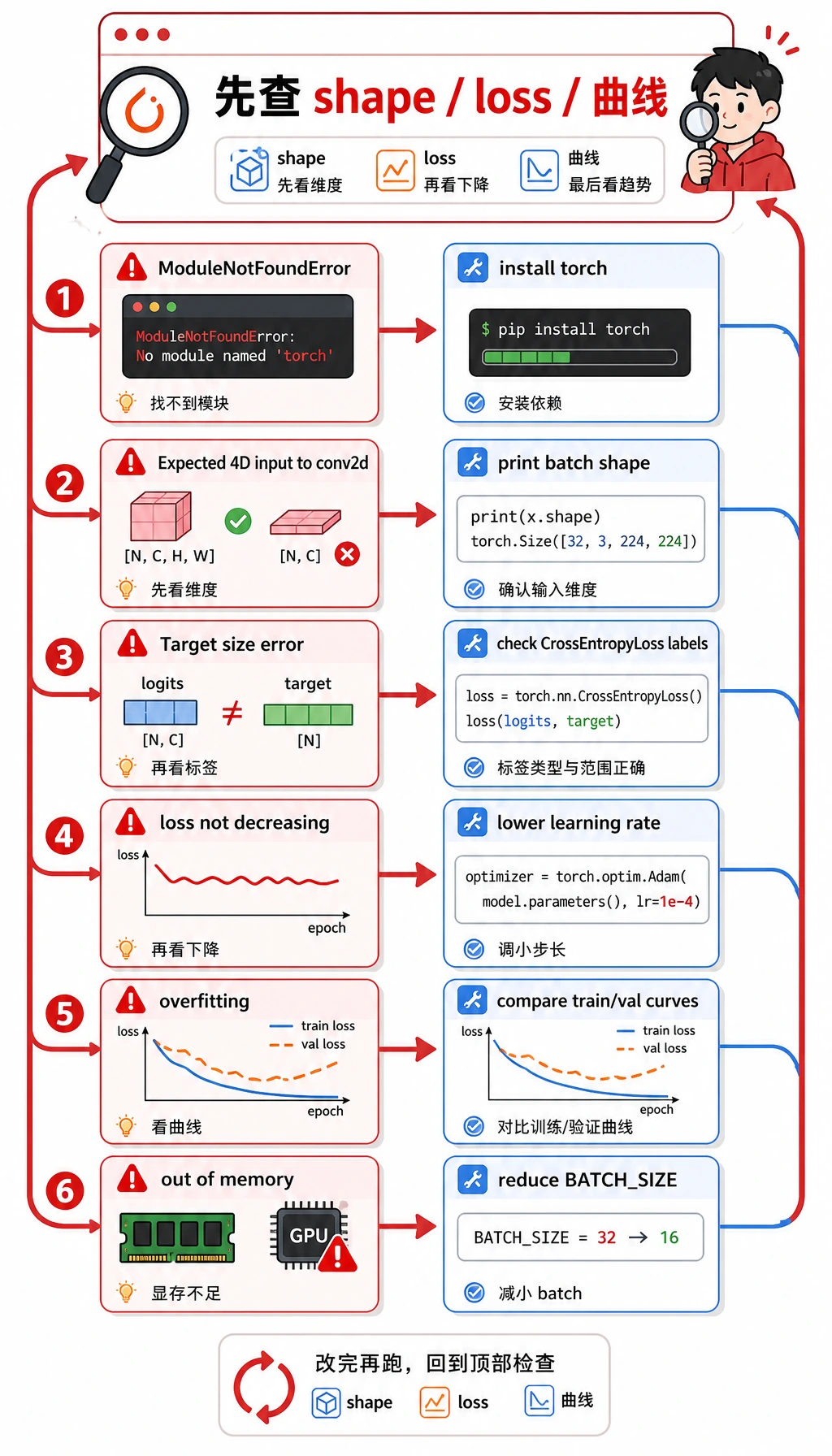
| 症状 | 可能原因 | 处理方式 |
|---|---|---|
ModuleNotFoundError: No module named 'torch' | 当前环境没安装 PyTorch | 运行 python -m pip install torch matplotlib |
Expected 4D input to conv2d | 图像 tensor 缺少 channel 或 batch 维度 | 打印 batch shape,确认是 (batch, channel, height, width) |
Target size 或 class index 报错 | 标签不符合 CrossEntropyLoss 要求 | 使用 shape 为 (batch,) 的整数类别 id |
| loss 不下降 | 学习率不合适、标签错误或输入尺度异常 | 先调小学习率,并尝试过拟合一个 tiny batch |
| training 变好但 validation 不变好 | 过拟合或划分不合理 | 增加正则化、更多数据、数据增强或 early stopping |
| CPU/GPU 内存压力 | batch、图像或模型太大 | 先降低 BATCH_SIZE、图像尺寸或模型宽度 |
升级成作品集项目
Section titled “升级成作品集项目”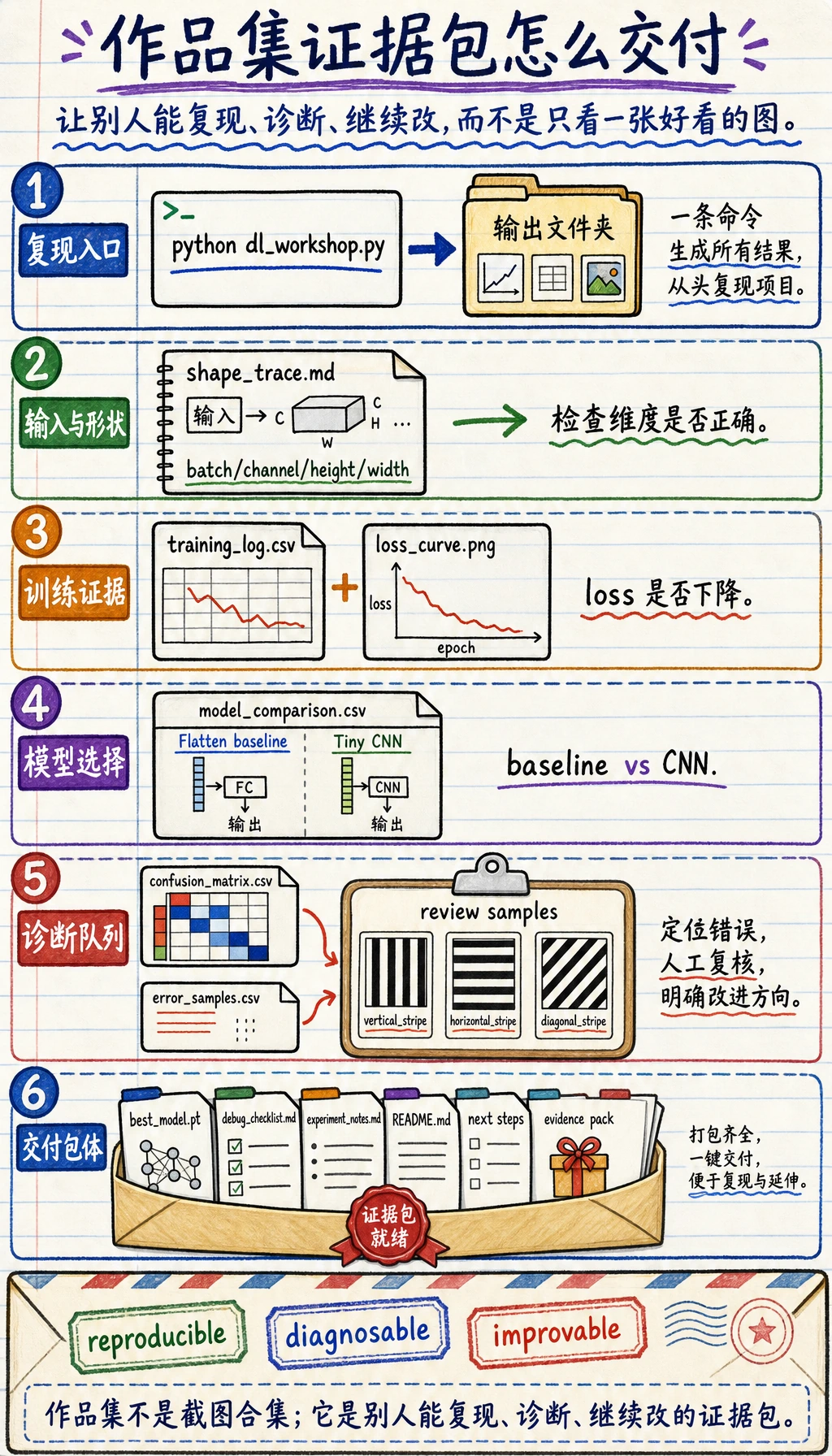
这张作品集图提醒你:一个能被别人审阅的深度学习项目,至少要包含训练日志、曲线、checkpoint、错误样本和复跑说明。
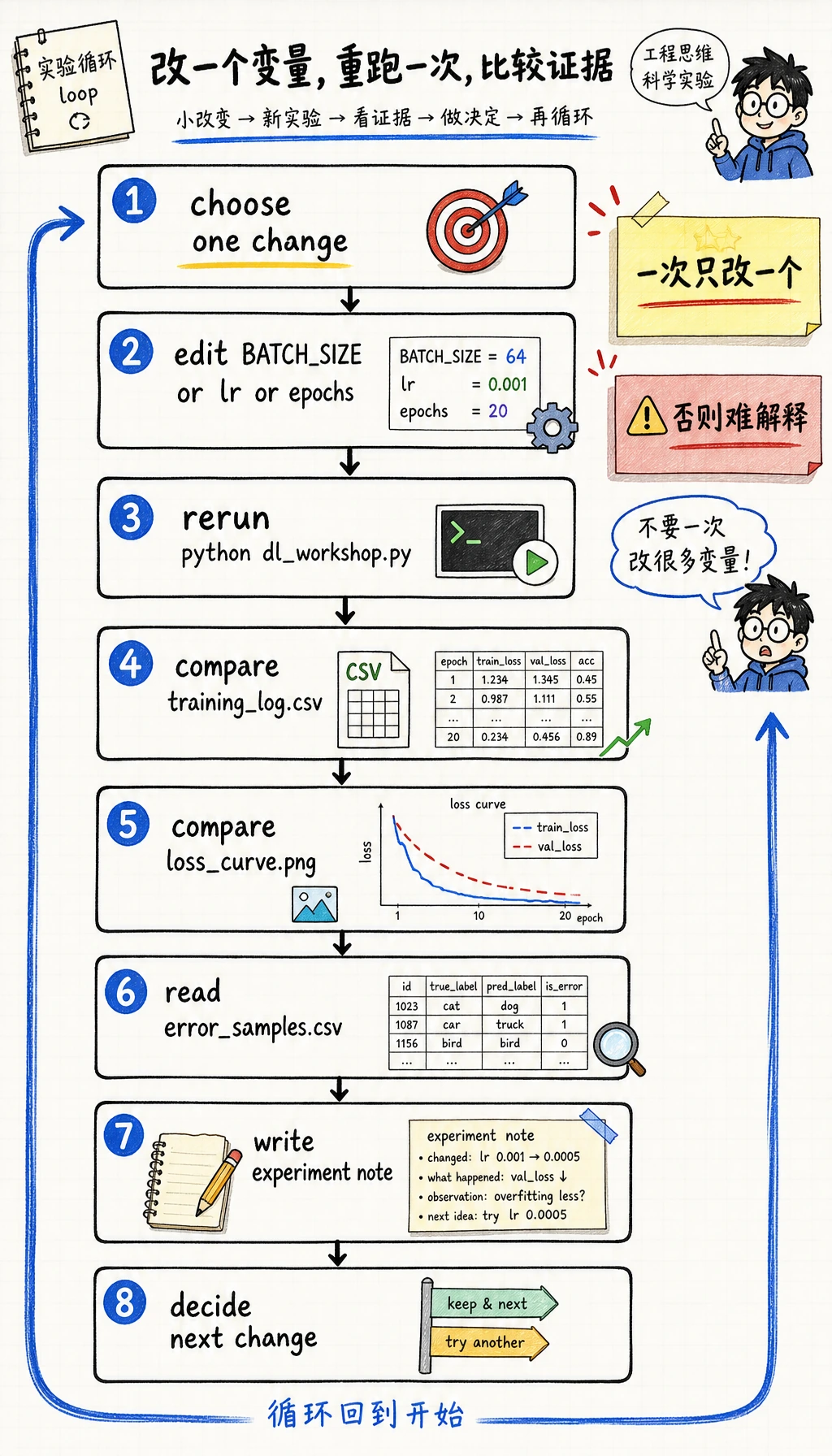
读复跑闭环图时,只记住一个纪律:一次只改 batch_size、学习率或 epoch 里的一个变量,再用同一套输出判断变化。
可以小步升级这个工作坊:
- 把合成条纹数据换成一个真实小图像文件夹。
- 增加
config.json,管理batch_size、learning_rate、epochs和模型名。 - 在稳定 baseline 之后再加入数据增强。
- 保存复盘样本网格,而不只是 CSV。
- 增加 early stopping,并解释为什么选择这一轮 epoch。
- 在 README 中写一段 top failure patterns。
练一次“只改一个变量”的复跑
Section titled “练一次“只改一个变量”的复跑”继续前先做一个小实验:
- 保留第一次运行的
training_log.csv和loss_curve.png。 - 只改
dl_workshop.py里的一个常量,例如BATCH_SIZE、CNN 学习率,或 CNN epoch 数。 - 再运行
python dl_workshop.py。 - 比较新的
training_log.csv、model_comparison.csv、loss_curve.png和error_samples.csv。
写一条实验记录:
python - <<'PY'from pathlib import Path
run = Path("deep_learning_workshop_run")note = run / "reports" / "experiment_notes.md"note.write_text( "\n".join( [ "# Experiment Notes", "", "- Run 1: default constants, Tiny CNN selected by validation accuracy.", "- Next change: adjust only `BATCH_SIZE` or only `lr`, then compare `training_log.csv` and `loss_curve.png`.", ] ) + "\n", encoding="utf-8",)print(note)PY预期输出:
deep_learning_workshop_run/reports/experiment_notes.md重要习惯不是每次都拿到更高分,而是一次只改一个变量、干净复跑,并能用证据解释结果。
操作参考与检查点
一条合格的复跑记录要明确只改了哪个变量,然后用产物对比,而不是凭印象判断:
- 如果改了
BATCH_SIZE,比较训练速度、曲线平滑程度和 validation accuracy。batch 变大可能更平滑,但不一定更好。 - 如果改了 CNN learning rate,比较 loss curve 是下降、震荡还是卡住。第一轮 loss 更低并不等于整体更好。
- 如果改了 epoch 数,检查 validation loss 是继续改善还是开始过拟合。只有验证证据支持时,更多 epoch 才有意义。
- 最后的实验笔记要写出下一步动作,例如保留默认值、测试附近的一个值,或因为验证变差而回退。
作品集检查清单
Section titled “作品集检查清单”在说第 6 章项目完成前,确认你已经有:
- 能从干净目录运行的命令
- tensor shape trace
- baseline 模型
- 改进模型
- training 和 validation 日志
- loss 曲线
- 模型对比表
- checkpoint
- 复盘样本或错误样本
- 包含局限和下一步的 README
这个工作坊把第 6 章串成一个可运行闭环:tensor、dataset、dataloader、model、loss、optimizer、training、validation、checkpoint、curve、review samples 和 README 证据。你如果能复跑它并解释每个输出文件,就不是只在复制 PyTorch 代码,而是在用工程方式练深度学习。