7.4.3 预训练方法
- 理解不同预训练目标分别在教模型什么能力
- 区分 Causal LM、Masked LM、Span Corruption 的核心差异
- 通过一个可运行示例理解同一条文本如何被改造成不同训练样本
- 建立“任务目标和后续能力为什么强相关”的直觉
先建立一张地图
Section titled “先建立一张地图”预训练方法更适合按“模型每天在练什么”来理解:
flowchart LR A["Causal LM"] --> B["练续写和生成"] C["Masked LM"] --> D["练补空和双向理解"] E["Span Corruption"] --> F["练恢复片段和文本转换"]所以这节真正想解决的是:
- 同样都是预训练,为什么最后能力画像会不一样
- 为什么训练标签怎么构造,会直接影响模型后续擅长什么
一、为什么预训练目标会决定模型路线?
Section titled “一、为什么预训练目标会决定模型路线?”因为模型会优先学会“训练里反复被要求做的事”
Section titled “因为模型会优先学会“训练里反复被要求做的事””如果训练时模型不断被要求:
- 根据前文预测后文
它自然会更擅长:
- 续写
- 生成
如果训练时模型不断被要求:
- 根据左右文恢复被遮掉的 token
它自然更容易学会:
- 双向理解
- 语义补全
所以预训练目标不是表面任务, 而是模型能力的方向盘。
一个类比:训练任务会塑造系统行为
Section titled “一个类比:训练任务会塑造系统行为”你可以把训练目标想成不断驱动模型练习的测试框架。
- 如果测试框架总是遮住 token,模型就会练重建
- 如果测试框架总是要求续写,模型就会练 next-token prediction
- 如果测试框架总是给输入和期望输出,模型就会练输入到输出映射
模型也是一样。
一个更适合新人的总类比
Section titled “一个更适合新人的总类比”你可以把预训练目标理解成:
- 在决定模型每天刷什么题
如果它天天刷:
- 续写题
它最后自然会更像生成型选手。 如果它天天刷:
- 填空题
它更容易变成理解型选手。 如果它天天刷:
- 缺一整段的恢复题
它就更容易学会输入到输出的映射。
二、三条最重要的预训练路线
Section titled “二、三条最重要的预训练路线”因果语言建模(Causal Language Modeling):根据过去预测未来
Section titled “因果语言建模(Causal Language Modeling):根据过去预测未来”这是 GPT 一系最经典的目标。
形式上很简单:
- 输入前面的 token
- 预测下一个 token
它的好处是:
- 训练目标和生成任务天然一致
也就是说,训练时模型不能看未来, 推理时模型也不能看未来, 两者没有错位。
掩码语言建模(Masked Language Modeling):根据上下文补空
Section titled “掩码语言建模(Masked Language Modeling):根据上下文补空”这是 BERT 一系的经典目标。
做法是:
- 把输入里部分 token 遮掉
- 让模型根据左右文把它们补回来
这种目标非常适合双向建模, 所以它更擅长:
- 理解
- 表示学习
- 分类和抽取类任务
但它天然不如 Causal LM 那么适合自由生成。
片段破坏与去噪(Span Corruption / Denoising):不是遮一个词,而是遮一段
Section titled “片段破坏与去噪(Span Corruption / Denoising):不是遮一个词,而是遮一段”T5 / BART 一类模型常用更一般化的去噪目标:
- 不是只 mask 一个 token
- 而是 mask 一整段 span
- 然后让模型恢复这段内容
这会更贴近:
- 摘要
- 改写
- 翻译
- 文本到文本转换
三、先用同一条文本构造三种训练样本
Section titled “三、先用同一条文本构造三种训练样本”这一段代码的目标很直接:
- 给同一条句子
- 分别生成 Causal LM、Masked LM、Span Corruption 三种训练样本
这样你能非常直观地看到:
- “目标不同”到底意味着什么
tokens = "transformer models learn patterns from large text corpora".split()
def build_causal_example(tokens): inputs = tokens[:-1] labels = tokens[1:] return inputs, labels
def build_masked_example(tokens, mask_positions): masked = tokens[:] labels = {} for pos in mask_positions: labels[pos] = masked[pos] masked[pos] = "[MASK]" return masked, labels
def build_span_corruption(tokens, start, end): corrupted_input = tokens[:start] + ["<extra_id_0>"] + tokens[end:] target = ["<extra_id_0>"] + tokens[start:end] + ["<extra_id_1>"] return corrupted_input, target
causal_inputs, causal_labels = build_causal_example(tokens)masked_inputs, masked_labels = build_masked_example(tokens, mask_positions=[2, 5])span_inputs, span_target = build_span_corruption(tokens, start=2, end=5)
print("causal inputs :", causal_inputs)print("causal labels :", causal_labels)print()print("masked inputs :", masked_inputs)print("masked labels :", masked_labels)print()print("span inputs :", span_inputs)print("span target :", span_target)预期输出:
causal inputs : ['transformer', 'models', 'learn', 'patterns', 'from', 'large', 'text']causal labels : ['models', 'learn', 'patterns', 'from', 'large', 'text', 'corpora']
masked inputs : ['transformer', 'models', '[MASK]', 'patterns', 'from', '[MASK]', 'text', 'corpora']masked labels : {2: 'learn', 5: 'large'}
span inputs : ['transformer', 'models', '<extra_id_0>', 'large', 'text', 'corpora']span target : ['<extra_id_0>', 'learn', 'patterns', 'from', '<extra_id_1>']这段代码最该看哪里?
Section titled “这段代码最该看哪里?”先看这三件事:
- 输入被改成了什么样
- 标签到底让模型学什么
- 为什么同一句话会被组织成完全不同的训练任务
如果这一点看懂了, 你就会明白为什么:
- GPT、BERT、T5 最后能力画像不同
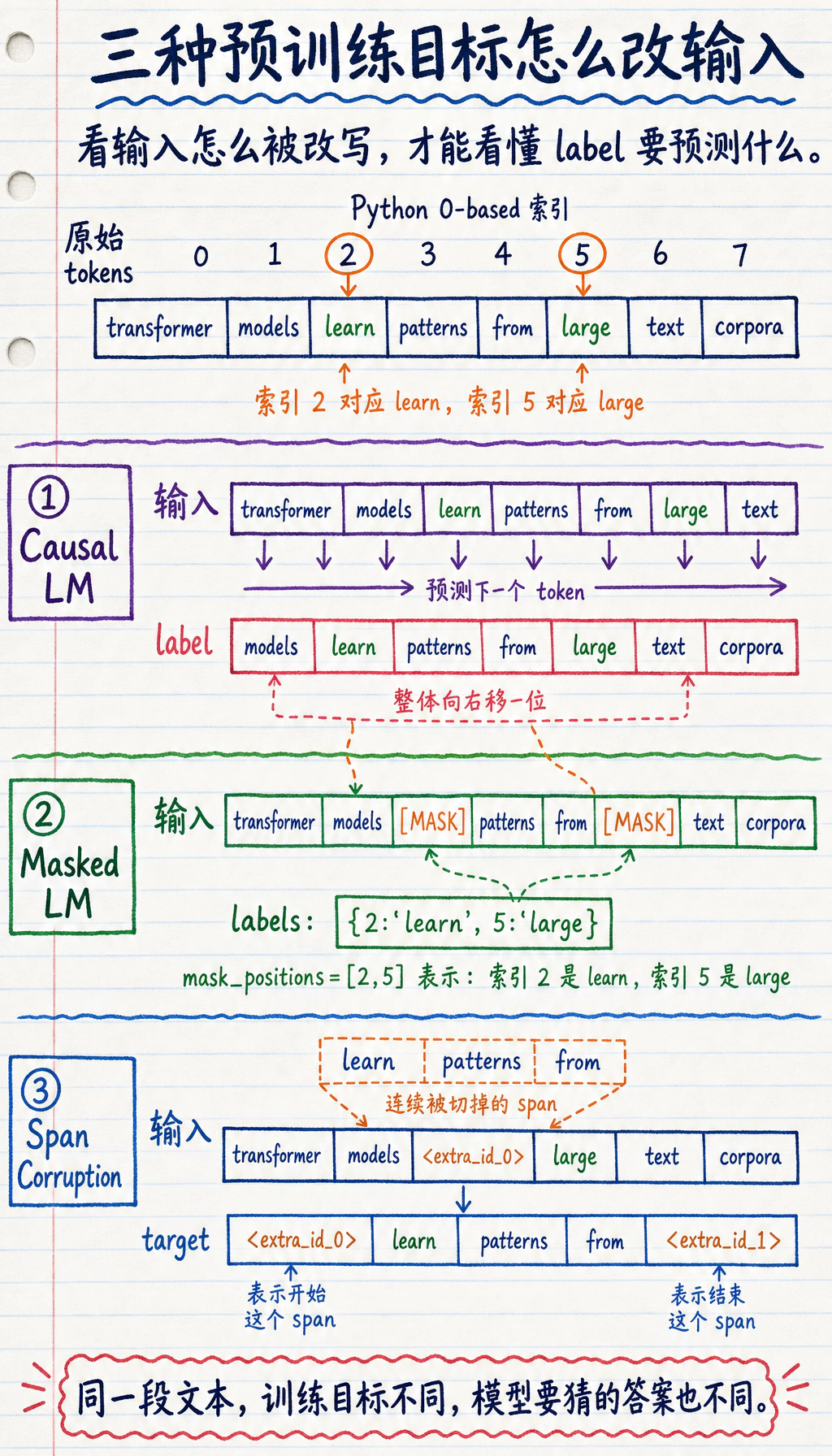
因果语言模型(Causal LM)的标签为什么是右移一位?
Section titled “因果语言模型(Causal LM)的标签为什么是右移一位?”因为它在做的就是:
- 给前文,猜下一个 token
所以最自然的训练数据组织就是:
- 输入:
x_1 ... x_{t-1} - 标签:
x_2 ... x_t
为什么片段破坏(Span Corruption)常被看得更“通用”?
Section titled “为什么片段破坏(Span Corruption)常被看得更“通用”?”因为它比单点 mask 更接近真实文本变换。 模型不仅要恢复一个词, 而是要补回一段缺失内容。
这会让它更自然地走向:
- text-to-text
这也是 T5 路线很重要的原因。
再看一个最小“同一句话三种训练目标的对比表”
Section titled “再看一个最小“同一句话三种训练目标的对比表””| 方法 | 输入 | 标签 | 先记住 |
|---|---|---|---|
| Causal LM | 看到前文 | 预测下一个 token | 更像续写 |
| Masked LM | 中间挖空 | 恢复被遮掉的 token | 更像补空题 |
| Span Corruption | 挖掉一整段 | 恢复整段内容 | 更像文本修复/改写 |
这个表特别适合初学者,因为它能把:
- 名字
- 输入形式
- 标签形式
- 最终能力倾向
放在同一张图里看。
四、这些目标分别更擅长什么?
Section titled “四、这些目标分别更擅长什么?”因果语言模型(Causal LM):生成、续写、对话
Section titled “因果语言模型(Causal LM):生成、续写、对话”这类目标和后续生成任务高度一致, 所以特别适合:
- 聊天
- 写作
- 代码补全
- 长文本续写
掩码语言模型(Masked LM):表示学习和理解
Section titled “掩码语言模型(Masked LM):表示学习和理解”因为模型能同时看到左右上下文, 所以很适合:
- 分类
- 检索编码
- 语义匹配
- 抽取任务
片段破坏(Span Corruption):输入到输出映射
Section titled “片段破坏(Span Corruption):输入到输出映射”如果你想要模型自然地做:
- 摘要
- 改写
- 翻译
- 问答生成
这类去噪和 seq2seq 目标会更顺手。
第一次学这节时,最稳的默认顺序
Section titled “第一次学这节时,最稳的默认顺序”更稳的顺序通常是:
- 先别急着记缩写
- 先看输入被改成什么样
- 再看标签到底让模型学什么
- 最后再看这种训练目标和后续任务有什么关系
这样会比一上来就背:
- CLM
- MLM
- span corruption
更容易真正看懂区别。
五、预训练目标不是独立存在的,它和架构绑在一起
Section titled “五、预训练目标不是独立存在的,它和架构绑在一起”为什么仅解码器常配因果语言模型(Causal LM)?
Section titled “为什么仅解码器常配因果语言模型(Causal LM)?”因为两者完全一致:
- 解码器只能看过去
- causal LM 也要求只能看过去
训练和生成闭环非常自然。
为什么仅编码器常配掩码语言模型(Masked LM)?
Section titled “为什么仅编码器常配掩码语言模型(Masked LM)?”因为 encoder 擅长双向建模。 既然它能看全句,就很适合做:
- 被 mask 位置的恢复
为什么编码器-解码器常配去噪目标?
Section titled “为什么编码器-解码器常配去噪目标?”因为这类结构天然适合:
- 输入一段东西
- 输出另一段东西
所以 span corruption、denoising、文本到文本训练都很搭。
六、除了经典目标,还会有什么变化?
Section titled “六、除了经典目标,还会有什么变化?”前缀语言模型(Prefix LM):部分双向、部分因果
Section titled “前缀语言模型(Prefix LM):部分双向、部分因果”有些方法会让输入前半段可以双向看, 但生成段仍然保持因果约束。
这类目标适合:
- 既要读上下文
- 又要生成续写
多模态预训练:输入不只是一串文本
Section titled “多模态预训练:输入不只是一串文本”如果输入同时包含:
- 图像
- 音频
- 视频
那目标就会变成:
- 跨模态对齐
- 图文生成
- 多模态理解
虽然形式更复杂,但核心仍然一样:
- 训练目标决定模型优先学什么
自监督目标不代表完全“无偏”
Section titled “自监督目标不代表完全“无偏””即使标签是自动构造的, 目标函数本身也在给模型施加偏好。
例如:
- 更偏生成
- 更偏理解
- 更偏结构恢复
这也是为什么预训练目标本身也是设计选择。
七、最容易踩的误区
Section titled “七、最容易踩的误区”误区一:预训练目标只是前期细节,后面微调会解决一切
Section titled “误区一:预训练目标只是前期细节,后面微调会解决一切”不对。 预训练目标会给模型打下长期能力偏向。
误区二:掩码语言模型(Masked LM)比因果语言模型(Causal LM)更高级,或者反过来
Section titled “误区二:掩码语言模型(Masked LM)比因果语言模型(Causal LM)更高级,或者反过来”两者不是等级关系, 而是针对不同路线的设计。
误区三:只记名字,不看标签长什么样
Section titled “误区三:只记名字,不看标签长什么样”真正的理解是:
- 输入怎么组织
- 标签怎么构造
- 模型被要求学什么
如果把它做成笔记或讲义,最值得展示什么
Section titled “如果把它做成笔记或讲义,最值得展示什么”最值得展示的通常不是:
- 只列三个缩写
而是:
- 同一句话被改造成三种训练样本
- 三种方法的输入 / 标签对比
- 每种目标更偏向学什么能力
- 它们和 GPT / BERT / T5 为什么能对应起来
这样别人会更容易看出:
- 你理解的是“训练目标如何塑造能力”
- 不只是记住方法名
学完这一页,至少保留这张证据卡:
- 目标
- 因果语言模型、掩码语言模型或 seq2seq 目标
- 训练样本
- 从同一段文本构造的输入和目标
- 架构匹配
- 目标与 encoder/decoder 模式相符
- 行为效果
- 目标教模型学会做什么
- 局限
- 预训练目标并不等同于指令遵循
这一节最重要的,不是背下 CLM / MLM / Span Corruption 这几个缩写,
而是抓住一条主线:
预训练目标本质上是在规定模型每天反复练什么,而模型最后最擅长的,通常就是它被反复练得最多的那类能力。
这条主线一旦建立起来, 你看后面的架构选择、微调方式和任务迁移,就会更顺。
- 把示例中的句子换成你自己的句子,再分别生成三种训练样本。
- 用自己的话解释:为什么 Causal LM 更适合开放式生成?
- 为什么说 Masked LM 更像“补空题”,而不是“续写题”?
- 想一想:如果你的目标是做一个强摘要模型,你会更偏向哪类预训练目标?为什么?
参考实现与讲解
- 好的答案应体现同一段文本可以变成不同训练信号:Causal LM 做 next-token prediction,Masked LM 做被遮盖 token 的恢复,sequence-to-sequence 目标做输入到输出的重构。
- Causal LM 训练模型根据前缀逐 token 续写。这正好匹配开放式生成、聊天、代码补全等从左到右产生输出的任务。
- Masked LM 能看到被遮盖位置左右两侧的上下文,再预测中间缺失片段,所以它更像补空题,而不是生成未知的后续文本。
- 做摘要时,sequence-to-sequence denoising 或 encoder-decoder 类目标通常更自然,因为它训练模型读取输入并生成压缩输出。Causal LM 经过指令微调后也能摘要,但预训练目标本身不如前者直接匹配。