7.3.6 模型规模与计算
- 理解参数规模、上下文长度和计算成本之间的关系
- 理解为什么训练期和推理期的成本结构不一样
- 通过一个可运行示例学会做参数量和 KV cache 的粗略估算
- 建立“模型为什么不能无限做大”的现实判断
一、参数量只是第一层表象
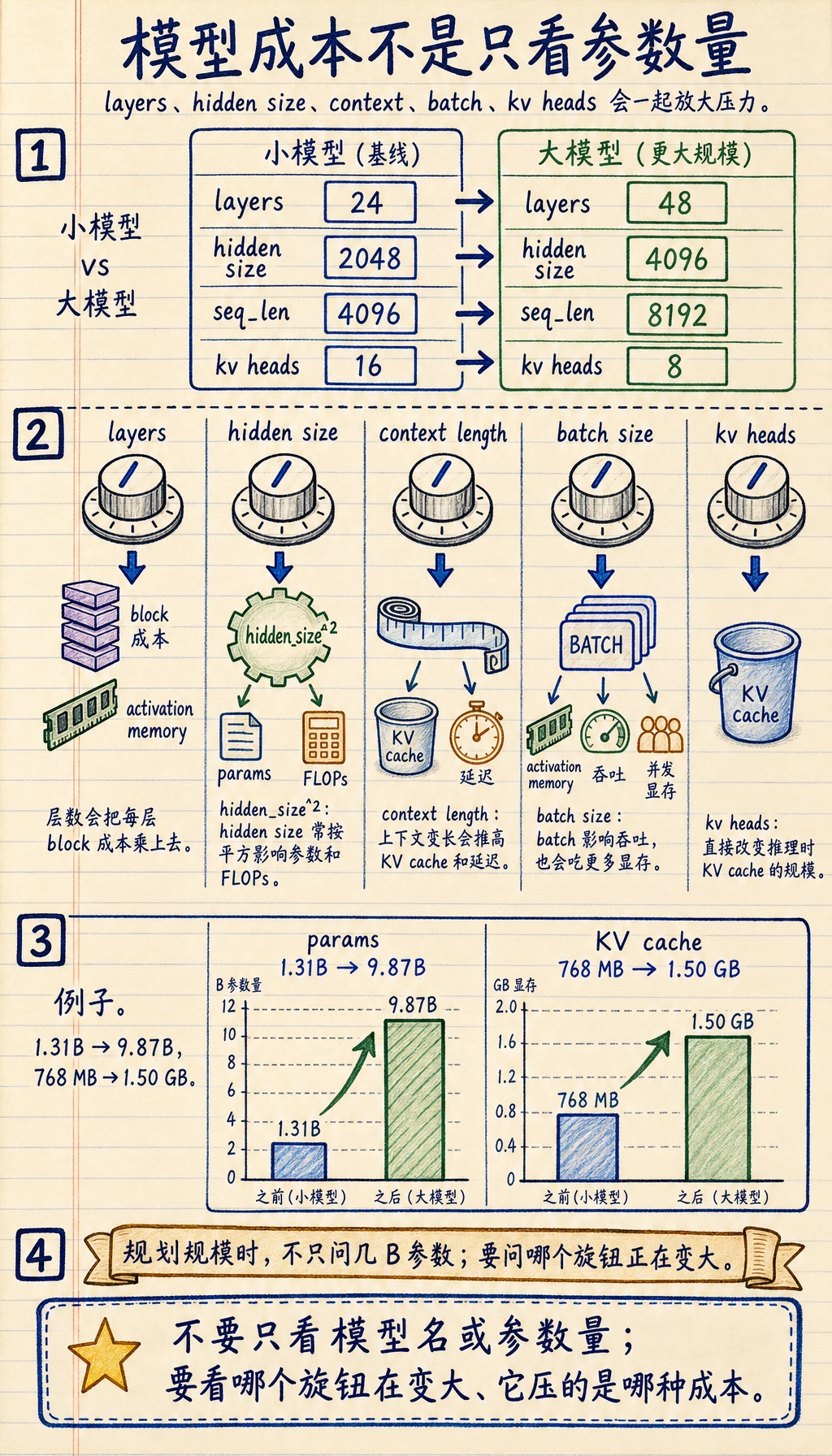
Section titled “一、参数量只是第一层表象”为什么大家喜欢用 7B / 70B 说模型?
Section titled “为什么大家喜欢用 7B / 70B 说模型?”因为它最直观。 参数量确实能粗略反映模型容量:
- 参数越多,通常表达能力上限越高
但这只是第一层。
同样是大模型,成本还取决于很多别的维度
Section titled “同样是大模型,成本还取决于很多别的维度”例如两个模型都写成 7B,
它们仍然可能因为下面这些因素差很多:
- 层数不同
- hidden size 不同
- head 数不同
- 上下文长度 不同
- 是否用 GQA / MoE
所以参数量不是没用, 而是不能单独看。
一个类比:建筑面积不是总成本
Section titled “一个类比:建筑面积不是总成本”你可以把参数量理解成房子的总面积。 但真正花钱的还包括:
- 楼层结构
- 装修复杂度
- 采暖和维护成本
同样,大模型真正的计算成本,也不只是参数个数。
二、参数量大概是怎么来的?
Section titled “二、参数量大概是怎么来的?”一个解码器块里,主要大头是注意力和 FFN
Section titled “一个解码器块里,主要大头是注意力和 FFN”粗略估算时,可以先记住两块主要成本:
- Attention projection
- FFN projection
在很多 decoder-only 模型里, FFN 的参数量甚至会比注意力更大。
一个很好用的粗略公式
Section titled “一个很好用的粗略公式”对于一个标准 decoder block, 可以用下面的近似直觉:
- Attention 相关大约是
4 * hidden^2 - FFN 相关大约是
8 * hidden^2
所以单层大约可以近似成:
12 * hidden^2
再乘层数, 就能得到一个很有用的第一层粗估。
为什么只是粗估也有价值?
Section titled “为什么只是粗估也有价值?”因为工程决策一开始并不需要精确到个位数。 更重要的是:
- 大概在什么量级
- 哪一部分是大头
- 改哪个超参会最明显地抬高成本
三、先跑一个真正有用的估算脚本
Section titled “三、先跑一个真正有用的估算脚本”下面这个脚本会估算两件现实中非常常用的东西:
- 一个仅解码器模型的大致参数量
- 推理时 KV cache 的大致占用
def approx_decoder_params(num_layers, hidden_size, ffn_multiplier=4, vocab_size=50000): attention_params = 4 * hidden_size * hidden_size ffn_params = 2 * hidden_size * (hidden_size * ffn_multiplier) norm_params = 4 * hidden_size block_params = attention_params + ffn_params + norm_params embedding_params = vocab_size * hidden_size total = num_layers * block_params + embedding_params return total
def kv_cache_bytes( num_layers, seq_len, batch_size, num_kv_heads, head_dim, dtype_bytes=2,): # 2 代表 K 和 V 两份缓存 return num_layers * batch_size * seq_len * num_kv_heads * head_dim * 2 * dtype_bytes
def human_readable(num_bytes): units = ["B", "KB", "MB", "GB", "TB"] value = float(num_bytes) for unit in units: if value < 1024 or unit == units[-1]: return f"{value:.2f} {unit}" value /= 1024
configs = [ { "name": "small", "layers": 24, "hidden": 2048, "kv_heads": 16, "head_dim": 128, "seq_len": 4096, }, { "name": "large", "layers": 48, "hidden": 4096, "kv_heads": 8, "head_dim": 128, "seq_len": 8192, },]
for cfg in configs: params = approx_decoder_params(cfg["layers"], cfg["hidden"]) kv_bytes = kv_cache_bytes( num_layers=cfg["layers"], seq_len=cfg["seq_len"], batch_size=1, num_kv_heads=cfg["kv_heads"], head_dim=cfg["head_dim"], ) print("-" * 60) print("model :", cfg["name"]) print("rough params:", f"{params / 1e9:.2f}B") print("kv cache :", human_readable(kv_bytes))预期输出:
------------------------------------------------------------model : smallrough params: 1.31Bkv cache : 768.00 MB------------------------------------------------------------model : largerough params: 9.87Bkv cache : 1.50 GB
这段代码最值得带走的点是什么?
Section titled “这段代码最值得带走的点是什么?”第一点:
- 参数量和
hidden_size^2强相关
这意味着 hidden size 一旦变大, 成本抬升会非常快。
第二点:
- KV cache 会跟
layers * seq_len * kv_heads * head_dim一起涨
这就是为什么上下文长度和推理内存会互相牵动。
为什么 large 模型的压力不只是参数翻倍?
Section titled “为什么 large 模型的压力不只是参数翻倍?”因为你会发现很多项是一起涨的:
- 层数增加
- hidden size 增加
- seq_len 增加
这些因素叠在一起后, 训练和推理成本都会明显上去。
为什么 GQA / MQA 会缓解推理压力?
Section titled “为什么 GQA / MQA 会缓解推理压力?”因为它们直接减少了:
num_kv_heads
而这正是 KV cache 公式里的核心项之一。
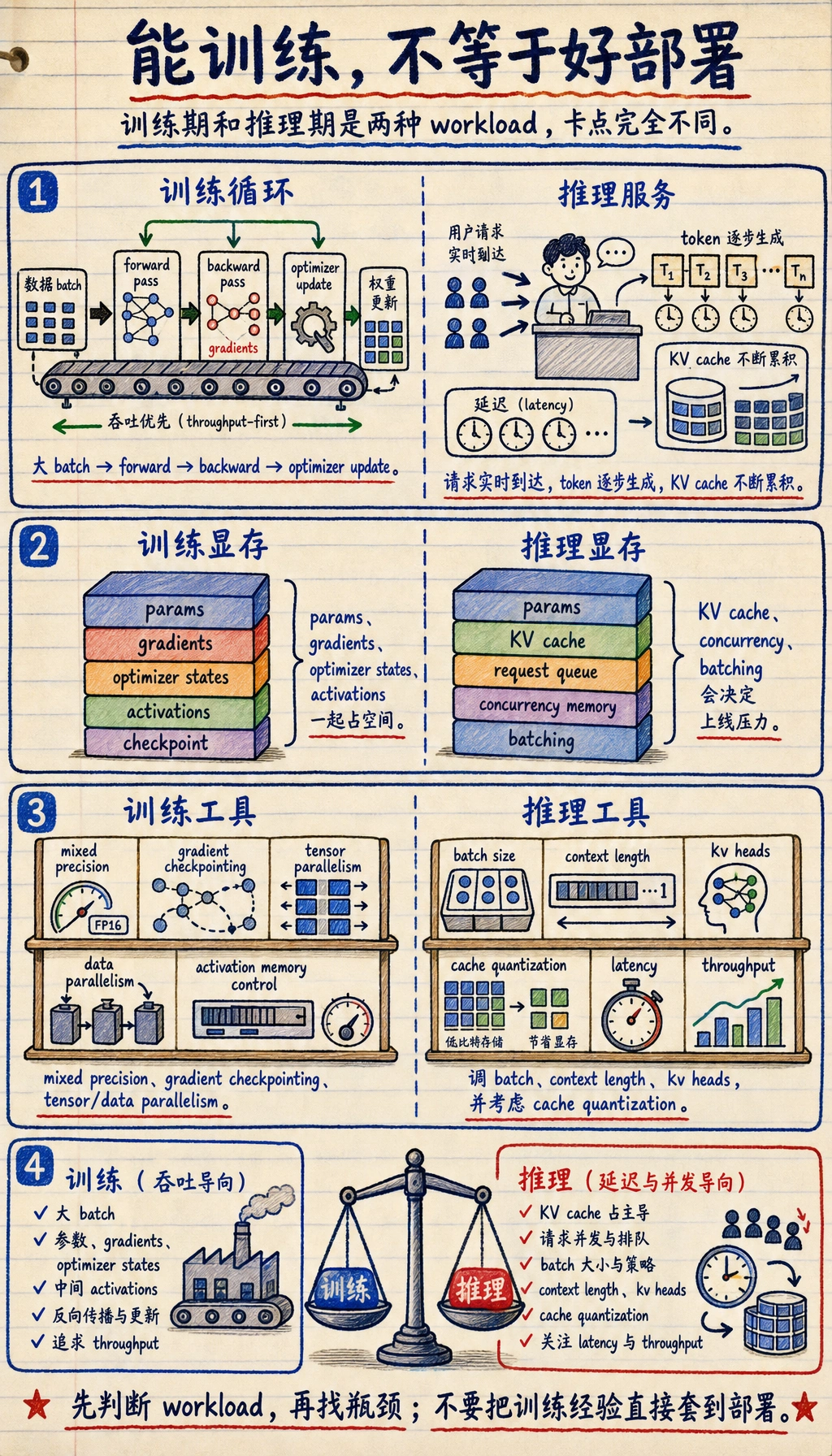
四、训练期和推理期到底哪里不一样?
Section titled “四、训练期和推理期到底哪里不一样?”训练期最常被什么卡住?
Section titled “训练期最常被什么卡住?”训练期常见瓶颈包括:
- 参数本体
- 梯度
- 优化器状态
- 中间激活
所以训练时,你会特别关心:
- mixed precision
- gradient checkpointing
- 张量并行 / 数据并行
- activation memory
推理期最常被什么卡住?
Section titled “推理期最常被什么卡住?”推理期的核心压力更常来自:
- KV cache
- 吞吐
- 单请求延迟
- 并发下的显存
所以你会更关心:
- batch 怎么设
- 上下文多长
- kv heads 有多少
- cache 能不能量化
为什么同一模型“能训练”不等于“好部署”?
Section titled “为什么同一模型“能训练”不等于“好部署”?”因为训练和推理根本不是同一种 workload。
训练像是:
- 大批量、持续更新、吞吐优先
推理更像是:
- 实时响应、缓存累积、延迟敏感
这就是为什么有些模型训练方案可行, 部署时却仍然非常痛苦。
五、规模化不是越大越好,而是越大越贵
Section titled “五、规模化不是越大越好,而是越大越贵”参数增长带来的是能力机会,不是白送效果
Section titled “参数增长带来的是能力机会,不是白送效果”参数变大通常会带来更高的表达上限, 但前提是你还得有:
- 足够的数据
- 足够的训练 token
- 足够的算力
否则模型只是“更大”,不一定“更值”。
上下文变长也不是白送收益
Section titled “上下文变长也不是白送收益”上下文长度增加会带来:
- 更多可用信息
但也会带来:
- 更高注意力开销
- 更大 KV cache
- 更难稳定利用长距离信息
所以“支持 128k”不等于“128k 就一定都有效”。
扩规模常见的三个现实问题
Section titled “扩规模常见的三个现实问题”- 训练成本会急剧上升
- 推理服务成本会同步增加
- 数据和训练 token 不够时,边际收益会下降
所以规模化的本质是:
- 在能力、成本和数据之间找平衡
六、一个非常实用的判断顺序
Section titled “六、一个非常实用的判断顺序”如果你在训练端卡住
Section titled “如果你在训练端卡住”先看:
- hidden size 是否太激进
- batch 和 seq_len 是否太高
- 中间激活是否是主要瓶颈
如果你在推理端卡住
Section titled “如果你在推理端卡住”先看:
- 上下文长度
- 并发量
- kv cache 大小
- 是否能用 GQA / MQA / cache quantization
如果你在规划模型规模
Section titled “如果你在规划模型规模”先问:
- 我的数据规模能不能支撑它?
- 训练预算撑不撑得住?
- 上线后的推理成本能不能接受?
如果这三件事没有一起想, 模型规划很容易只剩“越大越好”的幻觉。
七、常见误区
Section titled “七、常见误区”误区一:只要参数大,效果一定好
Section titled “误区一:只要参数大,效果一定好”不完整。 参数量只是容量,不是自动兑现的效果。
误区二:推理成本只和参数量有关
Section titled “误区二:推理成本只和参数量有关”错。 上下文长度和 KV cache 往往同样关键。
误区三:训练显存和推理显存是一回事
Section titled “误区三:训练显存和推理显存是一回事”不是。 两者的内存构成和瓶颈点都不同。
学完这一页,至少保留这张证据卡:
- 参数
- 粗略参数量估计和主要贡献项
- 训练成本
- 前向 + 反向 + 优化器状态
- 推理成本
- prefill、decode、KV cache、输出长度
- 瓶颈
- 内存、延迟、吞吐量或质量
- 决策
- 根据证据选择更小模型、量化、批处理或检索
这节课最重要的不是记住某个模型是多少 B, 而是建立一套更真实的语言:
模型规模 = 参数容量,计算成本 = 参数、层数、hidden、上下文长度、KV cache、批量和工程实现一起决定。
当你能把这些因素一起看时, 你对“大模型为什么贵、贵在哪里、该怎么控制”才算真正有了工程直觉。
- 把示例里的
seq_len从4096改到16384,观察 KV cache 占用怎么变化。 - 为什么说 hidden size 往往比很多人想象的更“贵”?
- 用自己的话解释:为什么训练能跑通,不代表部署一定轻松?
- 如果你要做一个长对话服务,除了参数量,你最先还会关心哪些指标?
参考实现与讲解
- KV cache 大致随序列长度、层数、batch size 和 key-value 头维度线性增长。把
4096改到16384,序列长度这一项约增加 4 倍。 - Hidden size 会影响投影矩阵、FFN 宽度、激活显存和 attention 维度。增大它往往会同时抬高参数量和每个 token 的计算量。
- 训练可以离线进行,有计划好的 batch 和恢复窗口;部署则要面对延迟、并发、显存限制、上下文增长和用户流量波动。
- 首先应看延迟、吞吐量、每个请求的 KV cache 显存、最大并发会话、prefill/decode 速度、上下文保留质量,以及每个有效回答的成本。