5 机器学习入门到实战
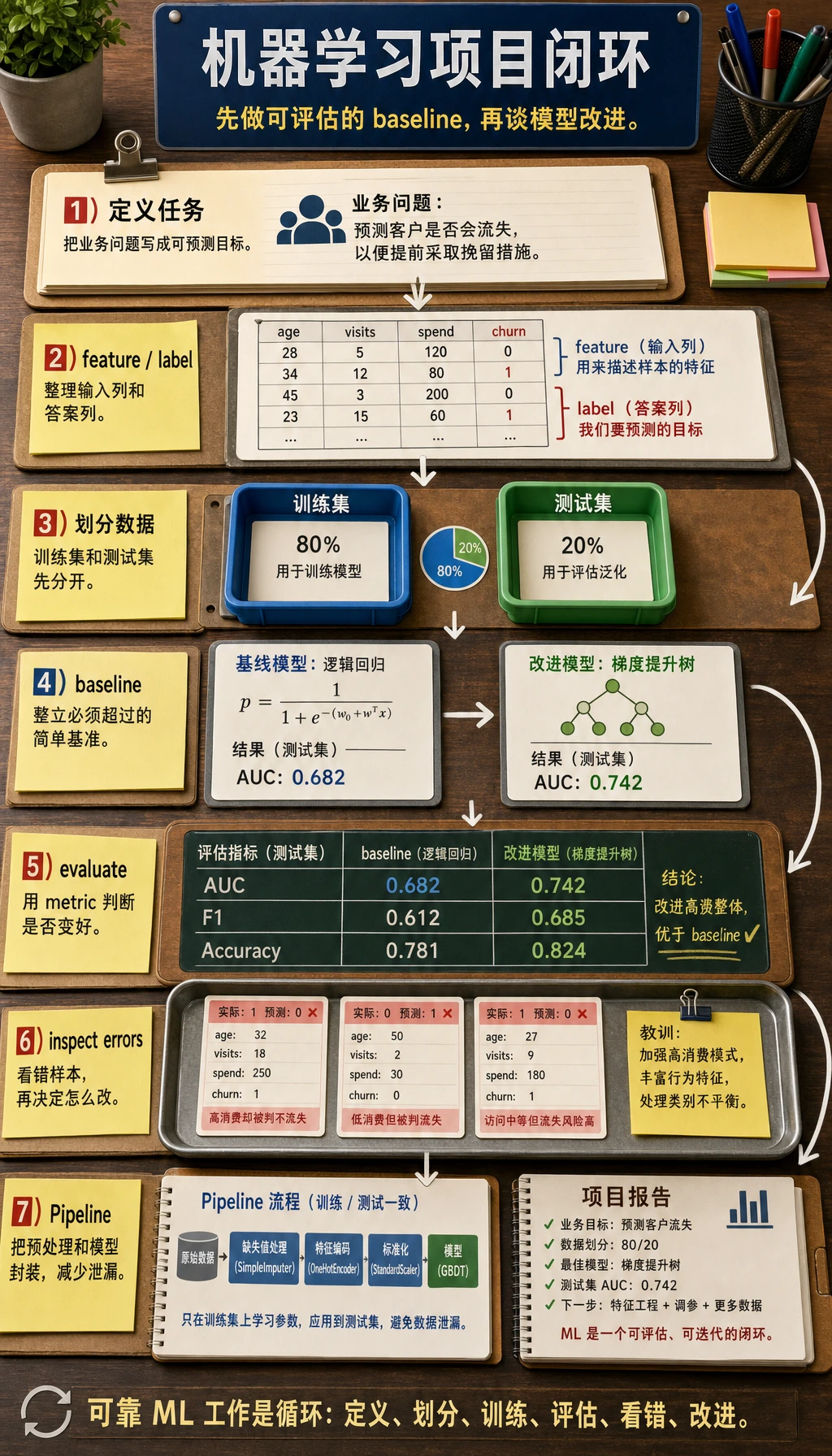
第 5 章只解决一件事:把数据问题变成可训练、可评估、可改进的机器学习项目。
你在主线中的位置
Section titled “你在主线中的位置”你已经知道数据怎样变成数字,也知道损失和梯度怎样解释模型改进。这一章会把这些想法变成实操:定义预测问题、建立 baseline、选择指标、查看错误,并且只在证据说明有效时才改进。
这是从数学直觉走向模型工程的桥。第 6 章会保留同样的证据习惯,但模型会变成用 tensor 和反向传播训练的神经网络。
先看建模闭环
Section titled “先看建模闭环”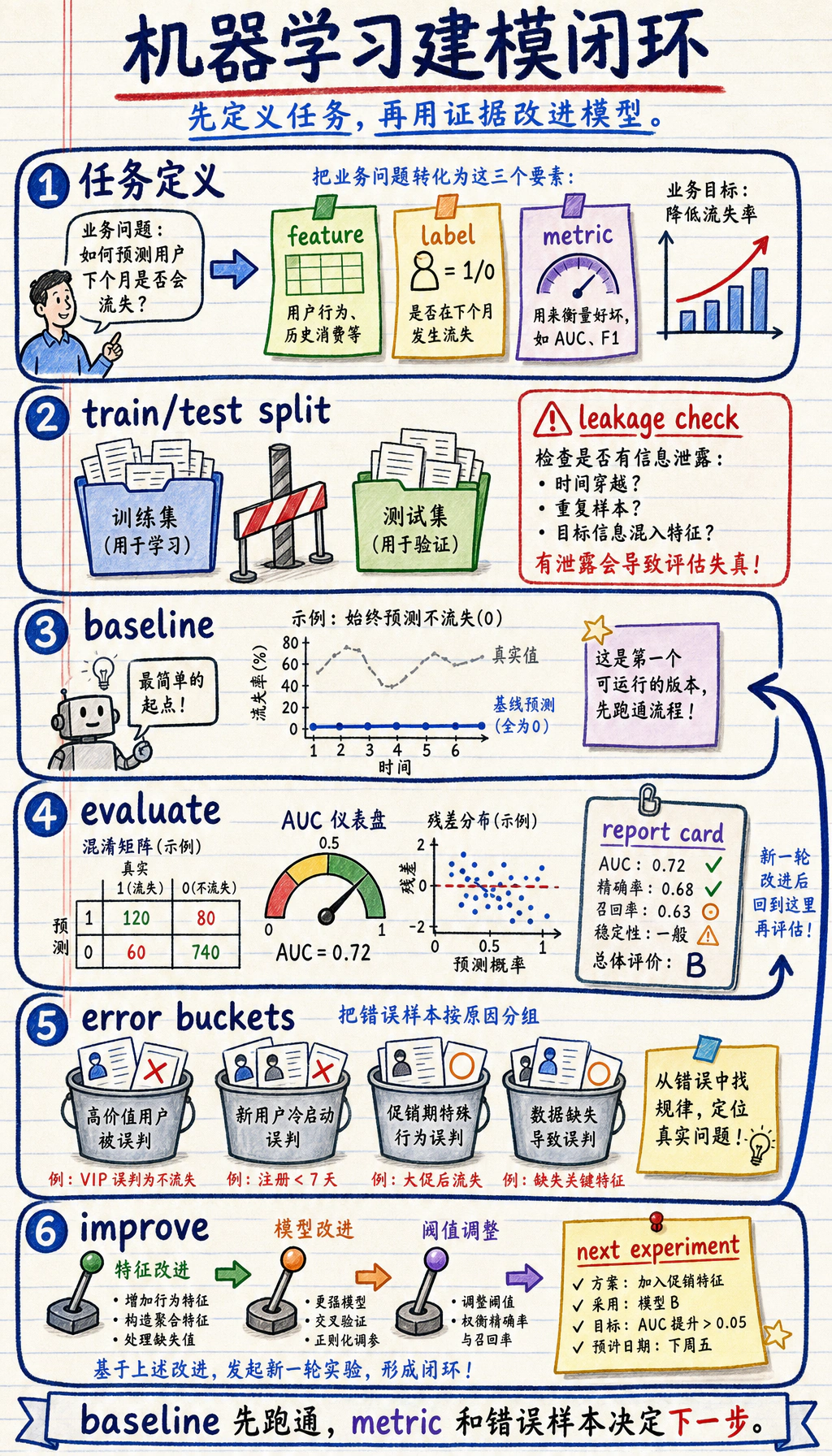
先看图。可靠的机器学习工作大多遵循这个闭环:
先做 baseline,再追模型名。baseline 能告诉你:后面的改动到底有没有带来真实提升。
学习顺序与任务表
Section titled “学习顺序与任务表”这份清单同时作为本章学习指南和任务单。先建立 baseline 和评估习惯,再扩大模型选择。
-
5.1 机器学习基础 跟着做:识别分类、回归、聚类、异常检测、特征、标签、训练/测试划分和 sklearn 流程。 留下证据:一份问题定义说明。
-
5.1.5 机器学习历史 跟着做:可选背景,浏览经典算法为什么陆续出现。 留下证据:一条“这个算法为什么存在”的说明。
-
5.2 监督学习 跟着做:先跑回归和分类样例,再比较多个模型。 留下证据:一个 baseline 分数和一个改进分数。
-
5.3 无监督学习 跟着做:没有标签时尝试聚类、降维和异常检测。 留下证据:一张图或一段聚类解释。
-
5.4 模型评估 跟着做:选择指标、使用交叉验证、诊断偏差/方差、谨慎调参。 留下证据:指标选择说明和错误样本。
-
5.5 特征工程 跟着做:处理缺失值、类别、缩放、特征构造、特征选择和 Pipeline。 留下证据:特征处理记录和泄漏检查。
-
5.6 项目 和 5.6.6 工作坊 跟着做:在房价、流失、分群或 Kaggle 前,先做可复现证据包。 留下证据:README、模型对比、错误分析和下一步计划。
必修主线、扩展和深度挑战
Section titled “必修主线、扩展和深度挑战”| 层级 | 现在学什么 | 怎么使用 |
|---|---|---|
| 必修核心 | 任务类型、训练/测试划分、baseline、指标、错误样本、泄漏检查、Pipeline | 后面会变成 LLM Prompt、RAG 检索和 Agent 行为的评估习惯 |
| 可选扩展 | 更多经典算法、机器学习历史、Kaggle 式迭代 | 项目需要更广的算法比较或竞赛式工作流时再回来 |
| 深度挑战 | 固定数据和指标,只改一个特征或模型选择,再解释前后错误变化 | 避免没有证据地频繁换模型 |
本章常见术语:
| 术语 | 含义 |
|---|---|
feature | 模型可以使用的输入列 |
label / target | 模型要学习预测的答案 |
baseline | 必须先超过的最简单模型或规则 |
metric | 衡量模型的尺子,例如 F1、AUC、MAE、RMSE |
leakage | 测试集或目标信息意外进入训练过程 |
Pipeline | 把预处理和模型封装在一起,降低泄漏风险 |
第一个可运行闭环
Section titled “第一个可运行闭环”如果还没有 sklearn,先安装:
python -m pip install scikit-learn然后运行下面这个自包含 baseline。它使用内置数据集,划分数据,训练 dummy baseline,再训练一个真实模型,并对比两者。
from sklearn.datasets import load_breast_cancerfrom sklearn.dummy import DummyClassifierfrom sklearn.linear_model import LogisticRegressionfrom sklearn.metrics import classification_reportfrom sklearn.model_selection import train_test_splitfrom sklearn.pipeline import make_pipelinefrom sklearn.preprocessing import StandardScaler
X, y = load_breast_cancer(return_X_y=True)X_train, X_test, y_train, y_test = train_test_split( X, y, test_size=0.2, random_state=42, stratify=y)
baseline = DummyClassifier(strategy="most_frequent")baseline.fit(X_train, y_train)print("Baseline")print(classification_report(y_test, baseline.predict(X_test), zero_division=0))
model = make_pipeline(StandardScaler(), LogisticRegression(max_iter=1000))model.fit(X_train, y_train)print("Logistic regression")print(classification_report(y_test, model.predict(X_test), zero_division=0))预期形态:
Baseline...Logistic regression...不要只比较最终分数。继续问:哪些类别容易,哪些类别难,真实场景里哪类错误最重要?
如何读这个输出
Section titled “如何读这个输出”- baseline 告诉你:一个几乎不学习模式的朴素模型能做到什么程度。
- Logistic regression 应该超过 baseline,但比总分更重要的是每个类别的 precision 和 recall。
- 如果某个类别 recall 很差,先检查这些漏判样本,再考虑换模型。
- 比较下一轮实验时,要固定数据划分、指标和失败样本。
| 层级 | 你能证明什么 |
|---|---|
| 最低通过 | 能说出任务类型、划分数据、训练 baseline,并读懂分数。 |
| 项目可用 | 能解释为什么选这个指标,并展示一条错误样本,而不是只相信一个分数。 |
| 深度检查 | 能检查泄漏、比较两种特征方案,并说明真实产品或数据更新后会有什么变化。 |
失败样本练习
Section titled “失败样本练习”离开本章前,保存一个错误预测或解释不好的聚类样本。用这个格式写:
case_id:input_summary:true_or_expected:model_output:why_it_matters:next_controlled_change:这条小失败备注比再记一个模型名更有用。它会变成后面读深度学习曲线、Prompt 评估、RAG 检索错误和 Agent trace 的共同习惯。
学完这一页,至少保留这张证据卡:
- 建模循环
- 数据、特征、模型、指标、错误审查和下一次实验
- 工件
- 代码、分数、图表、流水线或项目 README
- 失败检查
- 泄漏、指标不匹配、划分不稳定、过拟合或业务目标不清晰
- 下一步动作
- 做一个受控实验,而不是一次改很多参数
- 期望产出
- 为进入深度学习做准备的可复现实验证据
| 现象 | 先检查什么 | 常见修复 |
|---|---|---|
| 分数高得奇怪 | 数据泄漏或训练/测试划分错误 | 训练前检查特征和切分方式 |
| 训练高、测试低 | 过拟合 | 简化模型、正则化或增加数据 |
| 所有模型都弱 | 标签差、特征弱或指标不合适 | 查看错误样本和标签定义 |
| 准确率不错但业务风险高 | 类别不平衡或漏判代价高 | 使用 recall、precision、F1、AUC 或阈值复盘 |
| 结果无法复现 | 随机种子、数据版本或依赖变化 | 固定 seed 并记录版本 |
能回答下面五个问题,就可以进入第 6 章:
- 这是分类、回归、聚类还是异常检测?
- baseline 是什么?真实模型必须超过哪个分数?
- 哪个指标匹配目标?什么时候准确率会误导?
- 你怎样检查数据泄漏?
- 模型擅长什么、不擅长什么、下一步先改哪里?
检查思路与讲解
- 先看目标列:预测类别就是分类,预测连续数值就是回归,没有标签时通常是聚类或异常检测。
- baseline 是最简单且可复现的模型或规则。真实模型只有在同一划分和同一指标下超过 baseline,才算有意义。
- 指标要由错误代价决定。类别不平衡,或某类错误代价特别高时,accuracy 很容易误导。
- 检查泄漏时,要问每个特征是否含有目标、未来、测试集或人工复核信息;这些信息预测时通常不存在。
- 合格的下一步应该只改一个因素,并写清一个弱点、一个证据样本和一个受控实验。
需要打印式清单时,打开 5.0 学习指南与任务单。下一章会从 sklearn 模型进入神经网络和深度学习训练。