13.3 模型与运行时决策
一个好的开源大模型项目,在第一次下载模型前就已经开始了。本节把模型选择变成书面决策,避免你把时间浪费在硬件、许可证、延迟目标或产品边界都撑不住的模型上。
本页解决什么
Section titled “本页解决什么”初学者常问:“哪个模型最好?”工程问题更具体:“哪个模型/运行时组合,足够支撑这个项目、这台机器、这个许可证约束和这条回滚路径?”
先用能证明项目行为的最小模型和最简单运行时。只有证据表明质量、上下文长度、吞吐、隐私或成本需要升级时,再往上走。
-
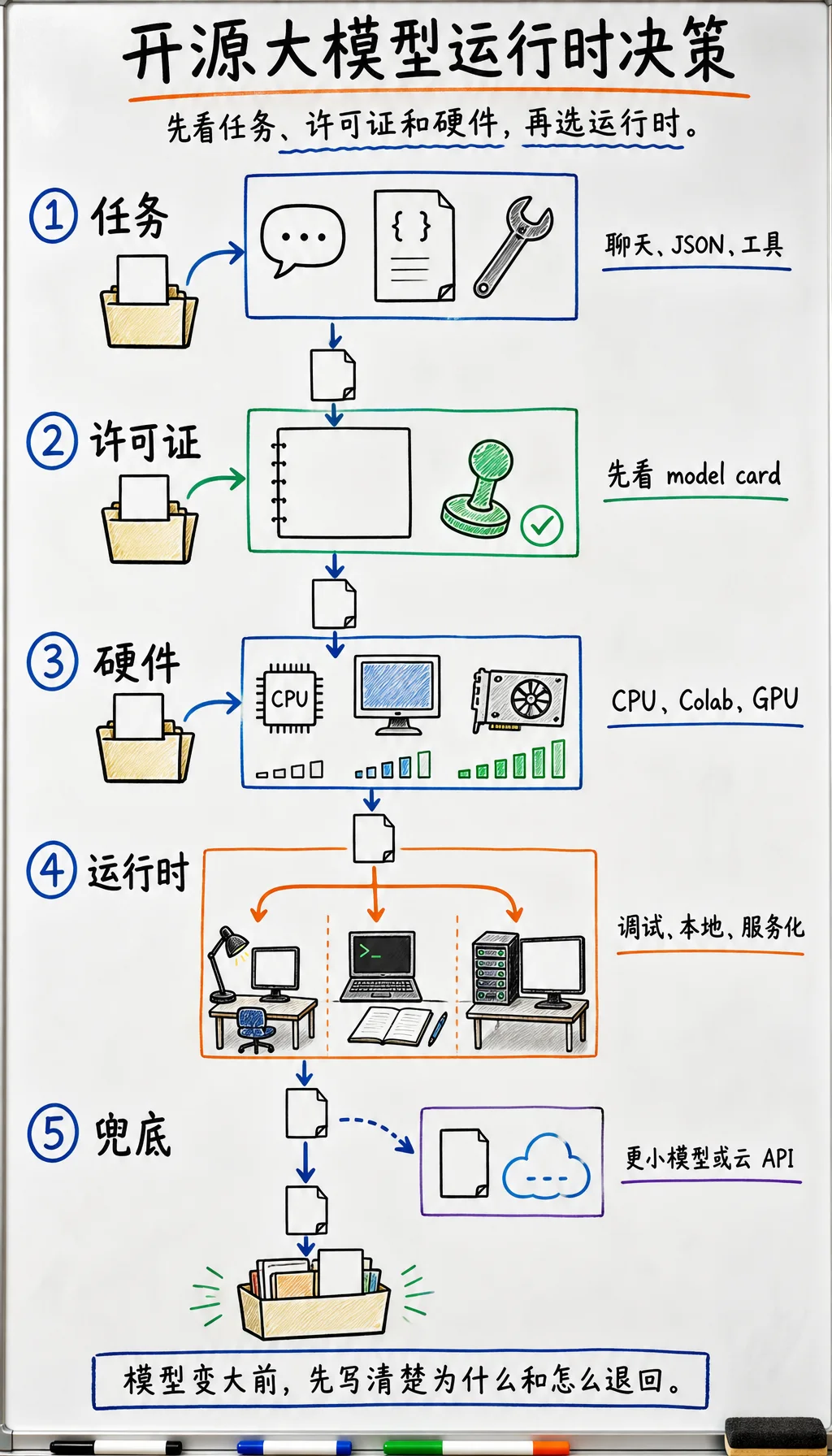
任务适配 判断项目需要聊天、抽取、代码、多语言、长上下文、工具调用,还是多模态行为。
-
许可证适配 在围绕模型构建系统前,先阅读 model card 和许可证。保留商业使用、再分发和数据使用限制说明。
-
硬件适配 下载前先估算显存/内存和磁盘。如果本地跑不动,就选择更小模型、量化、租 GPU 或云 API 兜底。
-
运行时适配 学习和调试用 Transformers,本地交付用 Ollama/LM Studio,CPU/边缘量化实验用 llama.cpp,服务化推理用 vLLM/SGLang。
-
证据适配 只有拿到模型版本、运行命令、首次输出、评估表和停止步骤,决策才算完成。
创建 model_runtime_decision.md:
# 模型与运行时决策
project_goal: support-operations SOP assistantmust_have: private document handling, Chinese/English answers, stable JSON outputnice_to_have: low latency, long context, OpenAI-compatible endpoint
candidate_1: Qwen2.5-0.5B-Instructlicense_note: check model card before deploymentruntime: vLLM when GPU is available, Transformers for first local testhardware_note: small enough for first experiment; still validate memoryrisk: quality may be too weak for complex SOP reasoning
candidate_2: 7B instruct modellicense_note: check commercial and redistribution termsruntime: vLLM or SGLang on rented GPUhardware_note: requires planned GPU budget and shutdown proofrisk: higher cost and slower iteration
fallback: cloud model API or RAG with current API modelwhy_now: prove the deployment loop before chasing larger modelsrejected_for_now: full fine-tuning, because eval failures are not proven yet具体模型名会变化,但决策结构不应该变化。
运行时选择规则
Section titled “运行时选择规则”需要看清 token、prompt 和 Python 行为时,从 Transformers 开始。 它容易调试,也贴近模型接口,但通常不是最终高吞吐服务。
目标是笔记本演示或非工程同伴交接时,用 Ollama 或 LM Studio。 它们降低安装门槛,但生产控制力也更少。
CPU、量化或边缘约束重要时,用 llama.cpp。 它适合小型本地实验,但仍然需要清晰 API 和评估方案。
项目需要 OpenAI 兼容服务和吞吐时,用 vLLM。 只有 GPU、驱动、内存和安全边界清楚后再进入这一步。
需要结构化生成或 agentic serving 模式时,用 SGLang。 它很强,但仍然要由项目需求驱动,而不是因为新奇。
分路线运行时卡片
Section titled “分路线运行时卡片”用这些卡片把三种计算路线分清楚。路线不同,第一轮能证明的东西也不同,所以每张卡都单独拆出模型、运行时、证据和升级信号。
本地 CPU
- 首个模型
sshleifer/tiny-gpt2或小型量化模型。- 运行时
- 用 Transformers 看清代码行为;用 llama.cpp 或 Ollama 做本地量化测试。
- 先证明什么
- 环境、下载、一次 prompt、评估脚本和本地 API 骨架。
- 升级信号
- 闭环已经可复现,但目标任务的质量明显不够。
免费 Colab
- 首个模型
- 先跑 tiny model,只有 GPU 可见时再换小型 instruct model。
- 运行时
- Transformers notebook,并把输出文件保存到可带回本地的位置。
- 先证明什么
- notebook 能重跑、输出能保存,GPU 只是机会而不是前提。
- 升级信号
- GPU 可见,并且固定评估样本支持尝试更大模型。
租 GPU
- 首个模型
- 先跑小型 instruct model,再考虑 7B 级模型。
- 运行时
- vLLM 或 SGLang,先绑定 localhost 或走 SSH tunnel。
- 先证明什么
- 明确显存、endpoint、评估表、延迟说明和关机证明。
- 升级信号
- 固定评估样本通过,而且需要服务行为,而不只是一次生成。
不要把三条路线当成同一种证明。本地 CPU 证明工作流,Colab 证明可搬运 notebook,租 GPU 证明可控服务和成本纪律。
写一个可运行的决策 helper
Section titled “写一个可运行的决策 helper”创建 choose_openllm_runtime.py。它不下载模型,只强迫决策依赖任务、隐私、路线和可用显存。
import jsonimport osfrom pathlib import Path
profile = { "task": os.environ.get("TASK", "course assistant"), "route": os.environ.get("ROUTE", "local_cpu"), "privacy": os.environ.get("PRIVACY", "private_docs"), "available_vram_gb": float(os.environ.get("VRAM_GB", "0")), "needs_service": os.environ.get("NEEDS_SERVICE", "no") == "yes",}
def choose(profile): route = profile["route"] vram = profile["available_vram_gb"]
if route == "local_cpu": return { "model": "sshleifer/tiny-gpt2 or a small quantized model", "runtime": "Transformers for code inspection; llama.cpp/Ollama for quantized local tests", "claim": "proves the workflow, not model quality", }
if route == "free_colab": return { "model": "tiny model first; small instruct model only if GPU is visible", "runtime": "Transformers notebook", "claim": "proves a portable notebook run, not stable serving", }
if route == "rented_gpu" and vram >= 16: runtime = "vLLM or SGLang" if profile["needs_service"] else "Transformers first, then vLLM" return { "model": "small instruct model before trying 7B-class", "runtime": runtime, "claim": "proves controlled serving, eval, latency, and shutdown", }
return { "model": "smaller model or cloud API fallback", "runtime": "do not start GPU serving yet", "claim": "current hardware route is not ready", }
decision = {"profile": profile, "decision": choose(profile)}Path("model_runtime_decision.json").write_text(json.dumps(decision, indent=2), encoding="utf-8")print(json.dumps(decision, indent=2))一次只跑一条路线:
ROUTE=local_cpu python choose_openllm_runtime.pyROUTE=free_colab python choose_openllm_runtime.pyROUTE=rented_gpu VRAM_GB=24 NEEDS_SERVICE=yes python choose_openllm_runtime.py输出不是最终架构,而是防止你在路线、内存、服务需求和证据主张不清楚时就追模型名。
从第 8 章或第 9 章选一个项目,写一段决策:
这个项目我会先用 _____ 和 _____,因为 _____。我暂时不用更大模型,因为 _____。只有当固定评估集显示 _____ 时,我才切换。判断思路与讲解
好的答案会把模型尺寸和运行时绑定到证据。例如:先用小型 instruct model 加 Transformers 或 Ollama,证明 prompt、RAG 上下文和输出 schema;只有同一组评估样本质量可接受,并且项目确实需要服务接口时,再切到 vLLM。在知道 prompt、RAG、schema 和量化之后还剩哪些失败前,不要直接选择 LoRA 或更大的 GPU。
- Model Decision
- 选择的模型、许可证说明、尺寸、上下文长度和暂不选择项
- Runtime Decision
- 选择的运行时、硬件理由和兜底运行时
- Hardware Note
- 本地 CPU/GPU 或租用 GPU 估算、磁盘和预计停止时间
- Eval Gate
- 支持切换模型或运行时的固定评估样本
- Expected Output
- model_runtime_decision.md、model_runtime_decision.json 和一条首次运行命令
如果你能解释为什么当前模型/运行时组合足够、什么证据会触发升级,以及哪些证据能避免“随机模型演示”变成不可控部署,就通过本节。