8.1.4 向量数据库
完成本节后,你将能够:
- 理解为什么 RAG 经常需要向量数据库
- 分清“向量”、“元数据”和“相似度检索”的关系
- 跑通一个最小可运行的向量检索示例
- 知道选择向量数据库时要关注哪些维度
一、为什么普通数据库不够用?
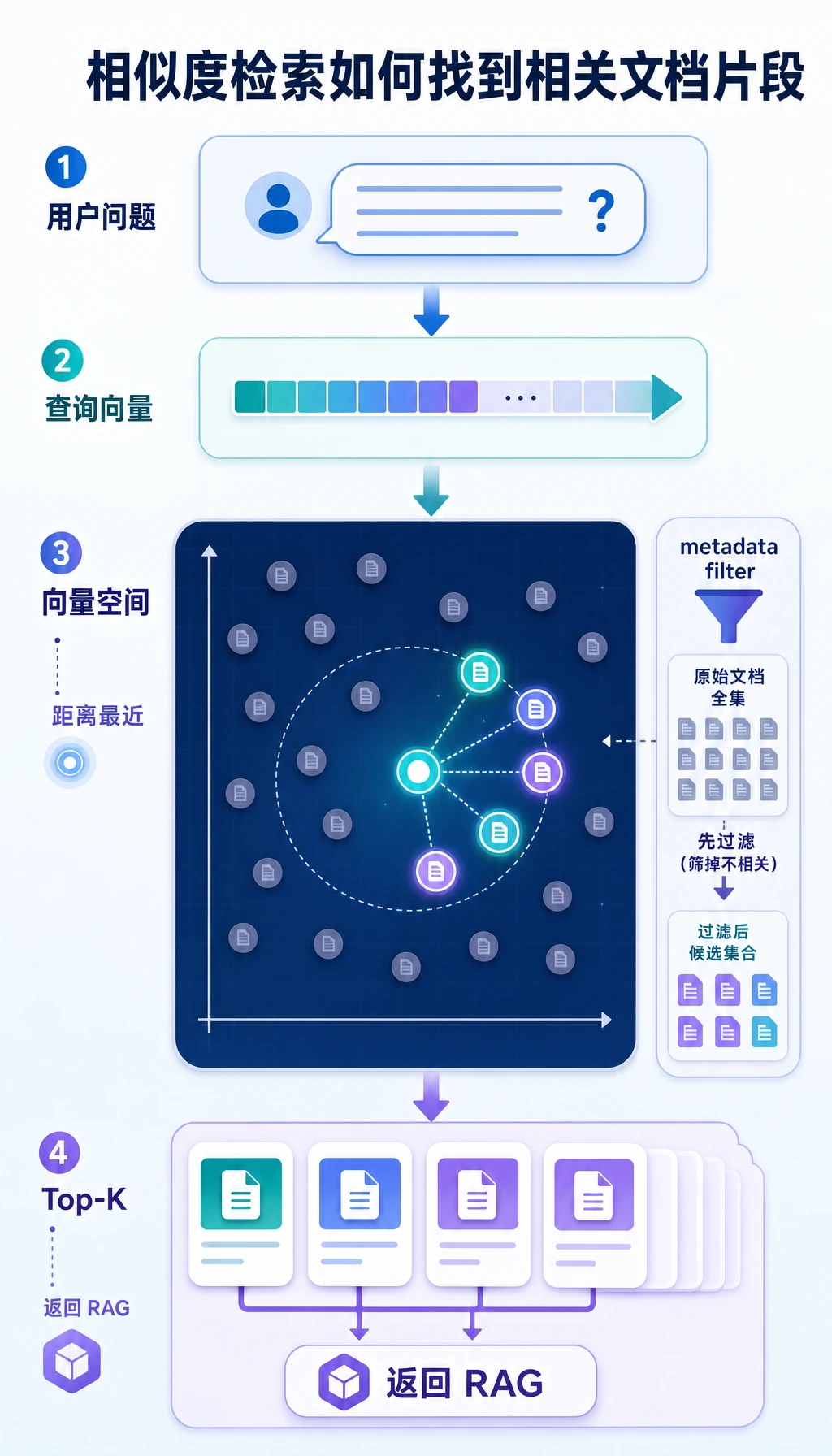
Section titled “一、为什么普通数据库不够用?”RAG 里要找的不是“完全相同”,而是“语义相近”
Section titled “RAG 里要找的不是“完全相同”,而是“语义相近””传统数据库擅长做:
- 精确匹配
- 条件过滤
- 关系查询
但 RAG 更常见的问题是:
用户问一句话,系统要找到“意思最接近”的文本块。
比如用户问:
“怎么退课?”
知识库里可能写的是:
“课程购买后 7 天内可申请退款”
这两句话字面不完全一样,但语义相关。 这就是向量检索擅长处理的场景。
先不要默认必须用向量数据库
Section titled “先不要默认必须用向量数据库”很多检索问题不一定一上来就需要向量库。先看你要找的东西属于哪一种:
| 需求 | 更自然的起点 | 为什么 |
|---|---|---|
| 按订单号、用户 ID、状态精确查询 | 普通数据库 | 条件明确,结构化字段最可靠 |
| 按关键词、标题、短语查文档 | 全文搜索 | 关键词匹配、倒排索引和高亮更直接 |
| 按“意思相近”找片段 | 向量数据库 | 用户问法和文档说法不一致时更有优势 |
| 既要语义相近,又要权限、版本、来源过滤 | 向量库 + 元数据过滤,或混合检索 | 真实 RAG 常常需要语义和业务条件同时成立 |
所以向量数据库不是替代所有数据库,而是补上“语义相似搜索”这块能力。真实系统里,经常会把普通数据库、全文搜索和向量检索组合起来。
向量数据库本质上是在管理“语义坐标”
Section titled “向量数据库本质上是在管理“语义坐标””你可以把每段文本的 embedding 想成一组坐标。 向量数据库做的事就是:
- 存下这些坐标
- 用户查询时,把问题也变成坐标
- 找离它最近的那些点
二、向量数据库里通常存什么?
Section titled “二、向量数据库里通常存什么?”不只是向量,还会存文本和元数据
Section titled “不只是向量,还会存文本和元数据”一条记录通常至少包含:
idvectortextmetadata
比如:
record = { "id": "doc_001", "vector": [0.2, 0.8, 0.1], "text": "课程购买后 7 天内可申请退款", "metadata": {"section": "退款政策", "source": "policy.pdf"}}
print(record)元数据为什么重要?
Section titled “元数据为什么重要?”因为很多时候你不只想“语义接近”,还想“满足业务过滤条件”。
例如:
- 只查
section=退款政策 - 只查某个产品版本
- 只查某个部门文档
所以向量数据库不是“只有向量”,而是“向量 + 文本 + 元数据”的组合管理。

三、一个最小可运行的向量检索器
Section titled “三、一个最小可运行的向量检索器”下面我们用 numpy 手写一个迷你向量库,让原理完全可见。
import numpy as np
records = [ { "id": "r1", "vector": np.array([0.95, 0.05, 0.10]), "text": "课程购买后 7 天内可申请退款", "metadata": {"section": "退款政策"} }, { "id": "r2", "vector": np.array([0.10, 0.95, 0.05]), "text": "完成结课项目后可获得证书", "metadata": {"section": "证书说明"} }, { "id": "r3", "vector": np.array([0.20, 0.80, 0.15]), "text": "通过结课测试后系统会发放证书", "metadata": {"section": "证书说明"} }]
query_vector = np.array([0.90, 0.10, 0.10])
def cosine_similarity(a, b): return float(np.dot(a, b) / (np.linalg.norm(a) * np.linalg.norm(b)))
results = []for item in records: score = cosine_similarity(query_vector, item["vector"]) results.append((score, item["id"], item["text"]))
for score, rid, text in sorted(results, reverse=True): print(rid, round(score, 4), text)预期输出:
r1 0.9983 课程购买后 7 天内可申请退款r3 0.3601 通过结课测试后系统会发放证书r2 0.218 完成结课项目后可获得证书这里 query_vector 可以理解成“用户问题的 embedding”。
四、加上元数据过滤
Section titled “四、加上元数据过滤”为什么过滤很常见?
Section titled “为什么过滤很常见?”因为很多企业知识库不是一池子乱搜,而是带边界的。
比如:
- 只查 HR 政策
- 只查某个产品文档
- 只查 2025 年后的版本
import numpy as np
records = [ { "id": "r1", "vector": np.array([0.95, 0.05, 0.10]), "text": "课程购买后 7 天内可申请退款", "metadata": {"section": "退款政策"} }, { "id": "r2", "vector": np.array([0.10, 0.95, 0.05]), "text": "完成结课项目后可获得证书", "metadata": {"section": "证书说明"} }, { "id": "r3", "vector": np.array([0.20, 0.80, 0.15]), "text": "通过结课测试后系统会发放证书", "metadata": {"section": "证书说明"} }]
query_vector = np.array([0.15, 0.90, 0.10])
def cosine_similarity(a, b): return float(np.dot(a, b) / (np.linalg.norm(a) * np.linalg.norm(b)))
target_section = "证书说明"
filtered_results = []for item in records: if item["metadata"]["section"] != target_section: continue score = cosine_similarity(query_vector, item["vector"]) filtered_results.append((score, item["text"]))
for score, text in sorted(filtered_results, reverse=True): print(round(score, 4), "->", text)预期输出:
0.9966 -> 完成结课项目后可获得证书0.9944 -> 通过结课测试后系统会发放证书这就是“相似度检索 + 业务过滤”的最小形态。
五、如果你的目标是“知识库驱动的 SOP 文档助手”,元数据至少要带哪些?
Section titled “五、如果你的目标是“知识库驱动的 SOP 文档助手”,元数据至少要带哪些?”这类项目里,向量数据库不只是拿来“语义找相似”, 还要支撑后面:
- 按主题筛
- 按政策 / 案例 / 清单筛
- 按内部资料 / 外部资料筛
- 最后做来源回溯
所以更适合新人的最小元数据集合通常是:
| 字段 | 它在帮你做什么 |
|---|---|
topic | 当前主题路由 |
content_type | 区分政策 / 处理案例 / 复核清单 |
source_origin | 区分内部资料 / 外部资料 |
page_or_slide | 生成时引用来源 |
team | 过滤支持团队或适用对象 |
一个很小的记录对象可以先写成:
record = { "id": "doc_001_chunk_03", "text": "如果确认重复扣费且退款窗口已过,应带交易证据升级给 billing support。", "metadata": { "topic": "退款升级", "content_type": "case", "source_origin": "internal", "page_or_slide": 3, "team": "support ops", },}
print(record)这个例子最值得新人注意的是:
- 向量库这一层其实已经在悄悄决定后面的 SOP 文档能不能稳定组装
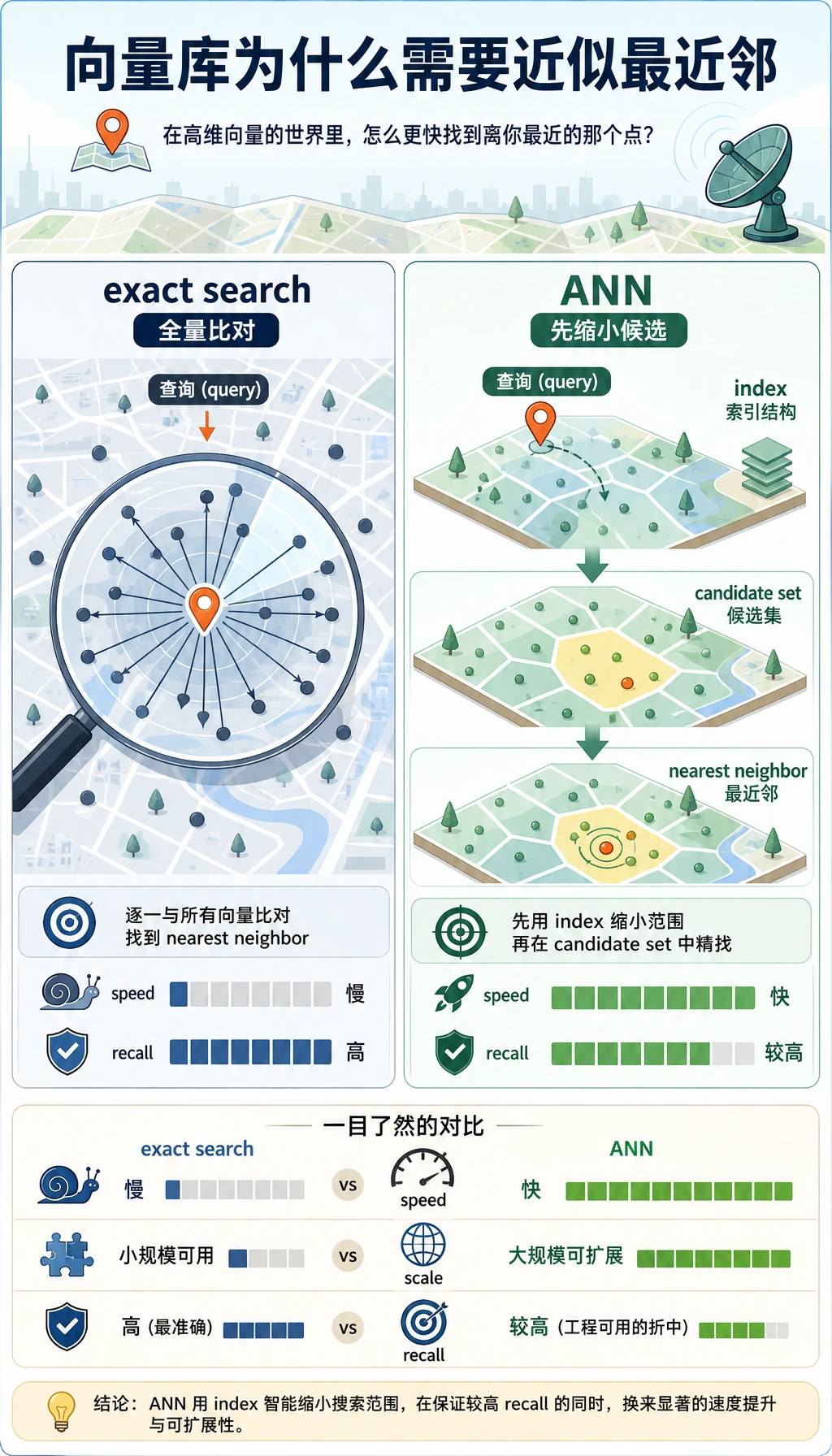
六、精确搜索和近似搜索有什么区别?
Section titled “六、精确搜索和近似搜索有什么区别?”就是把查询向量和所有向量都比一遍。
优点:
- 结果准确
缺点:
- 数据量大时速度慢
近似最近邻(ANN)
Section titled “近似最近邻(ANN)”真实向量数据库常用近似方法加速搜索。
你可以把它理解成:
不再地毯式逐一比对,而是先快速缩小候选范围,再找近邻。
优点:
- 速度快
代价:
- 可能不是绝对最优,但通常足够好
七、常见向量数据库 / 工具的角色
Section titled “七、常见向量数据库 / 工具的角色”轻量本地方案
Section titled “轻量本地方案”适合:
- 学习
- 原型验证
- 小规模项目
常见有:
- FAISS
- Chroma
- SQLite + 向量扩展
更完整的服务型方案
Section titled “更完整的服务型方案”适合:
- 多用户系统
- 大规模数据
- 线上服务
更关注:
- 持久化
- 并发
- 索引管理
- 权限控制
- 运维能力
八、选型时该看什么?
Section titled “八、选型时该看什么?”先看业务规模
Section titled “先看业务规模”关键问题包括:
- 数据量有多大?
- 更新频率高不高?
- 是否必须在线增量写入?
- 是否需要强元数据过滤?
再看工程约束
Section titled “再看工程约束”例如:
- 能不能自部署?
- 是否支持云托管?
- 和现有系统好不好集成?
- 维护成本高不高?
很多时候,最适合的不是“最强大的”,而是“最省心的”。
九、初学者常见误区
Section titled “九、初学者常见误区”以为向量数据库自己就懂语义
Section titled “以为向量数据库自己就懂语义”不是。 真正决定语义质量的首先是 embedding 模型。
以为只要存了向量,RAG 就一定好用
Section titled “以为只要存了向量,RAG 就一定好用”不够。 前面还需要文档清洗、切块,后面还需要 prompt 和答案约束。
只看召回,不看过滤和引用
Section titled “只看召回,不看过滤和引用”很多实际项目里,元数据过滤和来源可追踪同样重要。
向量库调试检查表
Section titled “向量库调试检查表”向量数据库接入后,第一件事不是立刻接 LLM,而是确认“写入、过滤、检索、引用”四件事都可靠。
| 检查项 | 你应该能看到什么 | 常见风险 |
|---|---|---|
| 写入数量 | 原始 chunk 数和入库记录数一致或有明确过滤原因 | 文档解析失败、重复写入 |
| 向量维度 | 同一批记录维度一致 | embedding 模型切换后维度不一致 |
| 元数据 | source、section、page、topic 等字段完整 | 后续无法引用和过滤 |
| 相似度结果 | top-k 结果能打印 id、score、text、metadata | 只看答案,不看命中内容 |
| 过滤条件 | metadata filter 能缩小搜索范围 | 过滤字段类型不一致,导致查不到 |
如果这张表没通过,就不要急着优化 prompt。很多 RAG 问题其实在向量库这一层已经埋下了。
一个最小入库记录校验示例
Section titled “一个最小入库记录校验示例”records = [ { "id": "doc_001_chunk_01", "vector": [0.95, 0.05, 0.10], "text": "课程购买后 7 天内可申请退款", "metadata": {"source": "policy.md", "section": "退款政策", "page": 1}, }, { "id": "doc_001_chunk_02", "vector": [0.10, 0.90, 0.05], "text": "完成结课项目后可获得证书", "metadata": {"source": "policy.md", "section": "证书说明", "page": 2}, },]
required_meta = {"source", "section", "page"}vector_dim = len(records[0]["vector"])
for record in records: problems = [] if len(record["vector"]) != vector_dim: problems.append("vector_dim_mismatch") missing = required_meta - set(record["metadata"]) if missing: problems.append(f"missing_metadata={sorted(missing)}") if not record["text"].strip(): problems.append("empty_text") print(record["id"], problems or "ok")预期输出:
doc_001_chunk_01 okdoc_001_chunk_02 ok这个校验可以放在入库前。真实项目里,一旦 metadata 丢失,后面很难做引用、过滤、权限和评估。
向量数据库选型决策表
Section titled “向量数据库选型决策表”| 场景 | 推荐起点 | 原因 |
|---|---|---|
| 课程学习、小型演示 | 内存列表、FAISS、Chroma | 简单、可见、易调试 |
| 本地原型,需要持久化 | Chroma、SQLite 向量扩展 | 便于保存和重跑 |
| 企业知识库 | 支持元数据过滤和权限的服务型向量库 | 需要并发、权限、监控和运维 |
| 多租户 SaaS | 托管向量数据库或成熟搜索服务 | 关注隔离、扩展、备份和成本 |
选型不要从“哪个最流行”开始,而要从数据量、更新频率、过滤需求、部署方式和维护成本开始。
学完这一页,至少保留这张证据卡:
- 查询
- 一个用户问题或测试用例
- 已检索分块
- 分块 ID、分数和来源标题
- 答案
- 带引用或来源说明的最终回答
- 失败检查
- 缺少证据、切分错误、文档过时或论断无依据
- 下一步动作
- 分块、embedding、重排、Prompt 或评估改动
这一节最关键的认识是:
向量数据库不是“魔法黑盒”,它本质上是在高效管理语义向量及其附属信息。
你真正要关心的,是:
- 向量质量够不够好
- 检索速度够不够快
- 元数据是否能支撑业务需求
- 给迷你向量库再加两条记录,手动构造一个新的
query_vector测试排序。 - 再加一个
source元数据字段,尝试做双条件过滤。 - 想一想:如果 embedding 模型很差,向量数据库再强能不能救回来?
参考实现与讲解
- 排序应优先返回与
query_vector距离最近的记录。如果 top result 在语义上明显不对,弱点通常在向量表示,而不一定在数据库。 - 双条件过滤应把语义相似度和业务约束结合起来,例如
role=internal与source=policy。Metadata 能阻止看似相关但无权限或无关的 chunk 进入回答。 - 向量数据库能高效索引、过滤和搜索,但无法凭空补回 embedding 模型没有编码好的语义。Embedding 很差时,再强的基础设施也很难得到好检索。