9.1.5 Agent 系统架构
完成本节后,你将能够:
- 说清楚一个 Agent 系统常见的核心组件
- 理解单 Agent 架构的基本执行闭环
- 跑通一个带状态与工具注册的迷你架构示例
- 知道真实系统为什么离不开观测和护栏
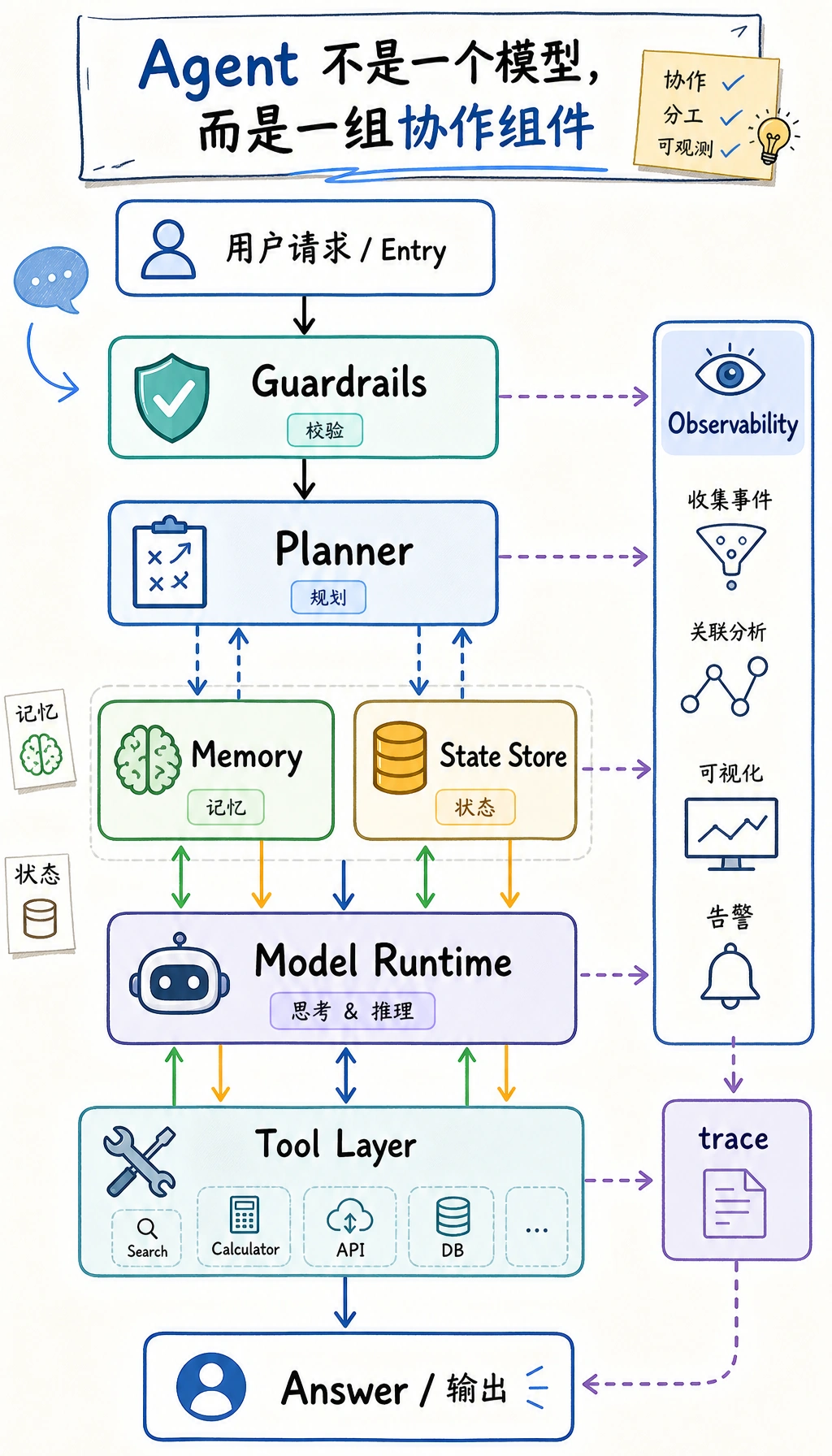
Agent 不是“一个模型”这么简单
Section titled “Agent 不是“一个模型”这么简单”最基础的误解:以为 Agent 只是大模型 + Prompt
Section titled “最基础的误解:以为 Agent 只是大模型 + Prompt”真实可用的 Agent 系统,通常至少还需要:
- 工具层
- 状态管理
- 执行循环
- 错误处理
- 安全限制
模型很重要,但它更像大脑的一部分,而不是整个系统。
你可以把 Agent 想成一个小型操作系统
Section titled “你可以把 Agent 想成一个小型操作系统”里面有:
- 决策中心
- 工具箱
- 记事本
- 执行记录
- 安全规则
这也是为什么 Agent 一旦进入工程化阶段,就不再只是“写 prompt”。
常见核心组件
Section titled “常见核心组件”负责决定:
- 当前任务怎么拆
- 下一步做什么
- 要不要调用工具
在简单系统里,这部分可能直接由 LLM 负责。 在更强控制场景里,也可能由规则 + LLM 混合完成。
这是 Agent 能行动的关键。
工具可能包括:
- 搜索
- 数据库查询
- API 调用
- 文件读写
- 计算器
如果没有工具,很多 Agent 其实只能“说”,不能“做”。
状态、记忆和上下文
Section titled “状态、记忆和上下文”状态:当前任务进行到哪
Section titled “状态:当前任务进行到哪”状态通常记录:
- 用户目标
- 已执行步骤
- 中间结果
- 失败重试次数
这和“长期记忆”不是一回事。 它更像当前任务的工作区。
记忆:跨回合保留什么
Section titled “记忆:跨回合保留什么”记忆更偏向:
- 用户偏好
- 历史项目
- 长期上下文
很多基础 Agent 并不一定一开始就需要复杂记忆,但几乎都会需要状态。
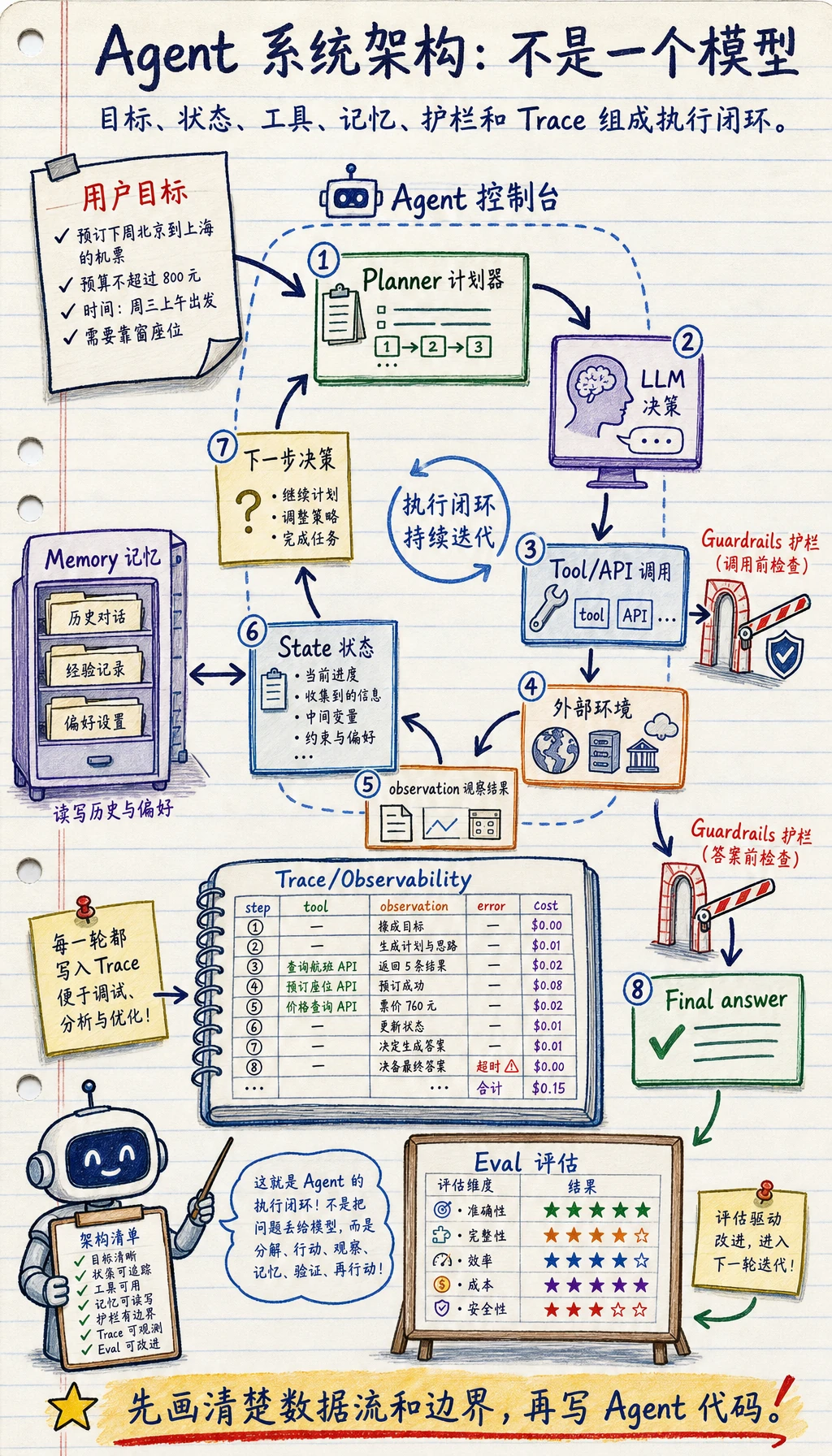
一个标准执行闭环
Section titled “一个标准执行闭环”最小闭环:感知、决策、行动、观察
Section titled “最小闭环:感知、决策、行动、观察”flowchart LR A["输入目标"] --> B["决定下一步"] B --> C["调用工具 / 生成动作"] C --> D["拿到结果并更新状态"] D --> B D --> E["满足结束条件后输出"]
style A fill:#e3f2fd,stroke:#1565c0,color:#333 style B fill:#fff3e0,stroke:#e65100,color:#333 style C fill:#f3e5f5,stroke:#6a1b9a,color:#333 style D fill:#fffde7,stroke:#f9a825,color:#333 style E fill:#e8f5e9,stroke:#2e7d32,color:#333为什么这个闭环很关键?
Section titled “为什么这个闭环很关键?”因为 Agent 的本质不是“一次性回答”,而是:
根据中间结果不断调整动作。
这就是它和普通聊天机器人的根本差别之一。
一个迷你可运行架构示例
Section titled “一个迷你可运行架构示例”下面这个例子里,我们显式写出:
- 工具注册表
- 状态
- 决策逻辑
- 执行循环
import astimport operator
OPS = { ast.Add: operator.add, ast.Sub: operator.sub, ast.Mult: operator.mul, ast.Div: operator.truediv,}
def safe_calculate(expression): def visit(node): if isinstance(node, ast.Expression): return visit(node.body) if isinstance(node, ast.Constant) and isinstance(node.value, (int, float)): return node.value if isinstance(node, ast.BinOp) and type(node.op) in OPS: return OPS[type(node.op)](visit(node.left), visit(node.right)) if isinstance(node, ast.UnaryOp) and isinstance(node.op, ast.USub): return -visit(node.operand) raise ValueError("unsupported_expression")
return visit(ast.parse(expression, mode="eval"))
def tool_weather(city): data = {"北京": "晴 22 度", "上海": "多云 25 度"} return data.get(city, "暂无该城市天气")
def tool_calc(expression): return str(safe_calculate(expression))
TOOLS = { "weather": tool_weather, "calc": tool_calc}
def decide_next_action(state): query = state["query"] if state["done"]: return None
if "天气" in query and not state["steps"]: city = "北京" if "北京" in query else "上海" return {"tool": "weather", "args": city}
if "计算" in query and not state["steps"]: expression = query.replace("计算", "").strip() return {"tool": "calc", "args": expression}
return {"tool": None, "args": None}
def run_agent(query): state = { "query": query, "steps": [], "observations": [], "done": False }
while not state["done"]: action = decide_next_action(state) if action is None or action["tool"] is None: state["done"] = True break
tool_name = action["tool"] args = action["args"] result = TOOLS[tool_name](args)
state["steps"].append(action) state["observations"].append(result) state["done"] = True
if state["observations"]: return state, state["observations"][-1] return state, "没有可执行动作"
state, answer = run_agent("计算 23 * 8")print("状态:", state)print("最终答案:", answer)预期输出:
状态: {'query': '计算 23 * 8', 'steps': [{'tool': 'calc', 'args': '23 * 8'}], 'observations': ['184'], 'done': True}最终答案: 184这个例子很小,但已经包含了 Agent 架构的核心味道。
Guardrails:为什么护栏必不可少?
Section titled “Guardrails:为什么护栏必不可少?”因为 Agent 会行动
Section titled “因为 Agent 会行动”行动就意味着风险。
比如:
- 调错工具
- 重复执行
- 越权访问
- 误删数据
所以真实系统里常见护栏包括:
- 工具白名单
- 参数校验
- 最大步数限制
- 人工确认节点
一个最简单的护栏例子
Section titled “一个最简单的护栏例子”import astimport operator
OPS = { ast.Add: operator.add, ast.Sub: operator.sub, ast.Mult: operator.mul, ast.Div: operator.truediv,}
def safe_calculate(expression): def visit(node): if isinstance(node, ast.Expression): return visit(node.body) if isinstance(node, ast.Constant) and isinstance(node.value, (int, float)): return node.value if isinstance(node, ast.BinOp) and type(node.op) in OPS: return OPS[type(node.op)](visit(node.left), visit(node.right)) if isinstance(node, ast.UnaryOp) and isinstance(node.op, ast.USub): return -visit(node.operand) raise ValueError("unsupported_expression")
return visit(ast.parse(expression, mode="eval"))
def safe_eval(expression): allowed_chars = set("0123456789+-*/(). ") if not set(expression) <= allowed_chars: return "表达式包含不允许的字符" return str(safe_calculate(expression))
print(safe_eval("3 * (4 + 5)"))print(safe_eval("__import__('os').system('rm -rf /')"))预期输出:
27表达式包含不允许的字符护栏的核心思想不是“让系统完全不会错”,而是把错误范围收窄。
Observability:为什么要能看见 Agent 在做什么?
Section titled “Observability:为什么要能看见 Agent 在做什么?”因为多步系统不透明就很难调试
Section titled “因为多步系统不透明就很难调试”你至少希望能看到:
- 每一步决定了什么
- 调了哪个工具
- 工具返回了什么
- 为什么结束
最小观测信息通常包括
Section titled “最小观测信息通常包括”- 输入
- action
- observation
- 最终输出
- 时间成本
很多 Agent 项目最后卡住,不是因为模型太弱,而是因为系统根本看不清自己哪里错了。
单 Agent 和多 Agent
Section titled “单 Agent 和多 Agent”单 Agent 通常先学会
Section titled “单 Agent 通常先学会”大多数系统应该先把单 Agent 打稳:
- 更好调试
- 更易收敛
- 架构更清楚
多 Agent 不是默认升级路线
Section titled “多 Agent 不是默认升级路线”只有当任务真的适合分工时,多 Agent 才值得考虑。
例如:
- 规划 Agent
- 执行 Agent
- 评审 Agent
如果任务不复杂,多 Agent 反而会增加协调成本。
初学者常见误区
Section titled “初学者常见误区”先上多 Agent,再想清楚单 Agent
Section titled “先上多 Agent,再想清楚单 Agent”这通常会让调试难度直线上升。
把状态和记忆混成一件事
Section titled “把状态和记忆混成一件事”状态更偏当前任务,记忆更偏跨任务积累。
没有日志和回放机制
Section titled “没有日志和回放机制”一旦系统出错,就只能靠猜。
学完这一页,至少保留这张证据卡:
- 智能体边界
- 这与聊天机器人或固定工作流有何不同
- 目标状态动作
- 目标、当前状态、下一步动作、观察
- 架构组成
- 规划器、工具、记忆、护栏、评估器
- 失败检查
- 过度自主、目标模糊、状态缺失或没有 trace
- 下一步动作
- 构建最小可追踪的单智能体循环
这一节最重要的认识是:
Agent 架构的关键,不只是“能不能调用工具”,而是能不能把决策、执行、状态、护栏和观测组织成一个稳定闭环。
这也是为什么真正的 Agent 工程,既是模型问题,也是系统设计问题。
- 给迷你 Agent 再增加一个
docs_search工具。 - 给
run_agent()增加“最大步数”限制。 - 想一想:如果工具经常超时,架构层面应该补哪些机制?
参考实现与讲解
docs_search应该定义查询输入、权限与过滤规则、返回格式,以及没有证据时的行为。- 最大步数限制的作用是阻止无限循环,并返回一条 trace,说明执行停在了哪里。
- 架构层面可以增加超时控制、带退避的重试、circuit breaker、fallback 路径、队列限制,以及对工具延迟和错误率的可观测性。