9.9.2 Agent 部署架构
- 理解 Agent 部署架构的核心模块分层
- 理解为什么“模型服务”只是其中一层
- 通过可运行示例掌握请求在架构中的流转
- 建立从演示到生产系统的整体视角
先建立一张地图
Section titled “先建立一张地图”Agent 部署架构更适合按“请求从哪进、决策在哪做、状态存哪、怎么观测”来理解:
flowchart LR A["接入层"] --> B["编排层"] B --> C["执行层"] C --> D["状态与存储层"] B --> E["观测层"]所以这节真正想解决的是:
- 为什么一个脚本和一个可上线系统之间会多出这么多层
- 为什么模型服务只是执行层的一部分
一个可上线的 Agent 系统通常包含哪些层?
Section titled “一个可上线的 Agent 系统通常包含哪些层?”负责:
- 接 HTTP / WebSocket / 内部 RPC 请求
- 做认证、限流、路由
负责:
- 选择工作流
- 调模型
- 决定工具调用
- 管理任务状态
这一层通常就是 Agent 的“大脑外壳”。
负责:
- 实际工具调用
- 模型推理服务
- 检索服务
- 外部 API 调用
状态与存储层
Section titled “状态与存储层”负责:
- 会话状态
- 长期记忆
- 任务 checkpoint
- 日志与审计
负责:
- 指标
- 追踪
- 错误告警
一个更适合新人的总类比
Section titled “一个更适合新人的总类比”你可以把 Agent 部署架构理解成:
- 一家公司接待客户、分派任务、找员工执行、做记录、再回头看运营报表
如果所有事都塞给一个人做, 短期当然能跑起来, 但一旦并发、状态、工具和故障都来了,系统就会很快失控。
这个类比很适合新人,因为它会帮助你先抓住:
- 分层不是为了复杂
- 而是为了把不同责任拆开
为什么“模型 API + 几个工具”还不够叫架构?
Section titled “为什么“模型 API + 几个工具”还不够叫架构?”因为缺少状态边界
Section titled “因为缺少状态边界”一旦任务变长,系统必须明确回答:
- 当前进行到哪一步
- 上一步结果是什么
- 失败后如何恢复
因为缺少执行边界
Section titled “因为缺少执行边界”模型不应该直接承担:
- 权限控制
- 超时策略
- 工具审计
这些更适合由架构层负责。
因为缺少观测边界
Section titled “因为缺少观测边界”如果线上出问题却无法回答:
- 卡在哪个工具
- 哪类请求最慢
- 哪类链路最容易失败
那系统就很难长期维护。
先看一个最小架构流转示例
Section titled “先看一个最小架构流转示例”这个示例不会真的起服务, 但它会非常清楚地展示请求怎样在架构中流动:
- 接入层接收请求
- 编排层选择工具
- 执行层调用工具
- 存储层记录状态
- 观测层打 追踪
def gateway(request): return { "request_id": request["request_id"], "user_id": request["user_id"], "message": request["message"], }
def orchestrator(envelope): if "退款" in envelope["message"]: return {"workflow": "refund_flow", "tool": "search_policy"} return {"workflow": "default_flow", "tool": "none"}
def tool_executor(tool_name, message): if tool_name == "search_policy": return {"policy_text": "退款需满足 7 天内且学习进度低于 20%。"} return {"note": "no_tool_used"}
def state_store(request_id, workflow, observation): return { "request_id": request_id, "workflow": workflow, "observation": observation, }
def trace_logger(request_id, stage, payload): return {"request_id": request_id, "stage": stage, "payload": payload}
request = {"request_id": "req-001", "user_id": "u-01", "message": "请告诉我退款规则"}
envelope = gateway(request)trace = [trace_logger(envelope["request_id"], "gateway", envelope)]
decision = orchestrator(envelope)trace.append(trace_logger(envelope["request_id"], "orchestrator", decision))
observation = tool_executor(decision["tool"], envelope["message"])trace.append(trace_logger(envelope["request_id"], "tool_executor", observation))
persisted = state_store(envelope["request_id"], decision["workflow"], observation)trace.append(trace_logger(envelope["request_id"], "state_store", persisted))
for item in trace: print(item)预期输出:
{'request_id': 'req-001', 'stage': 'gateway', 'payload': {'request_id': 'req-001', 'user_id': 'u-01', 'message': '请告诉我退款规则'}}{'request_id': 'req-001', 'stage': 'orchestrator', 'payload': {'workflow': 'refund_flow', 'tool': 'search_policy'}}{'request_id': 'req-001', 'stage': 'tool_executor', 'payload': {'policy_text': '退款需满足 7 天内且学习进度低于 20%。'}}{'request_id': 'req-001', 'stage': 'state_store', 'payload': {'request_id': 'req-001', 'workflow': 'refund_flow', 'observation': {'policy_text': '退款需满足 7 天内且学习进度低于 20%。'}}}这段代码真正想教什么?
Section titled “这段代码真正想教什么?”不是“写几个函数”, 而是让你脑子里出现清晰分层:
- 请求入口
- 决策逻辑
- 工具执行
- 状态保存
- 跟踪记录
这几个层一旦分清,架构就开始稳定。
为什么编排层和执行层要分开?
Section titled “为什么编排层和执行层要分开?”因为:
- 编排层负责“决定”
- 执行层负责“做事”
两者混在一起,后面很难做:
- 安全控制
- 独立扩缩容
- 调试
为什么状态存储不能只是日志?
Section titled “为什么状态存储不能只是日志?”因为日志更像“发生过什么”。 真正的状态还包括:
- 当前步骤
- 当前上下文
- 是否可恢复
它比日志更偏“可继续执行”。
一个很适合初学者先记的分层表
Section titled “一个很适合初学者先记的分层表”| 层 | 最值得先记住的职责 |
|---|---|
| 接入层 | 收请求、做认证和限流 |
| 编排层 | 决定该走哪条链路 |
| 执行层 | 真正调模型和工具 |
| 状态层 | 记住当前任务进行到哪 |
| 观测层 | 让你知道系统哪里出问题 |
这个表很适合新人,因为它会把“架构层次很多”重新压回成五个很清楚的角色。
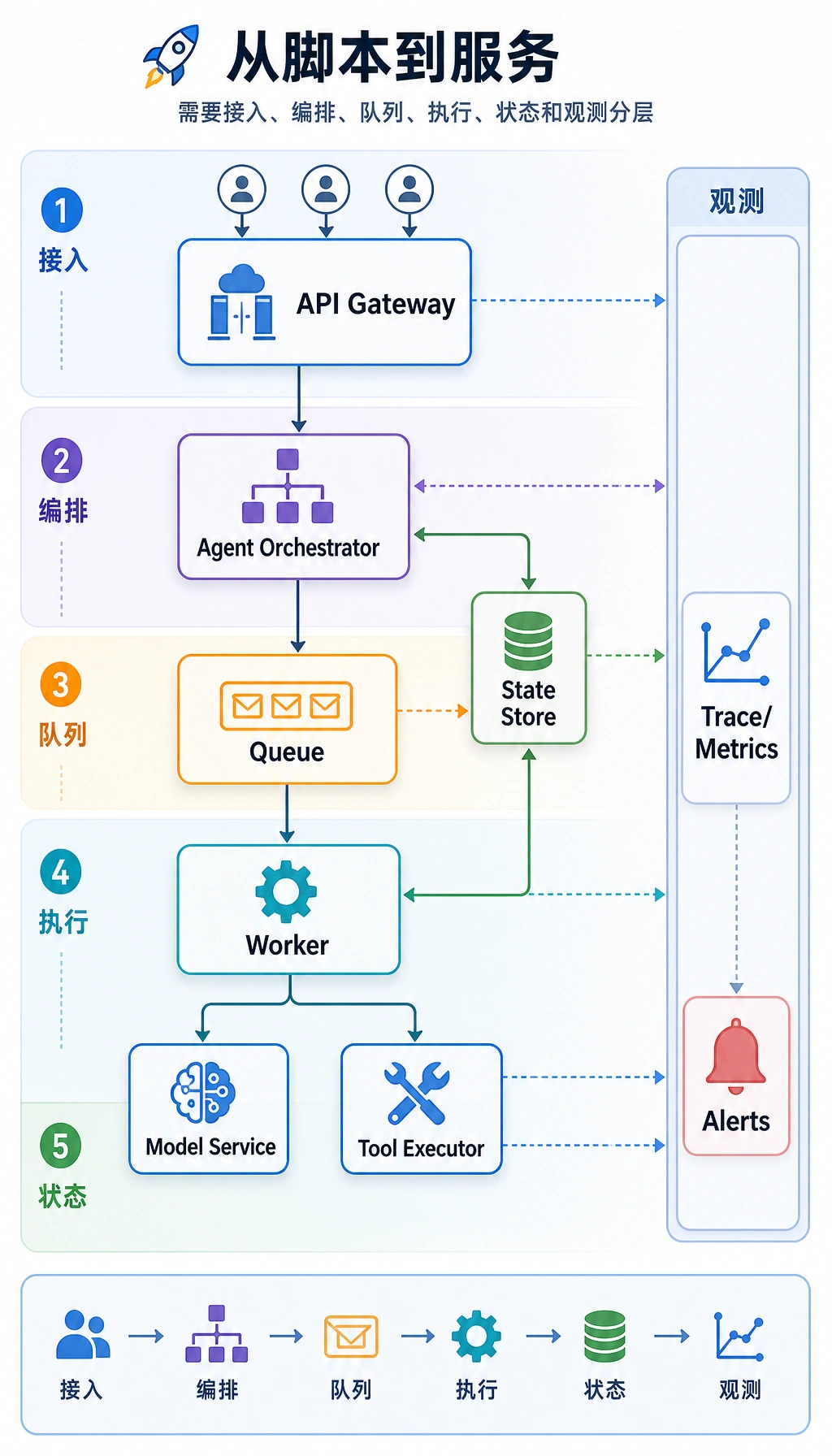
一个更常见的生产架构长什么样?
Section titled “一个更常见的生产架构长什么样?”通常可以抽象成下面这条链:
flowchart LR A["客户端 / 前端"] --> B["API 网关"] B --> C["Agent 编排器"] C --> D["模型服务"] C --> E["工具执行器"] C --> F["队列 / Worker"] C --> G["状态存储"] C --> H["追踪 / 指标"] E --> I["外部 API / 数据库 / 搜索"]这张图里的关键点是:
- 模型服务只是执行层的一部分
- 工具系统通常是独立执行层
- 状态和观测都应作为独立支撑层存在
什么时候需要队列和异步 工作进程?
Section titled “什么时候需要队列和异步 工作进程?”例如:
- 生成长报告
- 多阶段数据整理
- 多工具异步流程
不适合阻塞用户请求的任务
Section titled “不适合阻塞用户请求的任务”例如:
- 批量总结
- 周报生成
- 长链路分析
为什么队列有帮助?
Section titled “为什么队列有帮助?”它能带来:
- 异步解耦
- 限流缓冲
- 失败重试
但代价是:
- 系统更复杂
- 状态管理更难
第一次做部署设计时,最稳的默认顺序
Section titled “第一次做部署设计时,最稳的默认顺序”更稳的顺序通常是:
- 先分清接入、编排、执行三层
- 先把状态写入点想清楚
- 先把 追踪 和 指标 补上
- 最后再决定是否真的要引入队列和异步 工作进程
这样会比一开始就上很多中间件更容易把系统主线立住。
最容易踩的架构误区
Section titled “最容易踩的架构误区”误区一:所有逻辑都塞进一个服务
Section titled “误区一:所有逻辑都塞进一个服务”开始时简单,后期会变成:
- 工具执行和编排耦合
- 扩容困难
- 观测困难
误区二:有数据库就算有状态架构
Section titled “误区二:有数据库就算有状态架构”数据库只是存储手段。 真正关键是你有没有想清楚:
- 存什么
- 什么时候写
- 谁来恢复
误区三:上线后再补 追踪 和 指标
Section titled “误区三:上线后再补 追踪 和 指标”没有观测,出了问题几乎只能靠猜。
如果把它做成项目或系统设计,最值得展示什么
Section titled “如果把它做成项目或系统设计,最值得展示什么”最值得展示的通常不是:
- 一张堆满服务名的架构图
而是:
- 请求是怎么穿过各层的
- 哪一层负责决策,哪一层负责执行
- 状态在哪写、为什么写
- 出错时 追踪 怎样帮助你定位问题
这样别人会更容易看出:
- 你理解的是架构分层逻辑
- 不只是画了一张图
学完这一页,至少保留这张证据卡:
- 运行时
- 队列、worker、状态存储、工具服务,以及模型端点
- 持久化
- 检查点、事件日志、记忆存储和恢复路径
- 运维信号
- 延迟、成本、错误率、trace 覆盖率和饱和度
- 失败检查
- 运行卡住、重复动作、部分失败或成本失控
- 恢复动作
- 继续、回滚、取消、人工接管,或优雅降级
这节最重要的不是记住多少基础设施名字, 而是建立一张清楚的上线地图:
一个可上线的 Agent 系统,至少要分清接入、编排、执行、状态和观测五层;模型只是其中一层,而不是全部。
只要这张地图在脑子里立住, 你后面做运行时、恢复、成本和生产实践时,就会更顺。
- 把示例里的
search_policy再扩成需要两个工具配合的流程,观察哪一层最适合做状态汇总。 - 如果你要支持长任务异步执行,你会把队列放在哪一层?为什么?
- 为什么说“模型服务”不能等同于“Agent 架构”?
- 想一想:你的当前项目最缺的是接入层、执行层,还是观测层?
项目交付参考与讲解
- 两工具 workflow 可以先检索 policy,再检查 eligibility 或生成摘要。state aggregation 通常放在 execution/orchestration 层,因为它同时看得到工具结果和当前任务状态。
- queue 可以放在 access layer 与 execution layer 之间,或放在 execution layer 边界内。它能保护用户侧 API 不被长任务拖住,也提供 retry、status、cancel 控制点。
- model service 只是一个依赖。Agent architecture 还包括 tools、state、memory、permissions、queues、traces、retries 和 safety gates。
- 判断当前项目缺哪层,可以问真实用户进来时哪里会先坏:请求接入、任务执行,还是可观测性。会让失败不可见或不可恢复的,就是最缺的层。