9.9.6 生产环境最佳实践
- 理解生产环境里最关键的发布与运维原则
- 学会设计最小上线前检查清单
- 理解灰度、回滚、告警和人工接管的作用
- 通过可运行示例建立生产就绪检查思路
上线前真正要确认什么?
Section titled “上线前真正要确认什么?”功能正确只是最基础的一层
Section titled “功能正确只是最基础的一层”生产就绪至少还包括:
- 是否可观测
- 是否可回滚
- 是否有限流和超时
- 是否有安全边界
- 是否有评估基线
一个很实用的判断
Section titled “一个很实用的判断”如果某个服务上线后出了事,你是否已经知道:
- 去哪里看日志
- 看哪些指标
- 如何切回旧版本
- 谁来人工接管
如果这些问题答不上来,系统通常还没准备好进生产。
生产环境最重要的六条原则
Section titled “生产环境最重要的六条原则”先灰度,不要全量直上
Section titled “先灰度,不要全量直上”Agent 系统的不确定性通常比普通 CRUD 更高。 灰度能让你先观察:
- 正确率变化
- 延迟变化
- 成本变化
始终保留回滚路径
Section titled “始终保留回滚路径”没有回滚,就没有真正安全的发布。
关键能力必须有人工接管方案
Section titled “关键能力必须有人工接管方案”特别是:
- 高风险操作
- 写操作
- 外部副作用类任务
先定义告警,再谈上线
Section titled “先定义告警,再谈上线”至少要明确:
- 哪些指标异常要告警
- 谁接告警
- 触发后第一步查什么
所有关键动作都应可审计
Section titled “所有关键动作都应可审计”尤其是:
- 工具调用
- 权限判断
- 关键状态变更
发布要和评估绑定
Section titled “发布要和评估绑定”上线不是“相信模型”, 而是“让评估和线上信号共同说话”。
先跑一个最小就绪检查器
Section titled “先跑一个最小就绪检查器”下面这个示例会模拟一套上线前检查。 它不会直接部署服务,而是回答:
- 现在这套系统是否具备最基础的生产条件
deployment_config = { "has_metrics": True, "has_structured_logs": True, "has_timeout": True, "has_retry_policy": True, "has_rate_limit": False, "has_eval_suite": True, "has_canary_rollout": True, "has_rollback_plan": True, "has_human_override": False, "has_audit_log": True,}
def readiness_check(config): required = [ "has_metrics", "has_structured_logs", "has_timeout", "has_retry_policy", "has_eval_suite", "has_canary_rollout", "has_rollback_plan", "has_audit_log", ]
missing_required = [key for key in required if not config.get(key, False)] warnings = []
if not config.get("has_rate_limit", False): warnings.append("missing_rate_limit") if not config.get("has_human_override", False): warnings.append("missing_human_override")
ready = len(missing_required) == 0 return { "ready": ready, "missing_required": missing_required, "warnings": warnings, }
print(readiness_check(deployment_config))预期输出:
{'ready': True, 'missing_required': [], 'warnings': ['missing_rate_limit', 'missing_human_override']}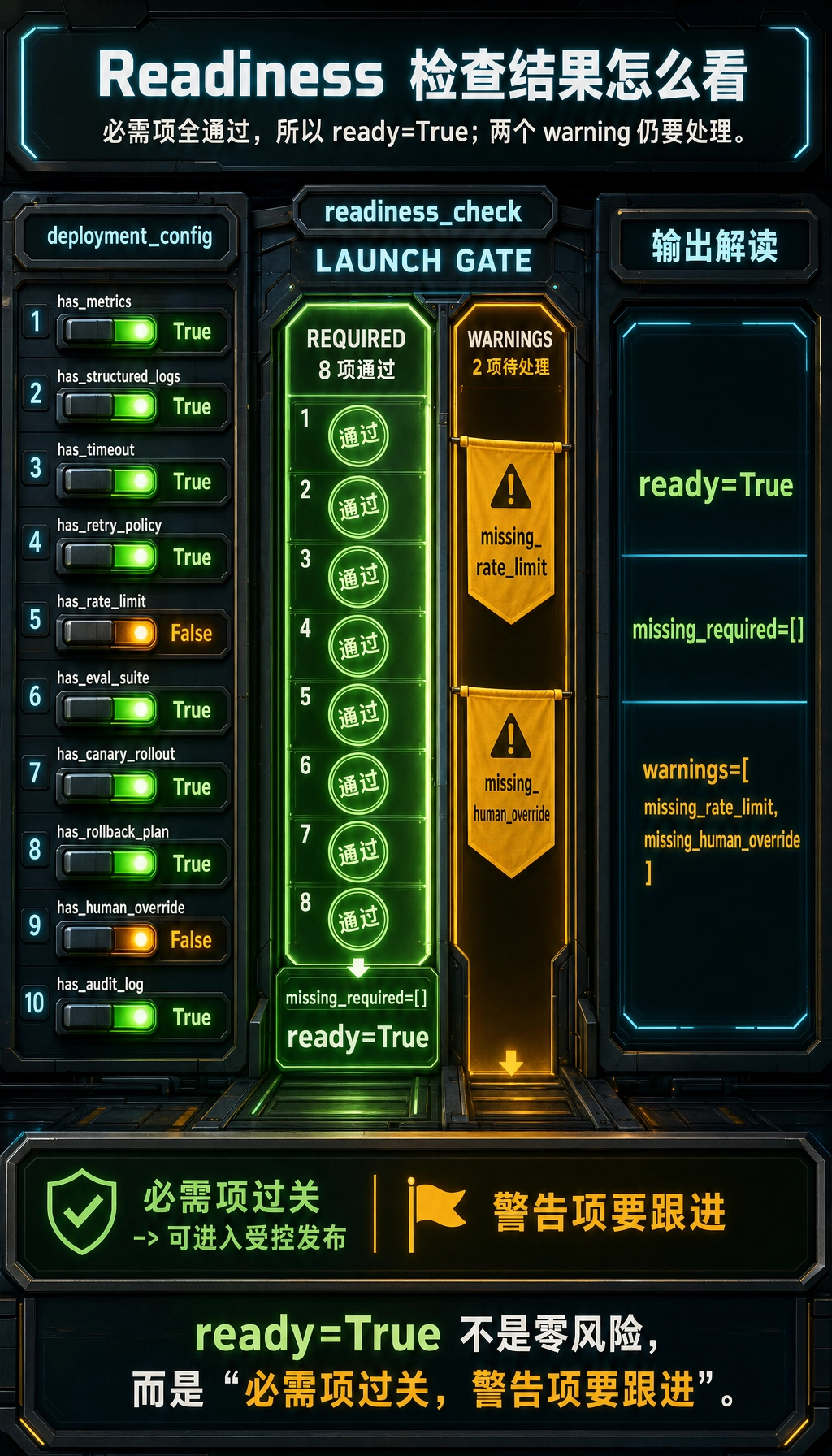
这个示例最重要的启发是什么?
Section titled “这个示例最重要的启发是什么?”它提醒你:
- 生产就绪不是一种感觉
- 而是一组可检查条件
trace 和回放最低要记录什么?
Section titled “trace 和回放最低要记录什么?”Agent 上线后,最怕的是“用户说错了,但工程师只能看到最终答案”。生产环境至少要能回放一次请求的关键路径:
| 记录项 | 为什么要留 |
|---|---|
request_id | 把用户请求、日志、工具调用和最终答案串起来 |
prompt_version / model_version | 判断问题是否来自 Prompt 或模型变更 |
tool_calls | 看到调用了什么工具、参数是什么、返回了什么 |
state_before / state_after | 判断状态是否被错误更新 |
latency_ms / cost | 定位慢请求和成本异常 |
fallback_or_handoff | 记录是否触发降级、回滚或人工接管 |
没有这些记录,回滚只能靠猜。真正可运维的 Agent,应该能回答:这次输出由哪个 Prompt、哪个模型、哪些工具、哪些状态共同产生。

为什么把“缺失项”显式列出来很重要?
Section titled “为什么把“缺失项”显式列出来很重要?”因为这样团队讨论就会从:
- “好像差不多了”
变成:
- “现在缺 rate limit 和 human override”
这会让上线决策更清楚。
灰度发布为什么对 Agent 尤其重要?
Section titled “灰度发布为什么对 Agent 尤其重要?”因为 Agent 的问题往往是概率性的
Section titled “因为 Agent 的问题往往是概率性的”有些问题不会在本地固定复现, 而是在真实流量里才暴露,例如:
- 某类复杂输入触发错误路线
- 某工具在高并发下表现不稳
- 某些 prompt 在边缘样本上失控
灰度的核心收益
Section titled “灰度的核心收益”- 先少量流量验证
- 保留旧系统兜底
- 在真实环境中收集指标
一个很简单的流量分配示意
Section titled “一个很简单的流量分配示意”def route_request(request_id, canary_ratio=0.2): bucket = sum(ord(c) for c in request_id) % 100 return "new_agent" if bucket < canary_ratio * 100 else "stable_agent"
for request_id in ["req-001", "req-002", "req-003", "req-004"]: print(request_id, "->", route_request(request_id))预期输出:
req-001 -> new_agentreq-002 -> new_agentreq-003 -> stable_agentreq-004 -> stable_agent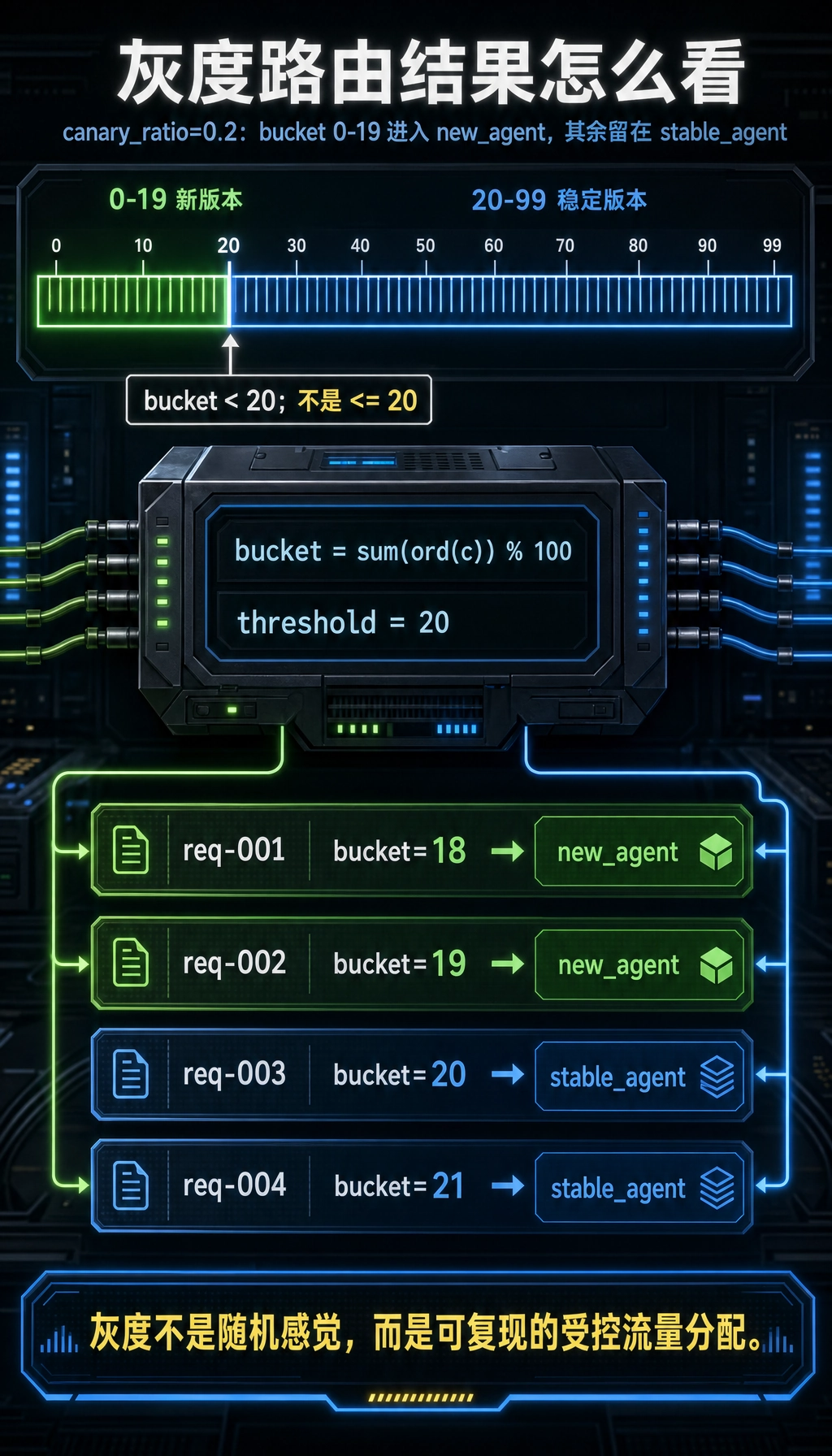
这段代码虽然简单,但它体现了:
- 灰度并不神秘
- 本质上就是受控流量分配
回滚为什么必须提前设计?
Section titled “回滚为什么必须提前设计?”回滚不是出事后临时想办法
Section titled “回滚不是出事后临时想办法”如果系统一出问题才开始想:
- 切回哪个版本
- 状态怎么恢复
- 数据副作用怎么处理
通常已经太晚。
回滚至少要回答三件事
Section titled “回滚至少要回答三件事”- 怎么切回旧版本
- 新版本产生的中间状态怎么处理
- 是否需要暂停高风险动作
为什么 Agent 回滚比普通页面更复杂?
Section titled “为什么 Agent 回滚比普通页面更复杂?”因为它可能已经产生了:
- 工具调用副作用
- 持久化状态
- 外部系统写入
所以回滚不仅是“切镜像”, 还要考虑状态一致性。
告警和人工接管怎么配合?
Section titled “告警和人工接管怎么配合?”告警不是越多越好
Section titled “告警不是越多越好”关键是:
- 告警要能触发具体动作
例如:
- 超时率 > 5%
- 熔断连续打开
- 成本突然偏离正常区间
人工接管不是系统失败,而是系统成熟
Section titled “人工接管不是系统失败,而是系统成熟”在高风险系统里, 人工接管说明你承认:
- 自动化不是无边界的
这反而更像成熟设计。
常见接管方式
Section titled “常见接管方式”- 转人工客服
- 暂停写操作
- 切换只读模式
- 要求人工审批
最容易踩的误区
Section titled “最容易踩的误区”误区一:上线前只做功能自测
Section titled “误区一:上线前只做功能自测”没有评估、观测、回滚和灰度, 功能自测远远不够。
误区二:只有安全系统才需要审计
Section titled “误区二:只有安全系统才需要审计”很多普通业务 Agent 也会涉及:
- 用户数据
- 写操作
- 外部副作用
审计一样重要。
误区三:生产最佳实践就是一张 checklist
Section titled “误区三:生产最佳实践就是一张 checklist”checklist 很重要, 但它真正有用的前提是:
- 团队知道谁负责
- 出事时真的会执行
学完这一页,至少保留这张证据卡:
- 运行时
- 队列、worker、状态存储、工具服务,以及模型端点
- 持久化
- 检查点、事件日志、记忆存储和恢复路径
- 运维信号
- 延迟、成本、错误率、trace 覆盖率和饱和度
- 失败检查
- 运行卡住、重复动作、部分失败或成本失控
- 恢复动作
- 继续、回滚、取消、人工接管,或优雅降级
这节最重要的是建立一个生产观:
Agent 的生产就绪,不是“功能跑通”就结束,而是必须同时具备灰度、回滚、告警、审计和人工接管这些保障机制。
只有这些机制在,系统才配得上“生产环境”这四个字。
- 根据你现在的项目,列一版自己的就绪配置表,看看缺哪些项。
- 为什么说灰度发布对 Agent 比对静态页面更重要?
- 如果某个高风险工具调用开始异常增多,你会优先做告警、熔断,还是人工接管?为什么?
- 想一想:回滚为什么不只是“把代码切回上一个版本”?
项目交付参考与讲解
- 就绪检查表应为 tools、permissions、tracing、evaluation cases、rollback、budget limits、human approval、incident response 写清 owner、status、evidence 和 next action。
- canary rollout 对 Agent 更重要,因为行为受 prompt、tools、外部数据、模型版本和用户目标共同影响。小流量暴露能发现静态页面检查发现不了的问题。
- 如果高风险调用异常增加,先加 alerting 让人知道;如果行为危险或无法解释,再启用 circuit breaking;必须继续安全处理的场景交给 human takeover。
- rollback 不只是切回旧代码,因为 prompt、model version、tool schema、memory、queue、cached results 和外部副作用也可能需要回退或对账。