9.4.6 记忆工程实现
- 理解记忆工程里的核心决策:写入、检索、过期、压缩
- 学会设计一条最小可运行的记忆读写链路
- 理解为什么“记忆越多”不等于“效果越好”
- 通过可运行示例掌握记忆评分与清理的基本实现
记忆工程真正要解决什么?
Section titled “记忆工程真正要解决什么?”记忆系统不是一个“桶”,而是一个带策略的流程
Section titled “记忆系统不是一个“桶”,而是一个带策略的流程”如果我们把所有对话和工具结果全丢进长期记忆,短期看起来很完整,长期通常会出现:
- 噪声越来越多
- 检索命中率下降
- token 成本上升
- 关键事实反而被淹没
所以记忆工程的核心不是“全存”,而是“有策略地存”。
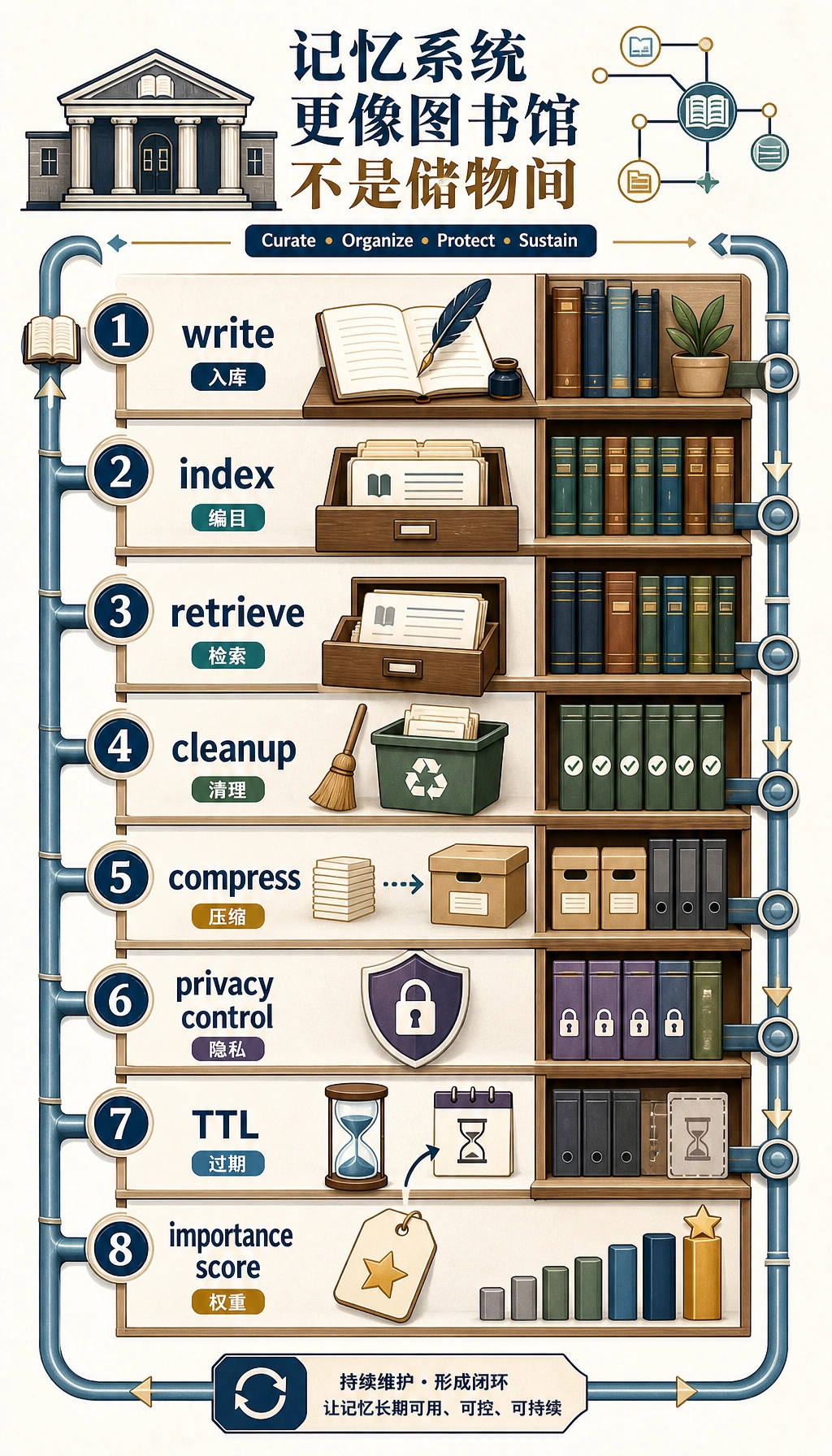
记忆链路可以先拆成四段
Section titled “记忆链路可以先拆成四段”write:是否写入index:写入后如何组织retrieve:查询时如何排序lifecycle:过期、清理、压缩
只要这四段清楚,系统就比较容易稳。
记忆系统更像图书馆,而不是储物间。
- 储物间只管“放进去”
- 图书馆要管“编目、检索、淘汰、归档”
Agent 要长期工作,必须接近后者。
写入策略:什么信息值得进入长期记忆?
Section titled “写入策略:什么信息值得进入长期记忆?”并不是每条消息都值得写
Section titled “并不是每条消息都值得写”例如下面两类信息价值很不同:
- “你好,在吗?”
- “用户偏好简洁回答,不要超过三点”
第二条更适合长期保留,第一条通常不值得。
一个实用写入判断
Section titled “一个实用写入判断”可以先用三个问题过滤:
- 这条信息是否会在未来复用?
- 这条信息是否和用户、任务或策略相关?
- 这条信息是否足够稳定,不是一次性噪声?
常见可写入类型
Section titled “常见可写入类型”- 用户偏好
- 稳定背景信息
- 关键任务结论
- 经验证可复用的步骤摘要
常见不建议直接长期写入的类型:
- 临时中间日志
- 重复寒暄
- 无法验证的猜测性内容
检索策略:怎么把“有用记忆”找回来?
Section titled “检索策略:怎么把“有用记忆”找回来?”检索不只是语义相似度
Section titled “检索不只是语义相似度”纯相似度有时会漏掉很关键的工程信号,例如:
- 这条记忆是不是太旧
- 这条记忆本身重要性是否高
- 是否和当前用户有关
一个常见排序组合
Section titled “一个常见排序组合”检索得分可以来自多项加权:
- 语义或关键词相关度
- 重要性分
- 新鲜度衰减
- 来源可信度
这比只看“像不像”更稳。
为什么要考虑衰减
Section titled “为什么要考虑衰减”某些信息会过时。 如果没有时间衰减,系统可能一直拿很旧的偏好或上下文参与当前决策。
生命周期:过期、清理和压缩
Section titled “生命周期:过期、清理和压缩”TTL 不是可选项
Section titled “TTL 不是可选项”有些记忆天然短命,例如:
- 当前会话临时参数
- 一次性状态标记
这类信息最好带 TTL。
清理不是“定时删一批”那么简单
Section titled “清理不是“定时删一批”那么简单”更好的做法通常是结合:
- 过期检查
- 低价值淘汰
- 重复内容合并
压缩能让系统长期可持续
Section titled “压缩能让系统长期可持续”当记录越来越多时,可以把同类历史压成摘要,例如:
- 最近 20 条“用户偏好确认”合并成一条稳定偏好记录
这能显著减轻检索噪声和上下文压力。
先跑一个可执行的最小记忆引擎
Section titled “先跑一个可执行的最小记忆引擎”下面这个示例会完整演示:
- 短期消息窗口
- 长期记忆写入(带 importance 和 TTL)
- 查询检索(相关度 + 重要性 + 新鲜度)
- 过期清理
from dataclasses import dataclassfrom collections import dequeimport math
@dataclassclass MemoryItem: memory_id: int text: str tags: list source: str importance: float created_step: int ttl_steps: int | None
class MemoryEngine: def __init__(self, short_window=4): self.short_messages = deque(maxlen=short_window) self.long_memories = [] self.step = 0 self._next_id = 1
def tick(self): self.step += 1
def add_short_message(self, role, content): self.short_messages.append({"role": role, "content": content, "step": self.step})
def write_long_memory(self, text, tags=None, source="dialogue", importance=0.5, ttl_steps=None): tags = tags or [] normalized = text.strip().lower()
# 极简去重: 完全相同文本不重复写 for item in self.long_memories: if item.text.strip().lower() == normalized and self._is_alive(item): return item.memory_id
memory = MemoryItem( memory_id=self._next_id, text=text, tags=tags, source=source, importance=float(importance), created_step=self.step, ttl_steps=ttl_steps, ) self._next_id += 1 self.long_memories.append(memory) return memory.memory_id
def _is_alive(self, item): if item.ttl_steps is None: return True return (self.step - item.created_step) <= item.ttl_steps
def cleanup(self): self.long_memories = [item for item in self.long_memories if self._is_alive(item)]
def _tokenize(self, text): lowered = text.lower() compacted = lowered.replace(" ", "") tokens = set(lowered.split()) tokens.update(compacted[i : i + 2] for i in range(max(len(compacted) - 1, 0))) return tokens
def retrieve(self, query, top_k=3): query_tokens = self._tokenize(query) scored = []
for item in self.long_memories: if not self._is_alive(item): continue
item_tokens = self._tokenize(item.text) | set(tag.lower() for tag in item.tags) overlap = len(query_tokens & item_tokens)
age = self.step - item.created_step recency = math.exp(-age / 20) # 越新分越高
score = (0.55 * overlap) + (0.30 * item.importance) + (0.15 * recency) scored.append((item, round(score, 4)))
scored.sort(key=lambda x: x[1], reverse=True) return scored[:top_k]
engine = MemoryEngine(short_window=3)
engine.add_short_message("user", "我想了解退款条件")engine.write_long_memory( "用户偏好: 回答尽量简洁,最多三点", tags=["preference", "style", "简洁", "风格"], importance=0.95,)
engine.tick()engine.add_short_message("assistant", "好的,我会简洁说明")engine.write_long_memory( "临时调试标记: 本轮使用实验提示词 v2", tags=["debug"], importance=0.2, ttl_steps=1,)
engine.tick()engine.write_long_memory( "退款政策关键点: 7天内且学习进度低于20%", tags=["refund", "policy", "退款", "政策"], importance=0.9,)
print("before cleanup:", [m.text for m in engine.long_memories])engine.tick()engine.cleanup()print("after cleanup :", [m.text for m in engine.long_memories])
results = engine.retrieve("请按简洁风格回答退款政策", top_k=2)print("\nretrieval:")for item, score in results: print(item.memory_id, round(score, 4), item.text)预期输出:
before cleanup: ['用户偏好: 回答尽量简洁,最多三点', '临时调试标记: 本轮使用实验提示词 v2', '退款政策关键点: 7天内且学习进度低于20%']after cleanup : ['用户偏好: 回答尽量简洁,最多三点', '退款政策关键点: 7天内且学习进度低于20%']
retrieval:1 2.0641 用户偏好: 回答尽量简洁,最多三点3 2.0627 退款政策关键点: 7天内且学习进度低于20%
这段代码最值得学的三点
Section titled “这段代码最值得学的三点”- 写入不是无条件
通过
importance、tags、去重控制写入质量 - 检索不是纯相似度 相关度、重要性、新鲜度一起决定排序
- 生命周期必须有
通过
ttl_steps和cleanup防止长期膨胀
为什么“调试标记”被清掉是合理的?
Section titled “为什么“调试标记”被清掉是合理的?”因为它是临时信息,设置了 ttl_steps=1。
在后续步骤里继续保留它,通常只会污染检索结果。
为什么“用户偏好”和“退款政策”会被优先召回?
Section titled “为什么“用户偏好”和“退款政策”会被优先召回?”因为查询词同时触发了:
简洁对应偏好记忆退款政策对应政策记忆
而且它们 importance 更高、未过期。
工程实践里还要补哪几层?
Section titled “工程实践里还要补哪几层?”隐私和敏感信息处理
Section titled “隐私和敏感信息处理”写入长期记忆前,通常要做:
- PII 脱敏
- 合规字段过滤
存储后端与索引
Section titled “存储后端与索引”示例里是内存结构。 真实系统常见会接:
- KV / 文档库
- 向量库
- 关系库
建议至少观察:
- 记忆命中率
- 过期清理率
- 平均召回条数
- 误召回率
没有指标,记忆系统很容易越改越黑盒。
误区一:记忆越多越聪明
Section titled “误区一:记忆越多越聪明”记忆越多也可能越吵。 关键是有效记忆占比,而不是总量。
误区二:只做写入,不做清理
Section titled “误区二:只做写入,不做清理”这会导致长期检索噪声累积,后期效果反而下降。
误区三:只做语义检索,不做策略层
Section titled “误区三:只做语义检索,不做策略层”记忆工程一定是“检索 + 策略”的组合, 不是单一向量搜索就能解决全部问题。
学完这一页,至少保留这张证据卡:
- 记忆类型
- 短期、长期、情景或程序性
- 写入规则
- 在内存创建或更新时
- 检索规则
- 查询、相关性、时效性和权限检查
- 失败检查
- 过时记忆、隐私泄漏、矛盾或过度检索
- 清理动作
- 总结、合并、过期、删除或请求确认
这节最重要的不是再记几个“记忆类型名词”, 而是建立一个工程判断:
记忆系统是否可用,取决于写入、检索、生命周期三条策略是否闭环,而不是是否接了一个存储组件。
当你把这条闭环跑起来, 记忆系统才会从概念变成稳定能力。
- 给示例增加“来源可信度”字段,把它纳入检索打分。
- 把
ttl_steps设得更短或更长,观察召回结果如何变化。 - 设计一条“永不过期但低重要度”的记忆,看看它会不会污染结果。
- 你会如何给“用户偏好”与“临时调试信息”设置不同写入策略?
参考实现与讲解
- source credibility 可以作为分数乘子或 tie-breaker,让明确、近期、可信的 memory 排在弱推断 memory 前面。
ttl_steps更短会更快清除临时 memory;更长会让它们更久可用,但也增加 stale retrieval 风险。- “永不过期但低重要性”的 memory 不应该主导结果。如果它总被召回,说明 retrieval score 过度偏向 permanence。
- 用户偏好应要求更强证据和更长 TTL;临时 debug 信息应低写入优先级、短 TTL、窄 retrieval scope。