9.6.4 LlamaIndex
- 理解 LlamaIndex 的核心抽象对象
- 理解它为什么特别适合知识和文档场景
- 看懂 Document -> Node -> Index -> 检索器 -> 查询 Engine 这条链
- 建立什么时候该优先考虑 LlamaIndex 的判断
为什么很多 LLM 项目其实首先是“知识系统项目”?
Section titled “为什么很多 LLM 项目其实首先是“知识系统项目”?”不是所有系统都在解决对话问题
Section titled “不是所有系统都在解决对话问题”很多真实 LLM 应用的核心,其实不是聊天,而是:
- 企业知识库问答
- 文档检索
- 研究资料整合
- 报告辅助生成
这些任务的共同点是:
知识本身的组织方式,直接决定系统质量。
这正是 LlamaIndex 最有价值的地方
Section titled “这正是 LlamaIndex 最有价值的地方”它不是只问“怎么调模型”,而是在问:
- 文档怎么进系统
- 信息怎么切分
- 检索结构怎么搭
- 查询怎么组织
所以一个非常实用的理解是:
LlamaIndex 更像知识系统框架,而不是纯工作流框架。
先把几个最重要的概念分清
Section titled “先把几个最重要的概念分清”文档(Document)
Section titled “文档(Document)”最原始的知识单元。 例如:
- 一篇文章
- 一份 PDF
- 一段网页内容
节点(Node)
Section titled “节点(Node)”Document 被切分后的更小单位。 在很多知识系统里,真正拿去做检索的往往不是整篇文档,而是更细粒度的 node。
索引(Index)
Section titled “索引(Index)”把这些 node 组织成可查询结构的方式。
检索器(检索器)
Section titled “检索器(检索器)”负责根据用户查询,把相关 node 找回来。
查询引擎(查询 Engine)
Section titled “查询引擎(查询 Engine)”把“查询 -> 检索 -> 组织结果”整成更完整的一层。
一句话先记:
文档是原料,节点是切好的原料,索引是仓储结构,检索器负责找货,查询引擎负责把货拿出来给用户。
先用纯 Python 走一遍这条链
Section titled “先用纯 Python 走一遍这条链”文档 -> 节点
Section titled “文档 -> 节点”documents = [ {"id": "doc1", "text": "课程购买后 7 天内且学习进度低于 20% 可退款。"}, {"id": "doc2", "text": "完成所有项目并通过测试后可获得证书。"}]
nodes = []for doc in documents: nodes.append({ "doc_id": doc["id"], "text": doc["text"] })
print(nodes)预期输出:
[{'doc_id': 'doc1', 'text': '课程购买后 7 天内且学习进度低于 20% 可退款。'}, {'doc_id': 'doc2', 'text': '完成所有项目并通过测试后可获得证书。'}]这个例子虽然简单,但已经表达了一个核心思想:
原始文档通常不会直接拿来问答,而是先变成更适合索引和检索的知识单元。
为什么“文档摄取”是知识系统的第一步?
Section titled “为什么“文档摄取”是知识系统的第一步?”原始文档通常很脏
Section titled “原始文档通常很脏”真实文档可能包含:
- 页眉页脚
- 重复段落
- 表格噪声
- 很长的大段落
如果不先处理好,后面的检索往往会一起变差。
所以知识系统最常见的第一步不是“调模型”
Section titled “所以知识系统最常见的第一步不是“调模型””而是:
- 读文档
- 清洗
- 切分
- 加元数据
这就是为什么 LlamaIndex 这种框架会特别强调 ingest。
索引和检索为什么是它的中心?
Section titled “索引和检索为什么是它的中心?”因为知识应用最怕“文档在那,但系统找不到”
Section titled “因为知识应用最怕“文档在那,但系统找不到””如果:
- 文档很多
- 节点很多
- 问题表达很灵活
那没有好的索引和检索层,后面模型再强也会被拖累。
一个最小检索示例
Section titled “一个最小检索示例”如果你想在本地运行这段代码,先安装 scikit-learn。
from sklearn.feature_extraction.text import TfidfVectorizerfrom sklearn.metrics.pairwise import cosine_similarity
node_texts = [node["text"] for node in nodes]vectorizer = TfidfVectorizer(token_pattern=r"(?u)\b\w+\b")index_matrix = vectorizer.fit_transform(node_texts)
def retrieve(query): query_vec = vectorizer.transform([query]) scores = cosine_similarity(query_vec, index_matrix)[0] best_idx = scores.argmax() return nodes[best_idx]
print(retrieve("退款政策是什么"))预期输出:
{'doc_id': 'doc1', 'text': '课程购买后 7 天内且学习进度低于 20% 可退款。'}这段代码真正对应的抽象是什么?
Section titled “这段代码真正对应的抽象是什么?”它其实已经对应到:
- node
- index
- 检索器
也就是说,LlamaIndex 的很多价值,本质上都是在把这条知识链组织得更系统。
查询 Engine 为什么值得单独抽出来?
Section titled “查询 Engine 为什么值得单独抽出来?”因为问答不只等于“返回一个最像的段落”
Section titled “因为问答不只等于“返回一个最像的段落””实际系统里,你通常还要决定:
- 返回几条
- 是否要汇总
- 是否要带来源
- 是否要进一步调用模型
这时“查询引擎”就比“单个 retriever”更像一个系统层抽象。
一个极简 查询 Engine 示例
Section titled “一个极简 查询 Engine 示例”def query_engine(query): node = retrieve(query) return { "answer": node["text"], "source": node["doc_id"] }
print(query_engine("退款政策是什么"))预期输出:
{'answer': '课程购买后 7 天内且学习进度低于 20% 可退款。', 'source': 'doc1'}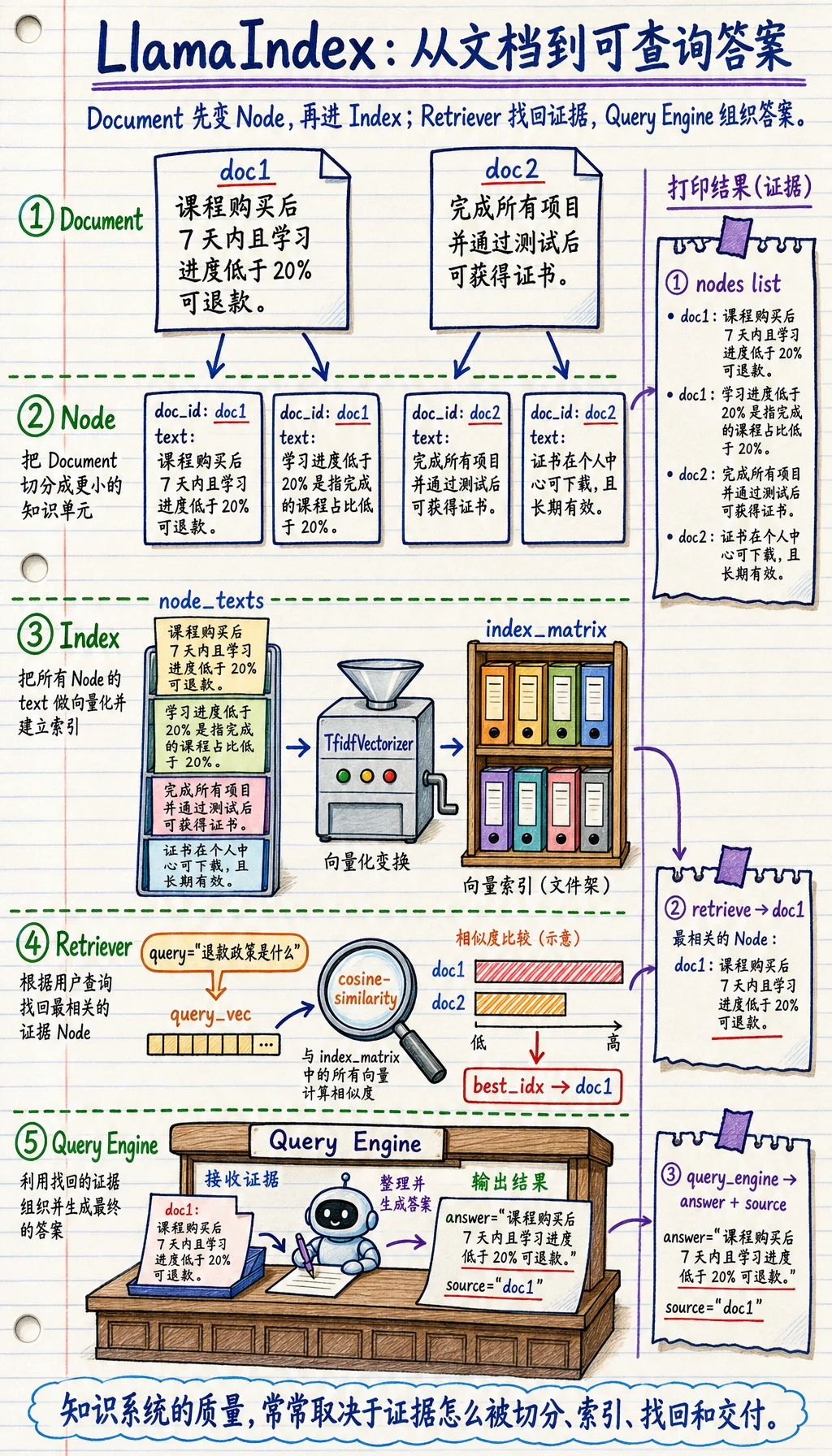
这个例子在教你:
检索只是中间层,最终还需要有一层把结果组织成面向用户的查询接口。
LlamaIndex 和 LangGraph 的差别,最核心的一句是什么?
Section titled “LlamaIndex 和 LangGraph 的差别,最核心的一句是什么?”如果要非常粗暴地总结,可以记成:
- LangGraph 更偏“任务状态怎么流”
- LlamaIndex 更偏“知识怎么组织”
当然现实里可以混搭,但它们的第一关注点确实不同。
所以如果你的项目本质上是:
- 文档问答
- 知识库助手
- RAG 主线
那么 LlamaIndex 这类抽象通常就会更顺手。
什么时候 LlamaIndex 不一定是重点?
Section titled “什么时候 LlamaIndex 不一定是重点?”如果你的系统更偏:
- 多 Agent 协作
- 复杂回路
- 显式状态机
那 LlamaIndex 可能就不是“主框架”,而更像知识层组件。
所以不要把它看成“万能 Agent 框架”,而要看成:
在知识和检索问题上特别顺手的一种框架。
初学者最常踩的坑
Section titled “初学者最常踩的坑”只看模型,不看文档摄取
Section titled “只看模型,不看文档摄取”很多知识系统问题,其实都出在文档入口。
觉得索引做好了就等于问答系统完成了
Section titled “觉得索引做好了就等于问答系统完成了”索引只是中间层,不是产品终点。
不知道它和工作流型框架的边界
Section titled “不知道它和工作流型框架的边界”这样很容易期待它去解决并不属于它最强项的问题。
学完这一页,至少保留这张证据卡:
- 问题形态
- 工作流图、检索应用、角色团队或实验
- 框架选择
- 它增加了什么抽象,以及隐藏了什么控制
- 追踪记录
- 状态、节点、tool 调用、消息或运行 id
- 失败检查
- 框架魔法隐藏状态、重试或权限问题
- 决策
- 只有在单代理循环清晰后才选择框架
这一节最重要的不是记住 LlamaIndex 的接口,而是理解:
LlamaIndex 的价值,在于把文档知识从原始文本一路组织成可检索、可引用、可查询的结构。
一旦你把它看成“知识组织框架”而不是“万能框架”,很多判断就会清楚很多。
- 用自己的话解释 Document、Node、Index、检索器、查询 Engine 各自像什么。
- 想一想:为什么说文档摄取质量会直接影响后面的检索效果?
- 用自己的知识库数据再造 3 条节点,重新跑一遍检索示例。
- 说明:如果系统主线是多 Agent 协作而不是知识检索,为什么 LlamaIndex 不一定应该做“总框架”?
解题思路与讲解
- Document 是原始材料,Node 是可检索的片段,Index 是组织好的搜索结构,Retriever 负责选出相关节点,Query Engine 把检索和回答生成组合起来。
- 文档摄入质量重要,是因为糟糕切分、缺失 metadata、解析噪声都会在后面变成检索失败。如果正确证据没有进入上下文,模型就很难答好。
- 用自己的数据重跑时,应该能看到哪些节点被选中以及原因。如果结果弱,优先检查 chunk size、overlap、metadata,以及 query 用词是否和文档一致。
- 如果主问题是多 Agent 协作,LlamaIndex 仍可用于知识检索,但不一定适合作为主编排框架,因为它最强的抽象入口是文档和索引。