1.4.2 AI Coding Agent 工作流
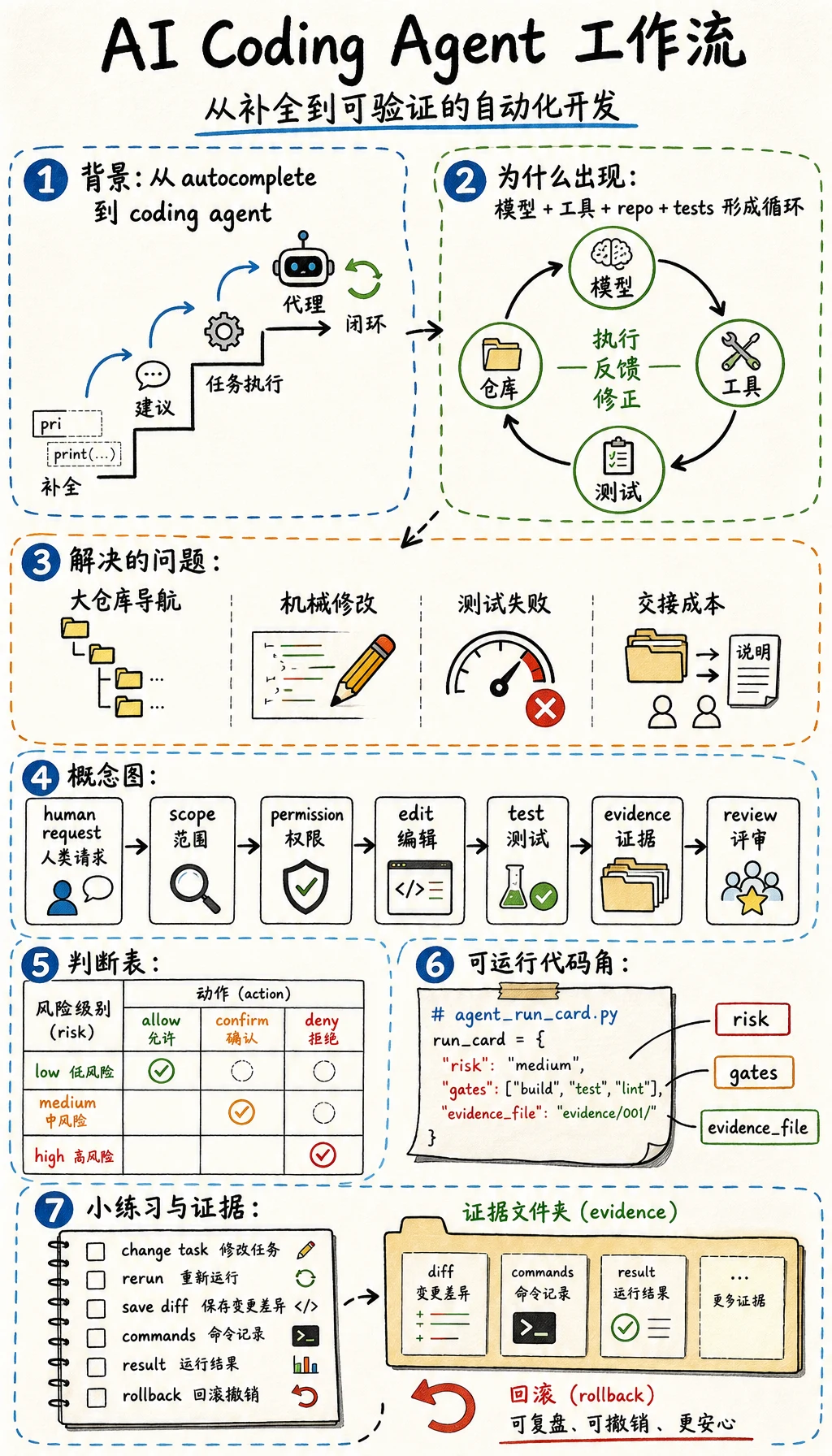
AI 编程 Agent 已经不只是“补全代码”。现在的 Codex 和 Google Antigravity 这类工具,可以阅读仓库、修改文件、运行测试,并留下任务轨迹。但它真正有用的前提是:任务要窄,权限要清楚,结果要能证明。
这一节先教工作流,而不是先追求“自动完成”。学完以后,你应该能写出一个可以交给别人审阅的 Agent 运行卡。
为什么这项技术会出现
Section titled “为什么这项技术会出现”早期 AI 编程更像在回答“这个函数怎么写”。Agentic Coding 解决的是另一个问题:
模型能不能在真实仓库里阅读上下文、改代码、验证结果,并把风险讲清楚?
它能出现,是因为模型推理、工具调用、长上下文、终端执行和代码审查界面共同成熟,形成了一个闭环:
- 阅读仓库和约束。
- 制定小范围计划。
- 修改文件。
- 运行测试或检查。
- 总结证据。
- 风险高时交给人审查。
它解决的深层问题不是“写代码更快”,而是降低交接成本:Agent 可以收集上下文、完成小范围改动,并把证据打包给人。
它解决什么问题
Section titled “它解决什么问题”| 编程中的问题 | Agent 做什么 | 人做什么 | 需要留下什么证据 |
|---|---|---|---|
| 大仓库难找入口 | 搜索文件、定位入口、判断可能归属 | 确认需求范围 | 搜索记录和改动文件 |
| 小 bug 需要大量机械修改 | 一致地改动和格式化 | 检查意图和产品行为 | diff、测试、截图 |
| 测试失败但原因不明 | 读日志、隔离失败层、提出修复 | 判断修复是否在范围内 | 失败命令和修复后命令 |
| 重构风险被隐藏 | 先输出风险卡再改 | 批准、收窄或拒绝 | 风险等级和回滚说明 |
| 审查太耗时 | 总结每个改动存在的原因 | 审查行为和边界情况 | commit 信息和 QA 记录 |
把任务交给 Agent 前,先看这张表。
| 场景 | 适合的 Agent 任务 | 不适合的第一任务 | 必须通过的关卡 |
|---|---|---|---|
| 一个单测失败 | “修这个测试并解释根因” | “重写整个模块” | 跑失败测试和邻近测试 |
| UI 文案或布局问题 | “调整这个区域并截图验证” | “重新设计整个应用” | 浏览器截图 |
| 新增课程页 | “按现有模板添加一页” | “重新发明课程结构” | 链接检查和课程 QA |
| 安全或数据删除 | “检查并提出补丁计划” | “直接执行破坏性清理” | 人工批准 |
| 依赖升级 | “评估破坏性变化并升级一个包” | “全部升级” | lockfile diff 和构建 |
可运行实验:生成 Agent 运行卡
Section titled “可运行实验:生成 Agent 运行卡”创建 agent_run_card.py,用 Python 3.10 或更高版本运行。
import jsonfrom pathlib import Path
task = { "request": "fix a broken course sidebar link", "files_likely_touched": ["src/content/docs", "astro.config.mjs"], "can_run_tests": True, "touches_user_data": False, "changes_public_behavior": True,}
def classify_risk(info): if info["touches_user_data"]: return "high" if info["changes_public_behavior"]: return "medium" return "low"
def choose_gates(info): gates = ["read surrounding files", "make minimal patch", "record diff"] if info["can_run_tests"]: gates.append("run relevant QA command") if info["changes_public_behavior"]: gates.append("capture before/after behavior") return gates
run_card = { "task": task["request"], "agent_scope": "one narrow bug or content fix", "risk": classify_risk(task), "permissions": { "read": True, "edit": True, "network": False, "destructive_commands": False, }, "gates": choose_gates(task), "evidence_file": "agent_evidence.md",}
Path("agent_run_card.json").write_text(json.dumps(run_card, indent=2), encoding="utf-8")print(json.dumps(run_card, indent=2))预期输出:
{ "task": "fix a broken course sidebar link", "agent_scope": "one narrow bug or content fix", "risk": "medium", "permissions": { "read": true, "edit": true, "network": false, "destructive_commands": false }, "gates": [ "read surrounding files", "make minimal patch", "record diff", "run relevant QA command", "capture before/after behavior" ], "evidence_file": "agent_evidence.md"}task 是输入契约。它说明人想要什么、可能涉及哪些文件、是否存在风险。
classify_risk() 是权限门。Agent 不能把“改错别字”和“迁移用户数据”当成同一类任务。
choose_gates() 把任务变成验证步骤。它让结果从“我改了”变成“我改了、检查了、能展示证据”。
run_card 是交付物。在真实仓库里,可以把它放进 PR、commit 信息或任务记录。
把 request 改成下面任意一个任务,再运行脚本:
- “更新首页 meta description”
- “删除旧用户账户”
- “新增一个 API endpoint”
每次都回答:
| 问题 | 要判断什么 |
|---|---|
| 风险是低、中还是高? | 说明原因,不只写标签 |
| 需要增加什么关卡? | 测试、截图、安全审查、迁移备份或人工批准 |
| 什么证据能说服审查者? | diff、日志、截图、请求/响应或回滚说明 |
任何 AI 编程任务结束前,至少留下这组材料:
- Request
- 人提出的原始需求
- Scope
- 有意触碰的文件或行为
- Risk
- 低、中或高
- Commands
- 运行过的检查命令
- Result
- 通过、失败,或未运行及原因
- Diff Summary
- 改了什么以及为什么
- Rollback
- 如何回退,或对应 commit 在哪里
AI 编程 Agent 最适合被当成“手很快、笔记很严”的初级工程师。给它窄任务,明确权限,运行检查,并要求留下证据。
检查理解
能把一个模糊需求改写成运行卡,说出风险,选择验证关卡,并解释审查者应该看什么证据,就算通过本节。