10.4.4 分割实战
- 学会定义一个最小分割项目
- 理解 mask 数据和指标的基本组织方式
- 通过可运行示例建立项目评估直觉
- 学会展示分割项目里最重要的结果
先建立一张地图
Section titled “先建立一张地图”如果你刚学完语义分割和实例分割,这一节最自然的续接就是:
- 前面你已经知道 mask 和 IoU 这些对象在干什么
- 这一节开始问“如果把它做成一个真正项目,哪些环节最容易先出问题”
所以这节真正重要的不是新网络,而是:
- mask 标注
- 类别定义
- 评估方式
- 失败样本展示
分割实战这节最适合新人的理解顺序不是“直接训一个模型”,而是先看清项目闭环:
flowchart LR A["定义任务和类别"] --> B["准备 mask 数据"] B --> C["先做 baseline"] C --> D["按 IoU 评估"] D --> E["分析失败样本"]所以这节真正想解决的是:
- 分割项目到底该怎么推进
- 除了模型之外,项目真正容易出问题的环节在哪里
一个更适合新人的总类比
Section titled “一个更适合新人的总类比”你可以把分割项目想成:
- 给一批地图做精细涂色
难点不只是“能不能涂上颜色”,而是:
- 每一块边界是不是涂准了
- 小区域有没有被漏掉
- 大家是不是按同一套标准在涂
这样理解后,为什么分割项目会特别依赖:
- mask 质量
- 边界标准
- 失败样本分析
就会自然很多。
一、项目问题怎么定?
Section titled “一、项目问题怎么定?”一个很适合练手的分割项目是:
- 道路场景分割
或:
- 医疗区域分割
共同特点:
- mask 标签清楚
- 区域边界重要
- IoU 指标有意义
新人第一次做分割项目,题目怎么选更稳?
Section titled “新人第一次做分割项目,题目怎么选更稳?”更稳的题目通常有这几个特点:
- 类别数不要太多
- 区域边界相对清楚
- 失败样本容易肉眼看懂
所以第一次做项目时, “少类别、强边界、好解释”通常比“任务看起来更炫”更重要。
为什么“边界清楚”这件事这么重要?
Section titled “为什么“边界清楚”这件事这么重要?”因为分割任务的很多难点都集中在:
- 边界
- 小区域
- 类别混杂处
如果一开始就选一个边界特别模糊、标注标准也不稳定的任务, 你会很难判断:
- 是模型不行
- 还是标签本身就不稳
二、先跑一个最小分割项目评估示例
Section titled “二、先跑一个最小分割项目评估示例”pred_masks = [ [[0, 0, 1], [0, 1, 1], [0, 0, 1]], [[1, 1, 0], [1, 0, 0], [1, 0, 0]],]
gt_masks = [ [[0, 0, 1], [0, 1, 1], [0, 1, 1]], [[1, 1, 0], [1, 1, 0], [1, 0, 0]],]
def iou(mask_a, mask_b, target=1): inter = 0 union = 0 for row_a, row_b in zip(mask_a, mask_b): for a, b in zip(row_a, row_b): if a == target and b == target: inter += 1 if a == target or b == target: union += 1 return inter / union if union else 0.0
ious = [iou(pred, gt) for pred, gt in zip(pred_masks, gt_masks)]mean_iou = sum(ious) / len(ious)
print("ious:", [round(x, 4) for x in ious])print("mean_iou:", round(mean_iou, 4))预期输出:
ious: [0.8, 0.8]mean_iou: 0.8这说明这个玩具数据集里的两个样本表现差不多。真实报告里要保留逐样本分数,因为平均值很容易掩盖边界样本。
这个示例最想表达什么?
Section titled “这个示例最想表达什么?”分割项目最终最重要的通常不是:
- 某一张图看起来还行
而是:
- 一组样本整体表现怎样
所以项目里通常都要汇总:
- per-sample IoU
- mean IoU
为什么分割项目特别需要“逐样本回看”?
Section titled “为什么分割项目特别需要“逐样本回看”?”因为均值非常容易掩盖问题。
例如:
- 大区域类别分得不错
- 小区域目标全错
这时平均分可能看着还行,但项目其实并不稳。
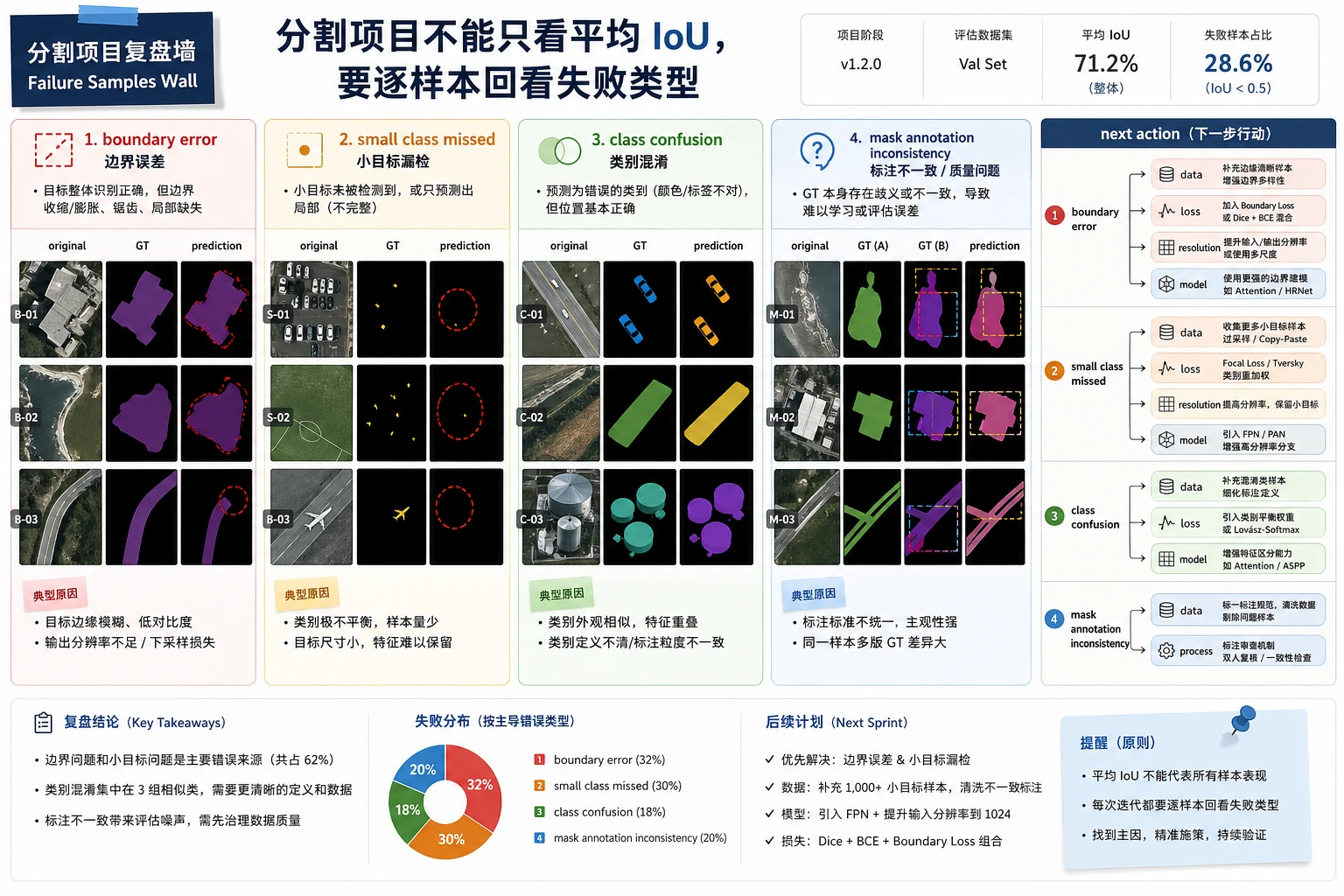
第一次做分割项目时,最值得先分哪几类失败?
Section titled “第一次做分割项目时,最值得先分哪几类失败?”一个很实用的失败分类方式是:
-
边界错 轮廓大致对,但边缘很粗糙。
-
小类别漏掉 大背景分得不错,小目标却总缺。
-
类别混淆 两类区域彼此粘在一起。
这三类一分开,你会更容易决定:
- 该补数据
- 该改损失
- 还是该改模型输入分辨率
再看一个最小“项目检查表”示例
Section titled “再看一个最小“项目检查表”示例”checklist = { "classes_defined": True, "mask_quality_checked": True, "baseline_ready": True, "failure_buckets_defined": False,}
def next_step(checklist): if not checklist["classes_defined"]: return "先把类别定义收窄。" if not checklist["mask_quality_checked"]: return "先抽样检查 mask 标注质量。" if not checklist["baseline_ready"]: return "先做最小 baseline。" if not checklist["failure_buckets_defined"]: return "先把失败样本分桶。" return "可以继续做针对性优化。"
print(next_step(checklist))预期输出:
先把失败样本分桶。基线和 mask 抽检都已经准备好,所以下一步还不是“换更大的模型”,而是先把失败样本分组,让下一轮改动有明确目标。
这个例子很小,但很适合帮助新人理解:
- 项目不是只看模型训练跑没跑
- 还要看项目骨架有没有搭完整
三、分割项目最容易踩的坑
Section titled “三、分割项目最容易踩的坑”mask 标注边界不一致
Section titled “mask 标注边界不一致”这会让训练和评估一起受污染。
类别太不平衡
Section titled “类别太不平衡”小区域类别经常被主背景淹没。
只看均值,不看失败样本
Section titled “只看均值,不看失败样本”均值可能掩盖一些特别糟的案例。
只展示成功样本,不展示边界失败
Section titled “只展示成功样本,不展示边界失败”分割项目最容易“看起来不错”, 因为彩色 mask 图本身就很有视觉冲击力。 但如果你不展示:
- 边界失败
- 小目标漏检
- 类别混淆
就很难判断这个项目到底哪里还不稳。
四、一个新人可直接照抄的推进顺序
Section titled “四、一个新人可直接照抄的推进顺序”更建议这样做:
- 先明确类别定义
- 再抽样检查 mask 标注
- 先做一个最小 baseline
- 再统一评估 IoU
- 最后挑失败样本单独分析
这样会比一上来就换模型更有效。
如果把它做成作品集,最值得展示什么?
Section titled “如果把它做成作品集,最值得展示什么?”比起只贴一张彩色 mask 图,更值得展示的是:
- 原图 / GT / 预测三联图
- per-class IoU
- 几类典型失败样本
- 你怎么解释这些失败
- 下一步你会先改哪里
如果你第一次做这类项目,最稳的默认目标
Section titled “如果你第一次做这类项目,最稳的默认目标”第一次做时,最推荐的不是追求:
- 很多类别
- 很复杂的模型
- 很炫的可视化
而是先做到:
- 类别定义清楚
- mask 质量可解释
- baseline 能稳定跑通
- IoU 和失败样本能讲清楚
做到这四件事,项目就已经很像真正的项目了。
学完这一页,至少保留这张证据卡:
- 输入图像
- 原始图像和目标掩膜或类别图
- 预测
- 预测掩膜、叠加可视化和边界示例
- 指标
- IoU、Dice、每类得分和边界失败备注
- 失败检查
- 标注质量、边界过窄、小区域或类别混淆
- 期望产出
- 掩膜叠加图,以及分割指标汇总
这节最重要的是建立一个项目意识:
分割项目的核心,不只是模型训练,还包括 mask 标签质量、IoU 评估和失败样本分析。
这节最该带走什么
Section titled “这节最该带走什么”- 分割项目首先是数据和评估项目,其次才是模型项目
- mask 标注质量会直接决定上限
- 失败样本分析在分割项目里尤其重要
如果再压成一句话,那就是:
分割项目真正的难点,不只是让模型会画 mask,而是让每一类区域的边界、覆盖和错误都能被清楚解释。
- 再构造一组
pred_masks和gt_masks,观察mean_iou如何变化。 - 为什么分割项目里 mask 标注标准尤其重要?
- 如果某类目标区域很小,为什么 IoU 会特别敏感?
- 你会怎样把一个分割项目做成作品集页面?
项目交付参考与讲解
- 修改
pred_masks后,漏掉 mask、类别错误或边界差都会让mean_iou下降。还要看 class-wise IoU,避免一个简单类别掩盖另一个类别的失败。 - mask 标注标准很重要,因为边界厚度、忽略区域和模糊边缘都会直接定义训练目标和评估方式。
- 对于很小的区域,几个像素错误就会让 intersection 和 union 的比例大幅变化,所以 IoU 特别敏感。
- 作品集页面应展示问题定义、mask 规则、IoU/Dice 指标、叠加图示例、失败案例、限制和下一步计划。