5.3.4 异常检测
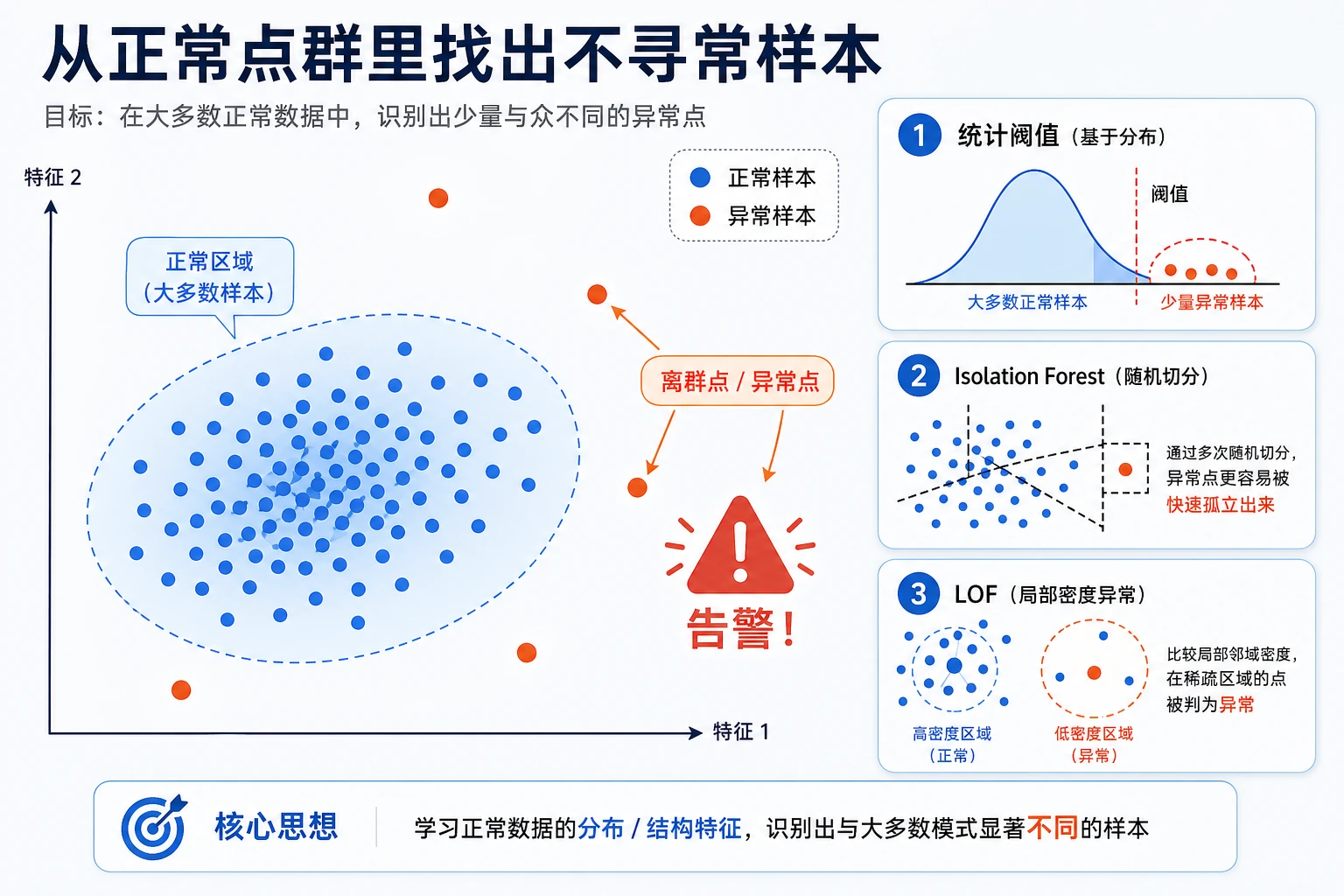
你会做出什么
Section titled “你会做出什么”这一节会完成一个实用告警实验:
- 创建正常点和合成异常点;
- 调整 Isolation Forest 的
contamination; - 查看异常分数;
- 比较 Isolation Forest 与 LOF;
- 把 precision、recall、误报和漏报读成产品取舍。
先看图。异常检测的核心是决定什么要报警,以及每种错误有多贵。
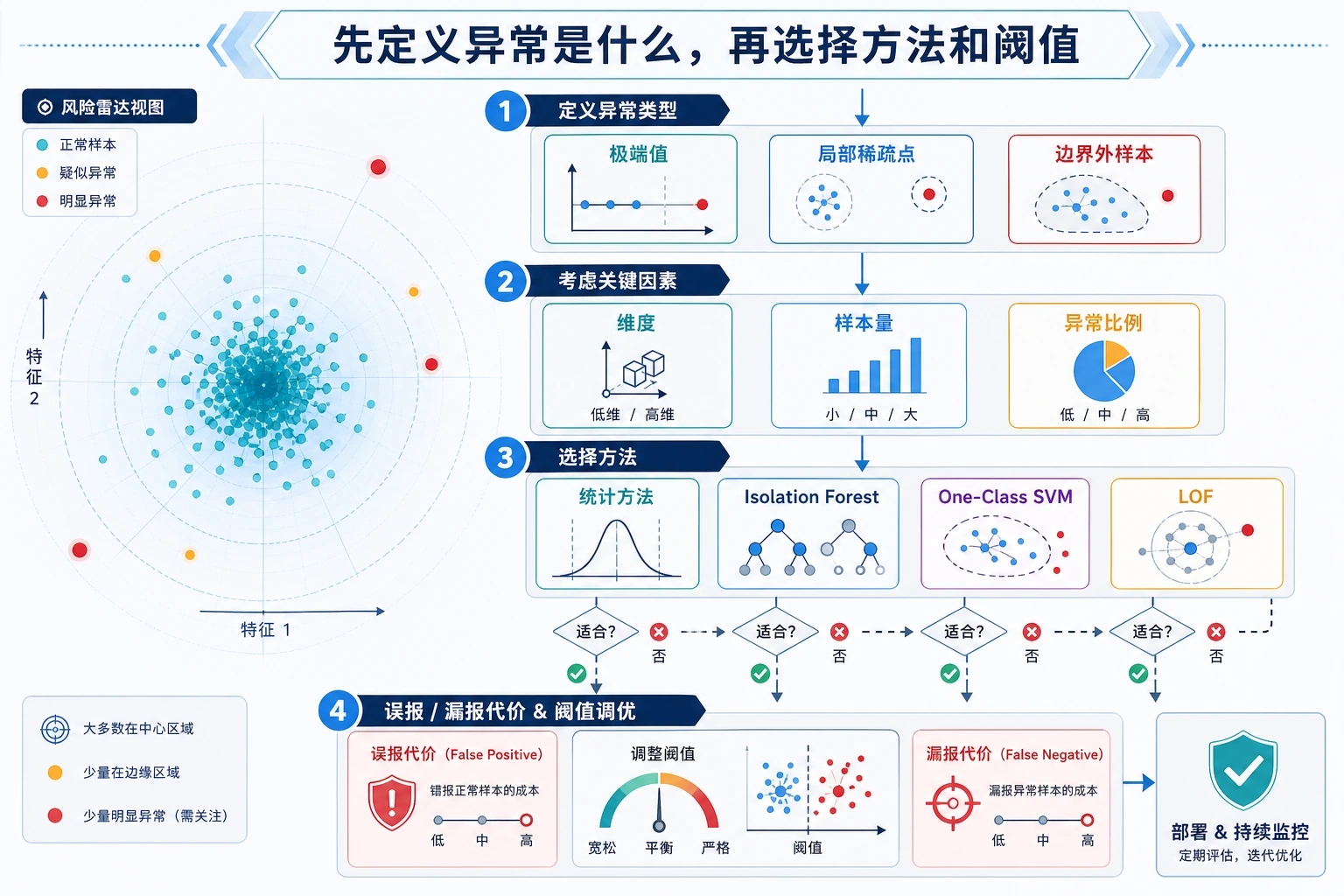
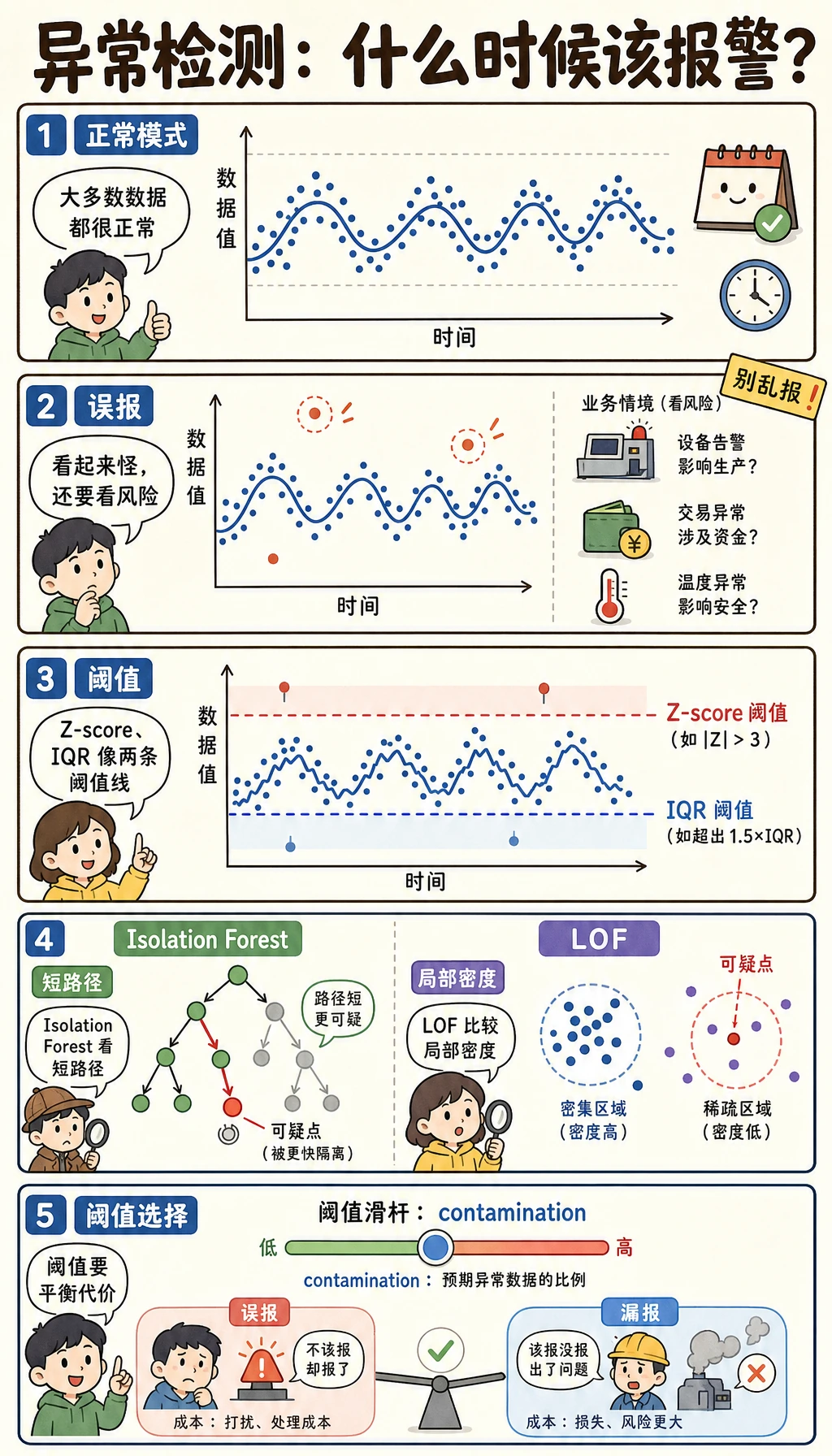
| 术语 | 实用含义 |
|---|---|
anomaly | 不符合正常模式的样本 |
outlier | 离大多数点较远的点 |
contamination | 预期异常比例,可作为阈值线索 |
score_samples | 模型分数;对 Isolation Forest 来说,越低越异常 |
false positive | 正常样本被误报为可疑 |
false negative | 真实异常没有被发现 |
IsolationForest | 基于树的方法,能较快隔离异常点 |
LOF | Local Outlier Factor,比较每个点周围的局部密度 |
python -m pip install -U scikit-learn numpy这个实验使用合成标签,只是为了让课程可验证。真实异常检测里,标签经常缺失、延迟或不完整。
运行完整实验
Section titled “运行完整实验”新建 anomaly_lab.py:
import numpy as npfrom sklearn.datasets import make_blobsfrom sklearn.ensemble import IsolationForestfrom sklearn.metrics import confusion_matrix, f1_score, precision_score, recall_scorefrom sklearn.neighbors import LocalOutlierFactorfrom sklearn.preprocessing import StandardScaler
normal, _ = make_blobs(n_samples=360, centers=2, cluster_std=0.75, random_state=42)rng = np.random.default_rng(42)outliers = rng.uniform(low=-8, high=8, size=(24, 2))X = np.vstack([normal, outliers])y_true = np.array([0] * len(normal) + [1] * len(outliers)) # 1 means anomalyX_scaled = StandardScaler().fit_transform(X)
print("isolation_forest_contamination_lab")for contamination in [0.03, 0.06, 0.12]: model = IsolationForest(contamination=contamination, random_state=42) pred = model.fit_predict(X_scaled) y_pred = (pred == -1).astype(int) tn, fp, fn, tp = confusion_matrix(y_true, y_pred).ravel() print( f"contamination={contamination:.2f} " f"flagged={int(y_pred.sum())} " f"precision={precision_score(y_true, y_pred):.3f} " f"recall={recall_score(y_true, y_pred):.3f} " f"f1={f1_score(y_true, y_pred):.3f} " f"fp={fp} fn={fn}" )
print("score_inspection")best = IsolationForest(contamination=0.06, random_state=42)best.fit(X_scaled)scores = best.score_samples(X_scaled) # lower means more abnormalorder = np.argsort(scores)[:5]for idx in order: print(f"index={idx:<3} score={scores[idx]:.3f} true_anomaly={bool(y_true[idx])}")
print("lof_comparison")lof = LocalOutlierFactor(n_neighbors=20, contamination=0.06)y_pred = (lof.fit_predict(X_scaled) == -1).astype(int)print( f"flagged={int(y_pred.sum())} " f"precision={precision_score(y_true, y_pred):.3f} " f"recall={recall_score(y_true, y_pred):.3f} " f"f1={f1_score(y_true, y_pred):.3f}")运行:
python anomaly_lab.py预期输出:
isolation_forest_contamination_labcontamination=0.03 flagged=12 precision=1.000 recall=0.500 f1=0.667 fp=0 fn=12contamination=0.06 flagged=23 precision=0.826 recall=0.792 f1=0.809 fp=4 fn=5contamination=0.12 flagged=46 precision=0.478 recall=0.917 f1=0.629 fp=24 fn=2score_inspectionindex=371 score=-0.747 true_anomaly=Trueindex=368 score=-0.738 true_anomaly=Trueindex=373 score=-0.734 true_anomaly=Trueindex=364 score=-0.725 true_anomaly=Trueindex=378 score=-0.717 true_anomaly=Truelof_comparisonflagged=23 precision=0.870 recall=0.833 f1=0.851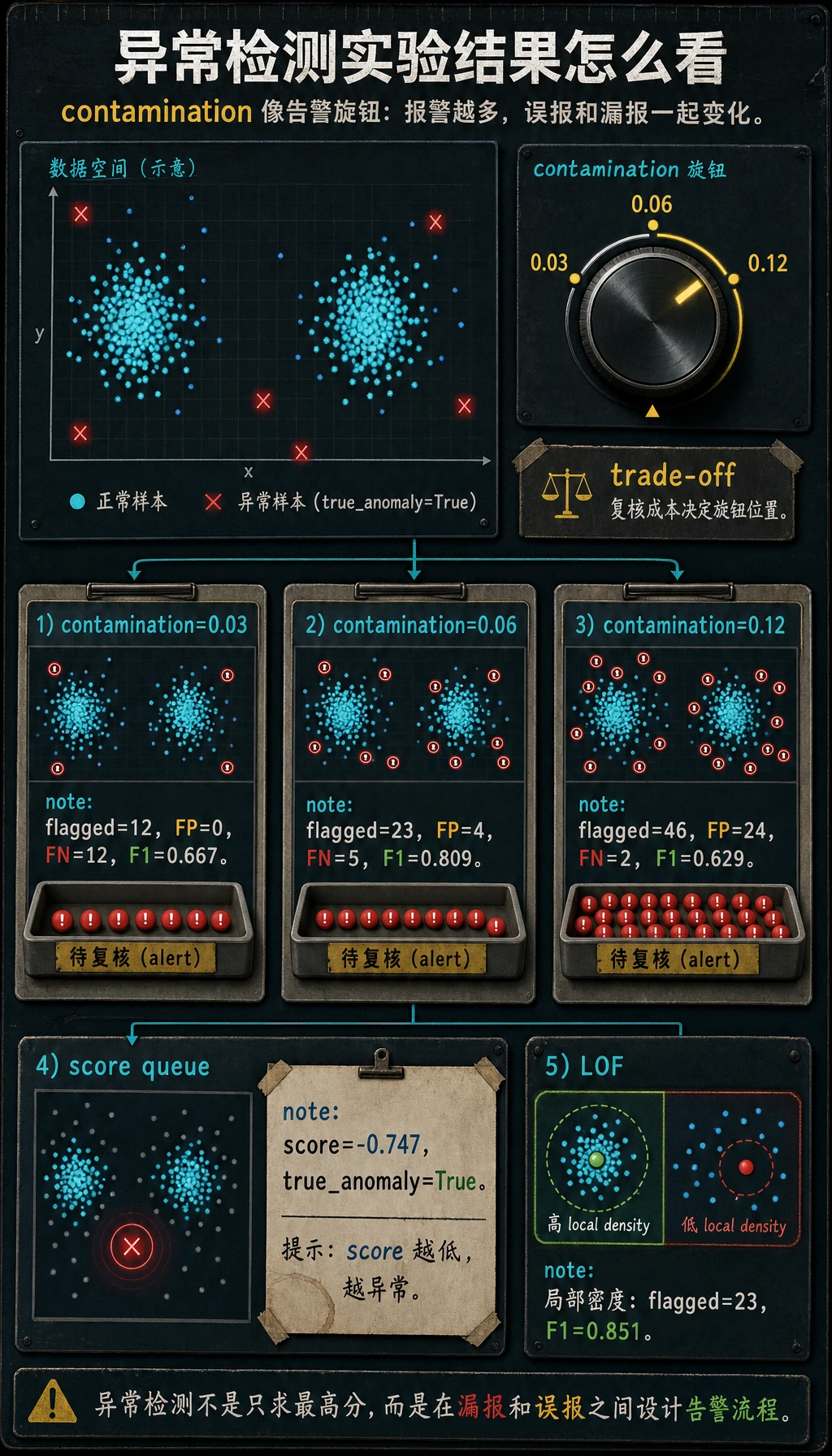
读懂告警取舍
Section titled “读懂告警取舍”contamination 会影响模型预期标记多少样本:
contamination=0.03 flagged=12 precision=1.000 recall=0.500contamination=0.12 flagged=46 precision=0.478 recall=0.917这和分类阈值是同一种取舍:
- contamination 较低:告警少,误报少,漏报多;
- contamination 较高:告警多,召回更高,误报也更多。
正确选择不只是数学问题。如果漏掉一次欺诈代价很高,可以接受更多误报。如果人工复核很贵,就可能更偏向少量高置信告警。
Isolation Forest
Section titled “Isolation Forest”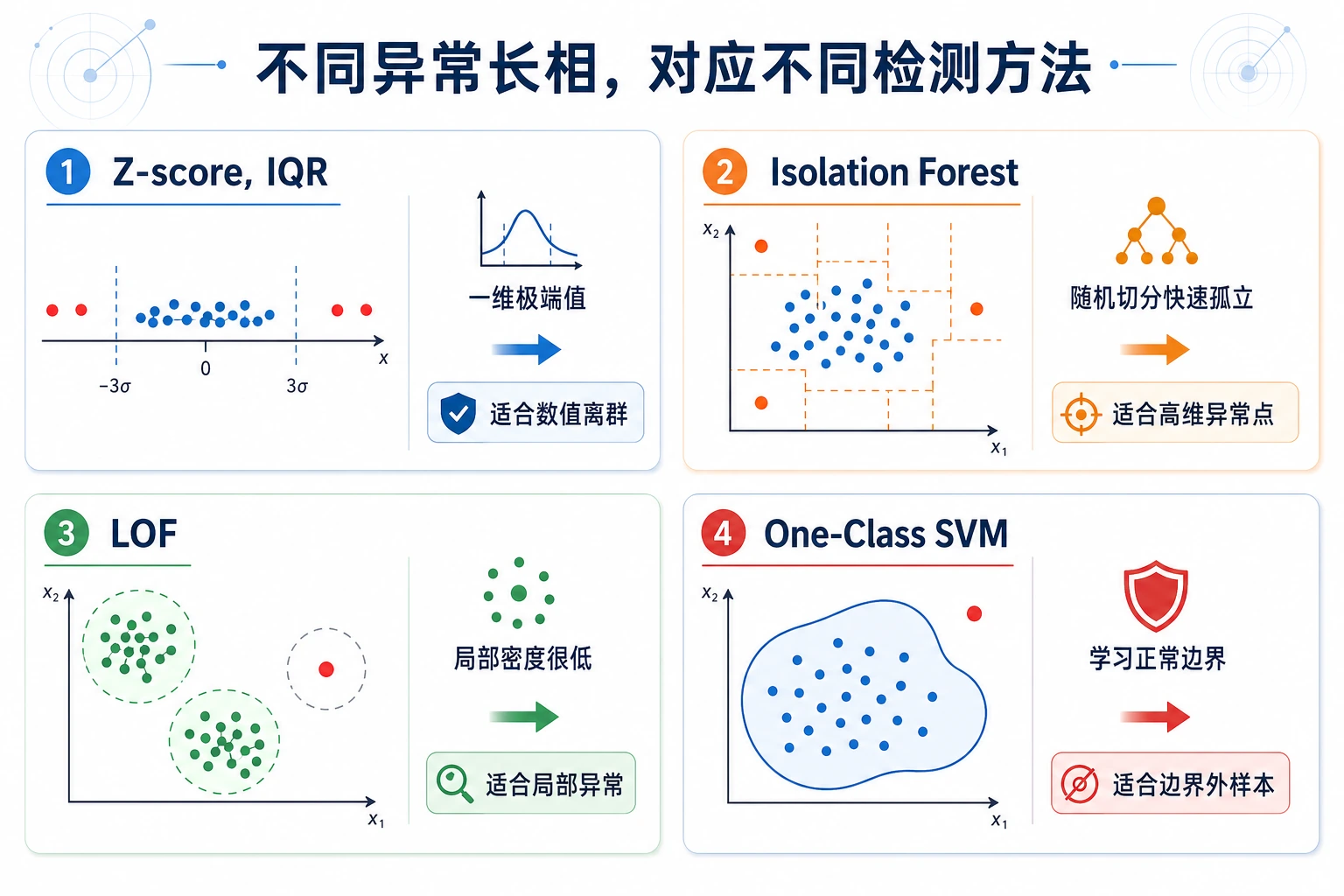
Isolation Forest 会构建随机划分树。异常点通常更容易被少数几次划分隔离出来,所以会得到更异常的分数。
实验中:
scores = best.score_samples(X_scaled)对 Isolation Forest 来说,分数越低越异常。最可疑的几个样本确实是合成异常:
index=371 score=-0.747 true_anomaly=True当你要建立复核队列,而不是只做是/否判断时,分数比硬标签更有用。
LOF:局部密度
Section titled “LOF:局部密度”LOF 会比较一个点周围的密度和邻居周围的密度。它适合发现“全局不一定很远,但在局部很奇怪”的点。
在这个合成实验里:
lof_comparisonflagged=23 precision=0.870 recall=0.833 f1=0.851LOF 稍微优于 Isolation Forest。但这不代表它永远更好,只说明局部密度假设更适合这个数据。
如何选择方法
Section titled “如何选择方法”| 情况 | 优先尝试 | 原因 |
|---|---|---|
| 通用表格异常基线 | Isolation Forest | 快、稳、容易调 |
| 局部密度异常 | LOF | 能发现相对邻居很奇怪的点 |
| 单列数值检查 | Z-score 或 IQR | 透明、便宜 |
| 高维 embedding | Isolation Forest + 邻居检查 | 同时看分数和近邻 |
| 需要告警运营 | 任意模型 + 阈值/复核流程 | 运营和模型分数同样重要 |
给有经验的读者:异常检测要结合延迟标签、复核能力、告警疲劳和漂移监控评估。离线 F1 最高的模型,未必适合复核团队承接。
学完这一页,至少保留这张证据卡:
- 任务
- 聚类、降维或异常检测目标
- 数据视图
- 缩放后的特征、投影、聚类或异常分数
- 解释
- 该场景中各组、坐标轴或告警的含义
- 失败检查
- 任意簇数、缩放问题、噪声维度或误报
- 期望产出
- 带解释和不确定性说明的无监督结果
常见排查清单
Section titled “常见排查清单”| 现象 | 可能原因 | 修复方式 |
|---|---|---|
| 告警太多 | contamination 或阈值太高 | 降低 contamination,增加分层复核 |
| 漏掉很多异常 | 阈值太严格 | 提高 contamination,增加弱规则,监控 recall |
| 新数据进来后分数分布变了 | 数据分布漂移 | 持续监控分数分布 |
| 模型标记明显的尺度问题 | 特征没有缩放 | 先缩放数值特征 |
| 没有标签可评估 | 异常检测常见现实 | 抽样复核、收集反馈、跟踪延迟结果 |
- 把合成异常点数量从
24改成12和48。contamination应该怎么调整? - 把异常点范围改近一点,例如
low=-5, high=5。哪个方法受影响更大? - 添加一个尺度特别大的第四个特征。缩放前后结果有什么变化?
- 不用固定阈值,按
score_samples()排序查看前 20 个样本。 - 设计一个三层告警队列:立即复核、稍后复核、忽略。
参考实现与讲解
contamination应大致接近预期异常比例,例如12 / total_samples或48 / total_samples。真实项目里它是运营假设,需要用人工复核结果校准。- 异常点靠近正常簇后,所有方法都会更难。依赖局部密度或边界分离的方法可能漏报更多;不要只看一个分数,要检查排序靠前的样本。
- 大尺度特征在缩放前可能主导距离和异常分数。缩放后,模型才更可能根据模式差异而不是单位大小判断异常。
- 按
score_samples()排序更适合运营,因为即使阈值还没确定,分析员也能先看最可疑的一批样本。 - 三层队列可以把最可疑的少量样本放入“立即复核”,中间一批“稍后复核”,其余忽略;具体比例应由复核能力和误报成本决定。
你能解释下面几点,就完成本节:
- 异常检测是告警流程,不只是模型;
contamination会改变误报/漏报取舍;- Isolation Forest 会快速隔离不寻常点;
- LOF 会发现局部密度异常;
- 查看分数排序通常比单个是/否标签更有用。