11.6.6 Transformers 库实战
- 理解
transformers库里最常见的几个对象分别干什么 - 学会区分 tokenizer、config、model、pipeline 的角色
- 离线跑通一个 tokenizer + model 的最小示例
- 理解实际项目里怎样从“能跑”走向“可维护”
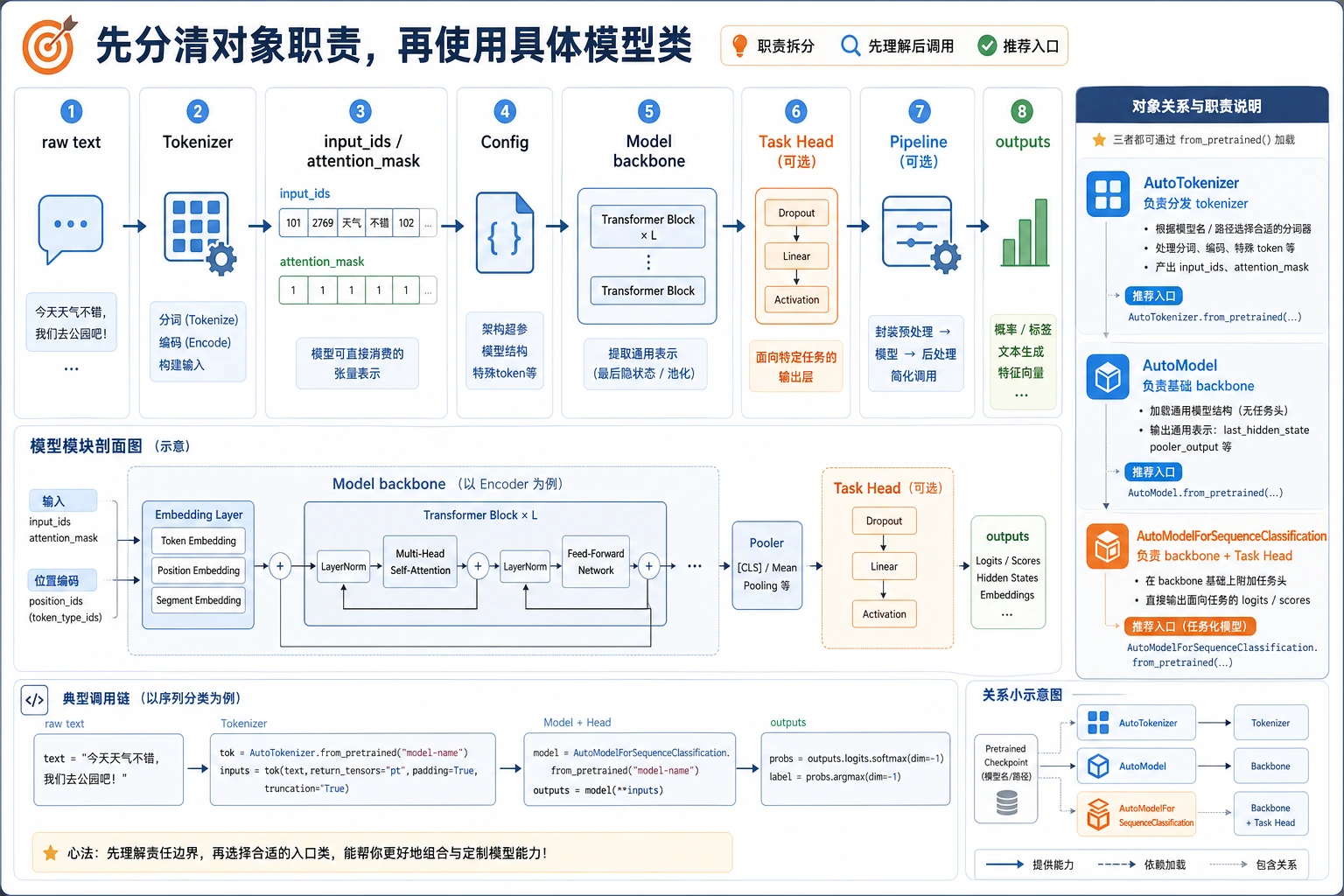
一、先把库里的几个主角分清楚
Section titled “一、先把库里的几个主角分清楚”Tokenizer
Section titled “Tokenizer”负责把文本变成模型能吃的数字序列。
Config
Section titled “Config”负责描述模型结构参数,比如:
- hidden size
- 层数
- 头数
真正负责前向计算。
Pipeline
Section titled “Pipeline”是更高层的封装,帮你把:
- 分词
- 前向
- 后处理
串成一个更方便调用的接口。
一句话记:
tokenizer 负责进门,model 负责计算,pipeline 负责把整件事串起来。
二、为什么很多人第一次用 transformers 会晕?
Section titled “二、为什么很多人第一次用 transformers 会晕?”因为它有两层世界:
你知道:
- BERT 是 encoder-only
- GPT 是 decoder-only
你又会遇到:
AutoTokenizerAutoModelAutoModelForSequenceClassificationpipelinefrom_pretrained
初学者经常会卡在:
名字太多,但不知道每个接口到底解决什么问题。
所以这一节的核心不是背接口,而是建立调用顺序的地图。
三、先离线构造一个最小 tokenizer
Section titled “三、先离线构造一个最小 tokenizer”为什么不直接下载现成模型?
Section titled “为什么不直接下载现成模型?”因为教程要尽量保证你在没有外网时也能跑通。
所以这里我们手工准备一个超小 vocab.txt,让你真正理解 tokenizer 在做什么。
from pathlib import Pathfrom tempfile import TemporaryDirectoryfrom transformers import BertTokenizer
vocab_tokens = [ "[PAD]", "[UNK]", "[CLS]", "[SEP]", "[MASK]", "我", "爱", "自", "然", "语", "言", "处", "理", "北", "京"]
with TemporaryDirectory() as tmpdir: vocab_path = Path(tmpdir) / "vocab.txt" vocab_path.write_text("\n".join(vocab_tokens), encoding="utf-8")
tokenizer = BertTokenizer.from_pretrained(tmpdir)
encoded = tokenizer("我爱自然语言处理", return_tensors="pt")
print(encoded) print("tokens:", tokenizer.convert_ids_to_tokens(encoded["input_ids"][0]))预期输出:
{'input_ids': tensor([[ 2, 5, 6, 7, 8, 9, 10, 11, 12, 3]]), 'token_type_ids': tensor([[0, 0, 0, 0, 0, 0, 0, 0, 0, 0]]), 'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1]])}tokens: ['[CLS]', '我', '爱', '自', '然', '语', '言', '处', '理', '[SEP]']这里用临时目录,是为了跑完示例后不在项目根目录留下 vocab.txt。input_ids 是 token 编号,attention_mask 标记哪些位置有效。
这段代码在教你什么?
Section titled “这段代码在教你什么?”它在教你:
- tokenizer 不是魔法黑盒
- 它本质上是“词表 + 切分规则 + 编码规则”
- 输出里最关键的是
input_ids和attention_mask
四、再离线构造一个最小 BERT 模型
Section titled “四、再离线构造一个最小 BERT 模型”为什么用随机初始化模型?
Section titled “为什么用随机初始化模型?”因为我们现在的目标不是追求效果,而是:
真正看懂
transformers库里 model 对象是怎么接输入、吐输出的。
import torchfrom transformers import BertConfig, BertModel
config = BertConfig( vocab_size=15, hidden_size=32, num_hidden_layers=2, num_attention_heads=4, intermediate_size=64)
model = BertModel(config)
input_ids = torch.tensor([[2, 5, 6, 7, 8, 9, 10, 11, 12, 3]])attention_mask = torch.ones_like(input_ids)
outputs = model(input_ids=input_ids, attention_mask=attention_mask)
print("last_hidden_state shape:", outputs.last_hidden_state.shape)print("pooler_output shape :", outputs.pooler_output.shape)预期输出:
last_hidden_state shape: torch.Size([1, 10, 32])pooler_output shape : torch.Size([1, 32])这个随机模型适合用来学接口,不适合看效果。第一个形状表示:1 条样本、10 个 token 位置、每个位置 32 维隐藏表示。
你真正该看懂什么?
Section titled “你真正该看懂什么?”input_ids是 token 编号attention_mask告诉模型哪些位置有效last_hidden_state是每个位置的上下文化表示pooler_output更像句级表示之一
这几样东西看懂了,后面你再接分类头、匹配头、生成头就会轻松很多。
五、把 tokenizer 和 model 串起来
Section titled “五、把 tokenizer 和 model 串起来”from pathlib import Pathfrom tempfile import TemporaryDirectoryimport torchfrom transformers import BertTokenizer, BertConfig, BertModel
vocab_tokens = [ "[PAD]", "[UNK]", "[CLS]", "[SEP]", "[MASK]", "我", "爱", "自", "然", "语", "言", "处", "理"]
with TemporaryDirectory() as tmpdir: vocab_path = Path(tmpdir) / "vocab.txt" vocab_path.write_text("\n".join(vocab_tokens), encoding="utf-8")
tokenizer = BertTokenizer.from_pretrained(tmpdir)
config = BertConfig( vocab_size=len(vocab_tokens), hidden_size=32, num_hidden_layers=2, num_attention_heads=4, intermediate_size=64 ) model = BertModel(config)
batch = tokenizer(["我爱自然语言处理", "我爱语言"], padding=True, return_tensors="pt") outputs = model(**batch)
print("input_ids shape :", batch["input_ids"].shape) print("attention_mask shape :", batch["attention_mask"].shape) print("last_hidden_state shape:", outputs.last_hidden_state.shape)预期输出:
input_ids shape : torch.Size([2, 10])attention_mask shape : torch.Size([2, 10])last_hidden_state shape: torch.Size([2, 10, 32])tokenizer 会把较短句子 padding 到和较长句子一样长,所以 batch 才能变成规整的二维张量。
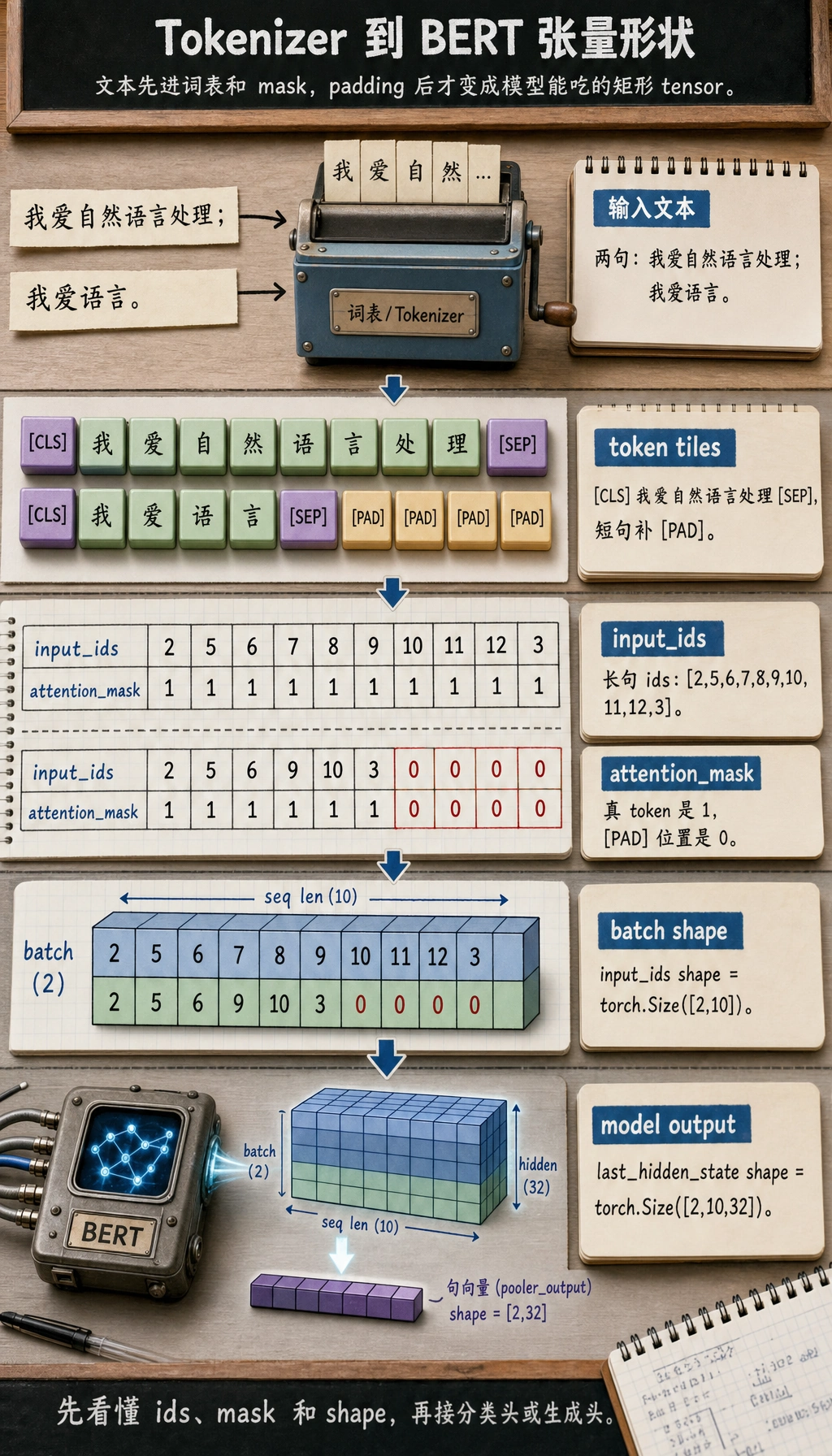
这就是最基础的真实调用链
Section titled “这就是最基础的真实调用链”真正项目里,最常见的底层流程就是:
- 文本 -> tokenizer
- tokenizer -> tensor
- tensor -> model
- model 输出 -> 后处理或任务头
你现在已经把这条链跑通了。
六、Auto* 系列接口是干什么的?
Section titled “六、Auto* 系列接口是干什么的?”为什么库里这么多 AutoModel?
Section titled “为什么库里这么多 AutoModel?”因为 transformers 想让你不用手写一堆模型类型判断。
例如:
AutoTokenizerAutoModelAutoModelForSequenceClassificationAutoModelForCausalLM
它们的设计目标是:
给一个模型名字或配置,就自动选合适的类。
一个离线的 AutoModel.from_config 示例
Section titled “一个离线的 AutoModel.from_config 示例”from transformers import AutoModel, BertConfig
config = BertConfig( vocab_size=20, hidden_size=16, num_hidden_layers=1, num_attention_heads=4, intermediate_size=32)
model = AutoModel.from_config(config)print(type(model))预期输出:
<class 'transformers.models.bert.modeling_bert.BertModel'>AutoModel 读到的是 BERT 配置,所以会自动实例化匹配的 BERT 模型类。真实加载预训练 checkpoint 时,本质上也是类似的自动选择逻辑。
这说明:
AutoModel不一定非要联网下载- 它本质上是“根据配置自动实例化正确模型”
七、pipeline 到底值不值得学?
Section titled “七、pipeline 到底值不值得学?”值得,但你要知道它适合什么阶段
Section titled “值得,但你要知道它适合什么阶段”pipeline 的优点:
- 上手快
- 更快做出原型
- 少写样板代码
它更适合:
- 学习
- 快速验证
- 小实验
但工程里不能只靠它
Section titled “但工程里不能只靠它”因为真实项目往往还要控制:
- batch
- device
- 输出格式
- 日志
- 错误处理
所以真正成熟的做法通常是:
- 学会
pipeline - 但也要理解底层 tokenizer + model 调用链
八、Transformers 库最常见的任务头
Section titled “八、Transformers 库最常见的任务头”粗略记几个高频接口:
| 接口 | 适合什么 |
|---|---|
AutoModel | 只拿基础表示 |
AutoModelForSequenceClassification | 文本分类 |
AutoModelForTokenClassification | 序列标注 |
AutoModelForQuestionAnswering | 抽取式问答 |
AutoModelForCausalLM | 生成任务 |
这背后的逻辑其实很简单:
相同骨干模型 + 不同任务头。
九、初学者最常踩的坑
Section titled “九、初学者最常踩的坑”只会 pipeline,不会底层调用
Section titled “只会 pipeline,不会底层调用”这样一到工程场景就容易卡住。
不理解 tokenizer 输出字段
Section titled “不理解 tokenizer 输出字段”至少要看懂:
input_idsattention_mask
把“模型概念”和“库接口”混在一起
Section titled “把“模型概念”和“库接口”混在一起”你要能分清:
- BERT / GPT 是模型路线
AutoModel/pipeline是库接口
学完这一页,至少保留这张证据卡:
- 模型选择
- BERT、GPT、T5、Transformer 流水线或其他预训练基线
- tokenizer 输出
- id、mask、解码文本或批次形状
- 任务结果
- 分类、生成、抽取或文本到文本输出
- 失败检查
- 错误的模型家族、token 限制、领域不匹配、成本或延迟
- 期望产出
- 模型调用结果加一段简短的选择理由
这一节最重要的不是会不会背 API,而是搞清楚:
Transformers 库的核心调用链,就是 tokenizer 把文本编码成张量,model 对张量做前向计算,再由任务头或后处理得到结果。
一旦这条链清楚了,后面无论你做分类、抽取、生成还是微调,思路都会稳定很多。
- 修改本节的 mini vocab,加入你自己的几个词,再看 tokenizer 输出有什么变化。
- 把
BertConfig的hidden_size改成 64,看看输出 shape 怎么变。 - 用自己的话解释:为什么学
transformers库时,不能只会pipeline? - 想一想:如果你要做文本分类,应该优先找
AutoModel还是AutoModelForSequenceClassification?
参考实现与讲解
- 修改 mini vocab 后,token IDs 会变化;如果词表缺词,还可能出现 unknown token。
- 把
hidden_size改成 64 应改变 hidden representation 的维度,而不是 sequence length 或 batch size。 pipeline很方便,但真实项目调试还需要理解 tokenizer、config、model class、tensor、label 和 evaluation。- 做文本分类时,如果需要现成分类头,先用
AutoModelForSequenceClassification;如果要自己搭 head,再用AutoModel。