7.2.2 大模型发展史
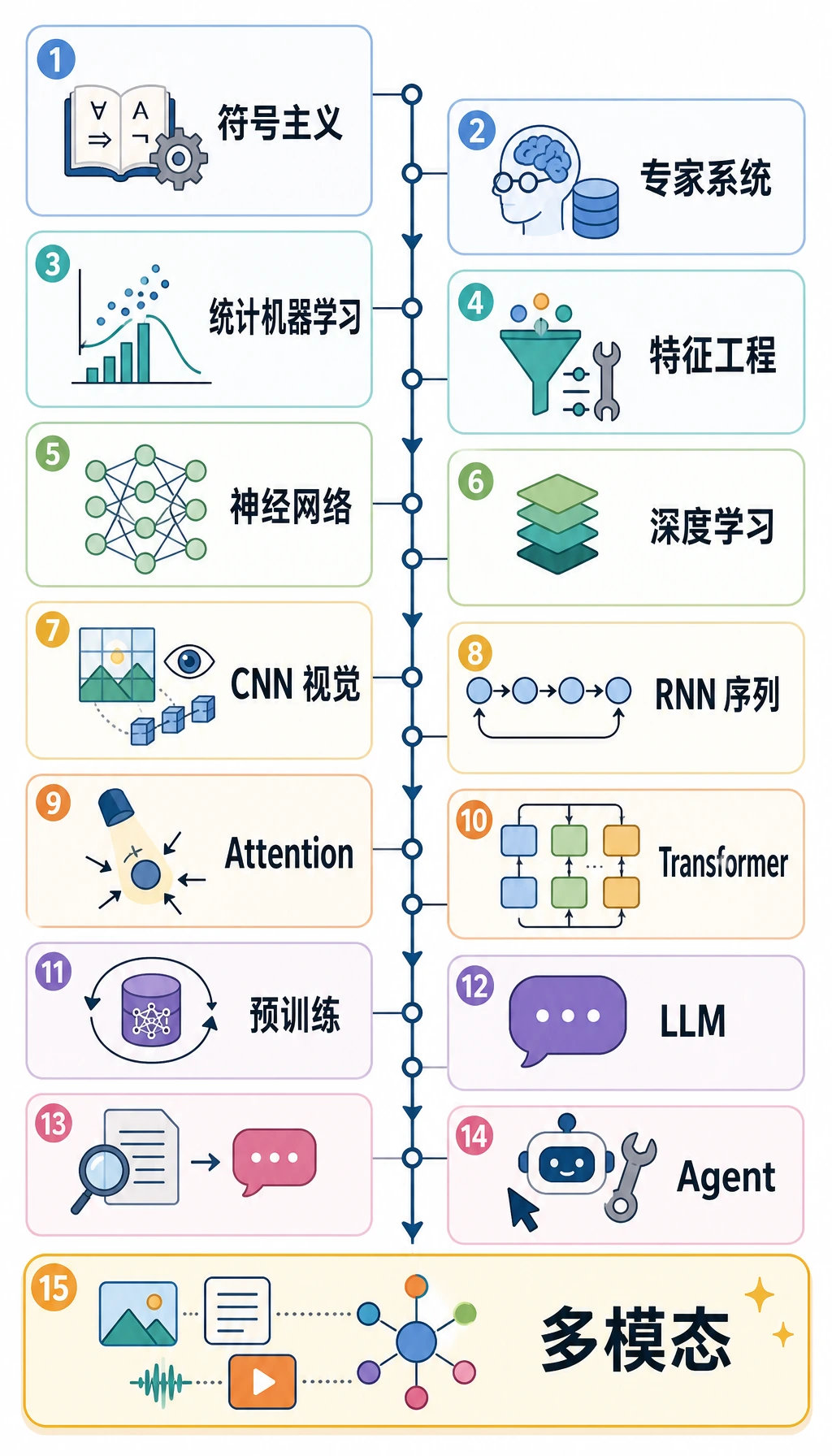
15 阶段全局图
Section titled “15 阶段全局图”| 阶段 | 发生了什么变化 | 和 LLM 的关系 |
|---|---|---|
| 1. 图灵问题 | 机器智能变成可讨论的问题 | 语言成为智能的重要测试 |
| 2. Dartmouth AI | AI 成为研究领域 | 早期以符号推理为主 |
| 3. 感知机 | 可训练神经模型出现 | 第一波学习型模型 |
| 4. 专家系统 | 规则在窄领域扩展 | 证明了价值,也暴露维护成本 |
| 5. 反向传播 | 多层神经网络可训练 | 深度学习基础 |
| 6. LeNet | 神经网络解决真实感知任务 | 表示学习开始落地 |
| 7. 统计机器学习 | 数据驱动方法超过大量手写规则 | NLP 转向语料证据 |
| 8. ImageNet / AlexNet | 深度学习在规模化任务上胜出 | 数据、算力、架构缺一不可 |
| 9. ResNet | 很深的网络更容易训练 | 规模化更可靠 |
| 10. RNN / LSTM | 序列进入神经网络时代 | 语言模型超越 n-gram |
| 11. Attention | 模型能关注相关位置 | 缓解长上下文瓶颈 |
| 12. Transformer | attention 成为主架构 | 并行训练和扩展起飞 |
| 13. BERT / GPT | 预训练成为共享基础 | 一个模型迁移到多种任务 |
| 14. RLHF / ChatGPT | 行为开始按指令对齐 | 能力变成产品体验 |
| 15. RAG / Agent | 模型能用知识和工具 | LLM 变成应用系统 |
接下来只看语言模型主线。
五个语言模型时代
Section titled “五个语言模型时代”| 时代 | 核心思想 | 主要限制 |
|---|---|---|
| 规则系统 | 人写语言规则 | 脆弱,维护贵 |
| 统计语言模型 | 根据频率预测下一个词 | 数据稀疏,上下文短 |
| 神经序列模型 | 学向量和循环状态 | 长依赖难,训练慢 |
| Transformer | token 之间直接 attention | 算力和数据成本高 |
| LLM + 对齐 | 大规模预训练后调行为 | 幻觉、安全、成本、评估问题 |
主线其实是上下文:每一代都在尝试用更多上下文,同时减少手写规则。
实验:写一个 Bigram 语言模型
Section titled “实验:写一个 Bigram 语言模型”这个小 n-gram 模型只根据当前词预测下一个词。它不强,但能看到神经语言模型之前的统计思想。
from collections import Counter, defaultdict
corpus = [ "I like learning AI", "I like learning Python", "You like learning NLP", "I like doing projects",]
next_word_counter = defaultdict(Counter)
for sentence in corpus: tokens = sentence.split() for current_word, next_word in zip(tokens[:-1], tokens[1:]): next_word_counter[current_word][next_word] += 1
def suggest_next(word): candidates = next_word_counter[word] return candidates.most_common() if candidates else []
print("Common words after I :", suggest_next("I"))print("Common words after like :", suggest_next("like"))print("Common words after learning:", suggest_next("learning"))预期输出:
Common words after I : [('like', 3)]Common words after like : [('learning', 3), ('doing', 1)]Common words after learning: [('AI', 1), ('Python', 1), ('NLP', 1)]
这已经有点像自动补全,但缺点也很明显:
- 只看前一个词;
- 稀有组合统计很弱;
- 没有真正的句子语义表示。
为什么神经模型重要
Section titled “为什么神经模型重要”神经语言模型把“数次数”换成了“学习表示”:
word idvectorcontext stateprediction
Word2Vec、GloVe、RNN、LSTM、GRU 让语言模型更灵活。它们能学习相似性和更长上下文,但按顺序读的方式让训练慢,长距离记忆也容易不稳定。
为什么 Transformer 是转折点
Section titled “为什么 Transformer 是转折点”RNN 主要一步一步读。Transformer 让 token 通过 attention 直接比较其他 token:
current tokenattends to relevant tokensupdated representation
这改变了三件事:
- 训练更容易并行;
- 长距离关系更容易建模;
- 参数、数据和算力规模化更有效。
所以 BERT、GPT、T5 和后来的 LLM 都属于 Transformer 家族树。
为什么只有规模还不够
Section titled “为什么只有规模还不够”大规模预训练带来了通用能力,但产品行为还需要另一层:
| 需求 | 技术 |
|---|---|
| 按指令回答 | instruction tuning |
| 更偏好有帮助的回答 | preference learning / RLHF |
| 使用最新或私有知识 | RAG |
| 执行动作 | tool calling / Agent loop |
| 降低不安全行为 | safety evaluation and guardrails |
现代大模型最关键的区别之一是:
model capability != model behavior模型可以很强,但仍然可能不按政策回答、不引用证据或不安全。
大模型属于 NLP 历史,但已经不止是狭义 NLP。相同架构和训练思想正在进入文本、图像、语音、代码、视频、多模态问答、RAG 和 Agent。
实用结论是:
- 规则给了控制,但覆盖差;
- 统计给了数据证据,但上下文短;
- 神经表示带来了语义空间;
- Transformer 让规模化变得可行;
- 对齐、RAG、工具调用把模型变成系统。
学完这一页,至少保留这张证据卡:
- 时间线
- n-gram → 神经 LM → Transformer → 规模化 → 指令/对齐
- 转折点
- Transformer 对上下文混合带来了什么变化
- 规模说明
- 数据和算力提升了能力,但并不能单独提升可靠性
- bigram 标签
- 一个输出样本及其局限性
- 记忆钩子
- 历史是一连串被解决的瓶颈
- 给 bigram 语料增加两句话,观察推荐词如何变化。
- 为什么 bigram 模型难以理解长指令?
- 解释为什么 Transformer 比 RNN 更容易并行训练。
- 举一个例子:模型有能力,但仍然需要对齐或 RAG。
- 从 15 个阶段里选一个,说明它今天还如何影响 LLM 应用。
解题思路与讲解
- 增加句子只会改变 bigram 模型中的局部转移计数。新增短语附近的推荐可能变好,但离开这些局部模式仍会失败。
- bigram 模型只能看很短的局部上下文。长指令需要跨很多 token 跟踪目标、约束和关系。
- Transformer 的 self-attention 在训练时可以并行处理不同位置,而 RNN 的状态依赖前一个时间步,更天然地串行。
- 模型可能会写流畅答案,但遇到私有文档仍需要 RAG;遇到安全边界、拒答和服从指令问题时仍需要 alignment。
- 例如 Transformer 阶段今天仍然重要,因为基于 attention 的上下文混合是大多数 LLM 架构的基础。