2.2.3 文件操作与序列化
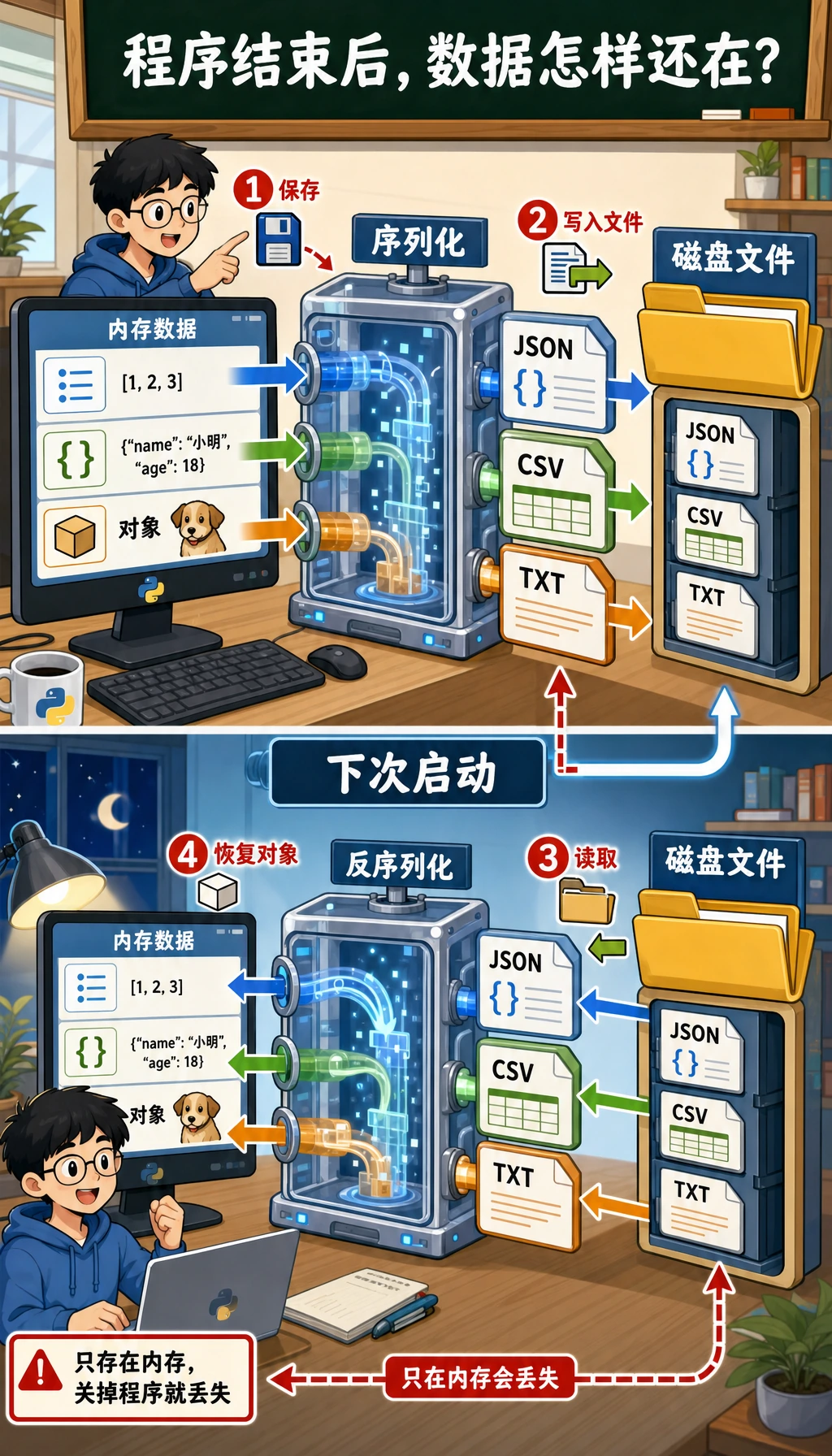
这一节让程序的数据可以保存下来、再读回来。文件读写、CSV、JSON 和序列化是数据集处理、训练日志、配置文件、模型结果保存的基础,也是从内存中的临时代码走向真实项目的关键一步。
- 掌握文件的读写操作(
open、read、write) - 理解
with语句的作用和好处 - 学会处理 CSV、JSON 等常用数据格式
- 理解序列化和反序列化的概念
为什么需要文件操作?
Section titled “为什么需要文件操作?”到目前为止,你的程序中的数据都在内存中——程序一关,数据就没了。但在真实场景中:
- 训练好的 AI 模型需要保存到文件,下次直接加载
- 数据集存在 CSV 文件里,需要读取到程序中
- 训练日志需要写入文件,方便后续分析
- 配置参数存在 JSON 文件里,启动时需要加载
文件操作就是让你的程序能持久化保存数据。
文件读写基础
Section titled “文件读写基础”打开文件:open()
Section titled “打开文件:open()”# 基本语法file = open("文件路径", "模式", encoding="编码")常用模式:
| 模式 | 含义 | 文件不存在时 |
|---|---|---|
"r" | 读取(默认) | 报错 |
"w" | 写入(覆盖) | 自动创建 |
"a" | 追加(在末尾添加) | 自动创建 |
"x" | 创建(文件已存在则报错) | 自动创建 |
"rb" | 读取二进制文件 | 报错 |
"wb" | 写入二进制文件 | 自动创建 |
# 方式 1:手动打开和关闭(不推荐)file = open("hello.txt", "w", encoding="utf-8")file.write("你好,世界!\n")file.write("我正在学习 Python 文件操作。\n")file.close() # 别忘了关闭文件!
# 方式 2:使用 with 语句(推荐!)with open("hello.txt", "w", encoding="utf-8") as file: file.write("你好,世界!\n") file.write("我正在学习 Python 文件操作。\n")# 离开 with 块时,文件自动关闭,不需要手动 close()# 读取全部内容with open("hello.txt", "r", encoding="utf-8") as file: content = file.read() print(content)
# 逐行读取with open("hello.txt", "r", encoding="utf-8") as file: for line in file: print(line.strip()) # strip() 去掉行尾的换行符
# 读取所有行到列表with open("hello.txt", "r", encoding="utf-8") as file: lines = file.readlines() print(lines) # ['你好,世界!\n', '我正在学习 Python 文件操作。\n']# "a" 模式:在文件末尾追加,不会覆盖原有内容with open("log.txt", "a", encoding="utf-8") as file: file.write("2026-02-09: 开始学习\n") file.write("2026-02-09: 完成第一章\n")lines = ["第一行\n", "第二行\n", "第三行\n"]
with open("output.txt", "w", encoding="utf-8") as file: file.writelines(lines) # 写入一个字符串列表
# 或者用 print 写入文件with open("output.txt", "w", encoding="utf-8") as file: print("第一行", file=file) # print 可以指定输出到文件 print("第二行", file=file) print("第三行", file=file)实际案例:处理不同文件格式
Section titled “实际案例:处理不同文件格式”CSV 文件
Section titled “CSV 文件”CSV(Comma-Separated Values)是最常见的数据文件格式:
import csv
# 写入 CSVtasks = [ ["功能", "负责人", "工时"], ["登录 API", "Mina", 8], ["RAG 演示", "Kai", 12], ["图表视图", "Noah", 5],]
with open("tasks.csv", "w", newline="", encoding="utf-8") as file: writer = csv.writer(file) writer.writerows(tasks)
# 读取 CSVwith open("tasks.csv", "r", encoding="utf-8") as file: reader = csv.reader(file) header = next(reader) # 读取表头 print(f"列名: {header}")
for row in reader: feature, owner, hours = row print(f"{feature}, 负责人: {owner}, 估算: {hours} 小时")
# 用字典方式读取(更方便)with open("tasks.csv", "r", encoding="utf-8") as file: reader = csv.DictReader(file) for row in reader: print(f"{row['功能']} 由 {row['负责人']} 负责")JSON 文件
Section titled “JSON 文件”JSON 是 Web 开发和 API 中最常用的数据格式:
import json
# 写入 JSONconfig = { "model": "ResNet-50", "learning_rate": 0.001, "epochs": 100, "batch_size": 32, "classes": ["猫", "狗", "鸟"], "use_gpu": True}
with open("config.json", "w", encoding="utf-8") as file: json.dump(config, file, ensure_ascii=False, indent=2)
# 读取 JSONwith open("config.json", "r", encoding="utf-8") as file: loaded_config = json.load(file)
print(f"模型: {loaded_config['model']}")print(f"学习率: {loaded_config['learning_rate']}")print(f"类别: {loaded_config['classes']}")生成的 config.json 文件内容:
{ "model": "ResNet-50", "learning_rate": 0.001, "epochs": 100, "batch_size": 32, "classes": ["猫", "狗", "鸟"], "use_gpu": true}文本日志文件
Section titled “文本日志文件”from datetime import datetime
def log(message, filename="app.log"): """写入日志""" timestamp = datetime.now().strftime("%Y-%m-%d %H:%M:%S") with open(filename, "a", encoding="utf-8") as file: file.write(f"[{timestamp}] {message}\n")
# 使用log("程序启动")log("加载数据集: train.csv")log("开始训练模型")log("训练完成,准确率: 92.5%")生成的日志文件:
[2026-02-09 14:30:01] 程序启动[2026-02-09 14:30:02] 加载数据集: train.csv[2026-02-09 14:30:03] 开始训练模型[2026-02-09 14:35:15] 训练完成,准确率: 92.5%路径处理:pathlib
Section titled “路径处理:pathlib”pathlib 是 Python 3 推荐的路径处理方式,比 os.path 更现代、更好用:
from pathlib import Path
# 创建路径对象data_dir = Path("data")train_file = data_dir / "train" / "data.csv" # 用 / 拼接路径!print(train_file) # data/train/data.csv
# 检查路径print(train_file.exists()) # 文件是否存在print(train_file.is_file()) # 是否是文件print(data_dir.is_dir()) # 是否是目录
# 获取文件信息path = Path("model.pth")print(path.name) # model.pth(文件名)print(path.stem) # model(不带扩展名)print(path.suffix) # .pth(扩展名)print(path.parent) # .(父目录)
# 创建目录Path("output/results").mkdir(parents=True, exist_ok=True)
# 列出目录中的文件for file in Path(".").glob("*.py"): print(file)
# 递归查找所有 CSV 文件for csv_file in Path("data").rglob("*.csv"): print(csv_file)
# 读写文件的便捷方法Path("note.txt").write_text("Hello!", encoding="utf-8")content = Path("note.txt").read_text(encoding="utf-8")print(content) # Hello!序列化:保存 Python 对象
Section titled “序列化:保存 Python 对象”什么是序列化?
Section titled “什么是序列化?”序列化就是把 Python 对象(列表、字典、类实例等)转换成可以保存到文件的格式。反序列化就是反过来,从文件恢复成 Python 对象。
根据要保存的内容选择格式:
| 需求 | 推荐格式 |
|---|---|
| 配置、API 响应、小型结构化数据 | 用 json 模块保存 JSON |
| 行列形式的数据,需要能用表格软件打开 | 用 csv 模块保存 CSV |
| 只在 Python 内部使用、来源完全可信的对象 | 用 pickle 模块保存 pickle |
这里最重要的取舍是安全性。JSON 和 CSV 可读、适合普通学习项目;pickle 很方便也很快,但它是二进制格式,而且不能加载来源不可信的文件。
pickle:保存任意 Python 对象
Section titled “pickle:保存任意 Python 对象”import pickle
# 保存 Python 对象data = { "hours": [2, 5, 1, 3], "features": ["登录 API", "RAG 演示", "图表视图", "部署脚本"], "metadata": {"module": "portfolio backend", "year": 2026}}
with open("data.pkl", "wb") as file: # 注意是 "wb"(二进制写入) pickle.dump(data, file)
# 加载 Python 对象with open("data.pkl", "rb") as file: # 注意是 "rb"(二进制读取) loaded_data = pickle.load(file)
print(loaded_data["features"]) # ['登录 API', 'RAG 演示', '图表视图', '部署脚本']综合案例:任务日志持久化系统
Section titled “综合案例:任务日志持久化系统”import jsonfrom pathlib import Path
class TaskLog: """任务工作日志,支持文件持久化"""
def __init__(self, filename="task_log.json"): self.filename = Path(filename) self.tasks = {} self.load() # 启动时加载数据
def load(self): """从文件加载数据""" if self.filename.exists(): with open(self.filename, "r", encoding="utf-8") as f: self.tasks = json.load(f) print(f"✅ 已加载 {len(self.tasks)} 个任务的数据") else: print("📝 创建新的任务日志")
def save(self): """保存数据到文件""" with open(self.filename, "w", encoding="utf-8") as f: json.dump(self.tasks, f, ensure_ascii=False, indent=2)
def add_work(self, task_name, stage, hours): """添加工作时长""" if task_name not in self.tasks: self.tasks[task_name] = {} self.tasks[task_name][stage] = hours self.save() print(f"✅ {task_name} 的 {stage} 工时({hours} 小时)已保存")
def get_report(self, task_name): """获取任务报告""" if task_name not in self.tasks: print(f"❌ 找不到任务: {task_name}") return
stages = self.tasks[task_name] print(f"\n{'='*30}") print(f" {task_name} 的工作报告") print(f"{'='*30}") for stage, hours in stages.items(): print(f" {stage}: {hours} 小时") total = sum(stages.values()) print(f"{'─'*30}") print(f" 总工时: {total:.1f}") print(f"{'='*30}")
def export_csv(self, filename="task_hours.csv"): """导出为 CSV""" import csv stages = set() for task_stages in self.tasks.values(): stages.update(task_stages.keys()) stages = sorted(stages)
with open(filename, "w", newline="", encoding="utf-8") as f: writer = csv.writer(f) writer.writerow(["任务"] + stages) for task_name, task_stages in self.tasks.items(): row = [task_name] + [task_stages.get(s, "") for s in stages] writer.writerow(row) print(f"✅ 已导出到 {filename}")
# 使用log = TaskLog()log.add_work("登录 API", "设计", 2)log.add_work("登录 API", "实现", 5)log.add_work("登录 API", "测试", 1)log.add_work("RAG 演示", "实现", 7)log.add_work("RAG 演示", "文档", 2)log.get_report("登录 API")log.export_csv()练习 1:文件统计工具
Section titled “练习 1:文件统计工具”from pathlib import Path
def file_stats(filename): """返回行数、字符数、单词数和最长行信息。""" path = Path(filename) lines = path.read_text(encoding="utf-8").splitlines() longest_index, longest_line = max( enumerate(lines, start=1), key=lambda item: len(item[1]), default=(0, ""), ) return { "lines": len(lines), "characters": sum(len(line) for line in lines), "words": sum(len(line.split()) for line in lines), "longest_line_number": longest_index, "longest_line": longest_line, }
Path("sample.txt").write_text("hello world\nthis is Python\n", encoding="utf-8")print(file_stats("sample.txt"))练习 2:日记本程序
Section titled “练习 2:日记本程序”写一个简单的日记本程序:
- 支持写入新日记(自动加上时间戳)
- 支持查看所有日记
- 日记保存在文本文件中,程序关闭后数据不丢失
练习 3:配置文件管理器
Section titled “练习 3:配置文件管理器”import jsonfrom pathlib import Path
DEFAULT_CONFIG = {"theme": "light", "language": "zh-Hans", "page_size": 20}
def load_config(filename="config.json"): """加载配置文件,如果不存在则创建默认配置。""" path = Path(filename) if not path.exists(): save_config(DEFAULT_CONFIG.copy(), filename) return json.loads(path.read_text(encoding="utf-8"))
def save_config(config, filename="config.json"): """保存配置到文件。""" Path(filename).write_text(json.dumps(config, indent=2), encoding="utf-8")
def update_config(key, value, filename="config.json"): """更新某个配置项。""" config = load_config(filename) config[key] = value save_config(config, filename) return config
print(update_config("theme", "dark"))参考实现与讲解
file_stats应统计行数、字符数、单词数和最长行信息。max()里的default=(0, "")很重要,因为它能避免空文件直接报错。- 日记本程序应把带时间戳的内容追加到文本文件中,再按顺序读回,并且保持一种人眼也能直接查看的简单格式。
- 配置管理器应加载 JSON,不存在时先创建默认配置,更新一个键后再以漂亮格式写回。使用
Path可以让路径处理更统一。
学完这一页,至少保留这张证据卡:
- 模式
- 类、异常、文件 IO、函数式流水线、生成器或类型提示
- 代码产物
- 最小可运行示例和一个真实使用场景
- 输出
- 打印的对象状态、捕获的错误、保存的文件、yield 的值,或类型检查备注
- 失败检查
- 隐藏变异、吞掉异常、文件路径问题、懒迭代器混淆或误导性标注
- 期望产出
- 带调试说明的小型高级 Python 示例
| 操作 | 代码 | 说明 |
|---|---|---|
| 写入文件 | with open("f.txt", "w") as f: | "w" 覆盖,"a" 追加 |
| 读取文件 | with open("f.txt", "r") as f: | .read()、.readlines() |
| JSON 写入 | json.dump(data, file) | 字典 → JSON 文件 |
| JSON 读取 | json.load(file) | JSON 文件 → 字典 |
| CSV 写入 | csv.writer(file).writerow() | 列表 → CSV 行 |
| CSV 读取 | csv.reader(file) | CSV 行 → 列表 |
| 路径处理 | Path("data") / "file.txt" | 推荐用 pathlib |