5.5.3 特征预处理
- 理解缺失值、异常值、缩放和编码分别解决什么问题
- 能判断不同模型是否需要标准化
- 知道 One-Hot、Ordinal Encoding、Target Encoding 的适用边界
- 建立避免数据泄漏的基本意识
先建立一张地图
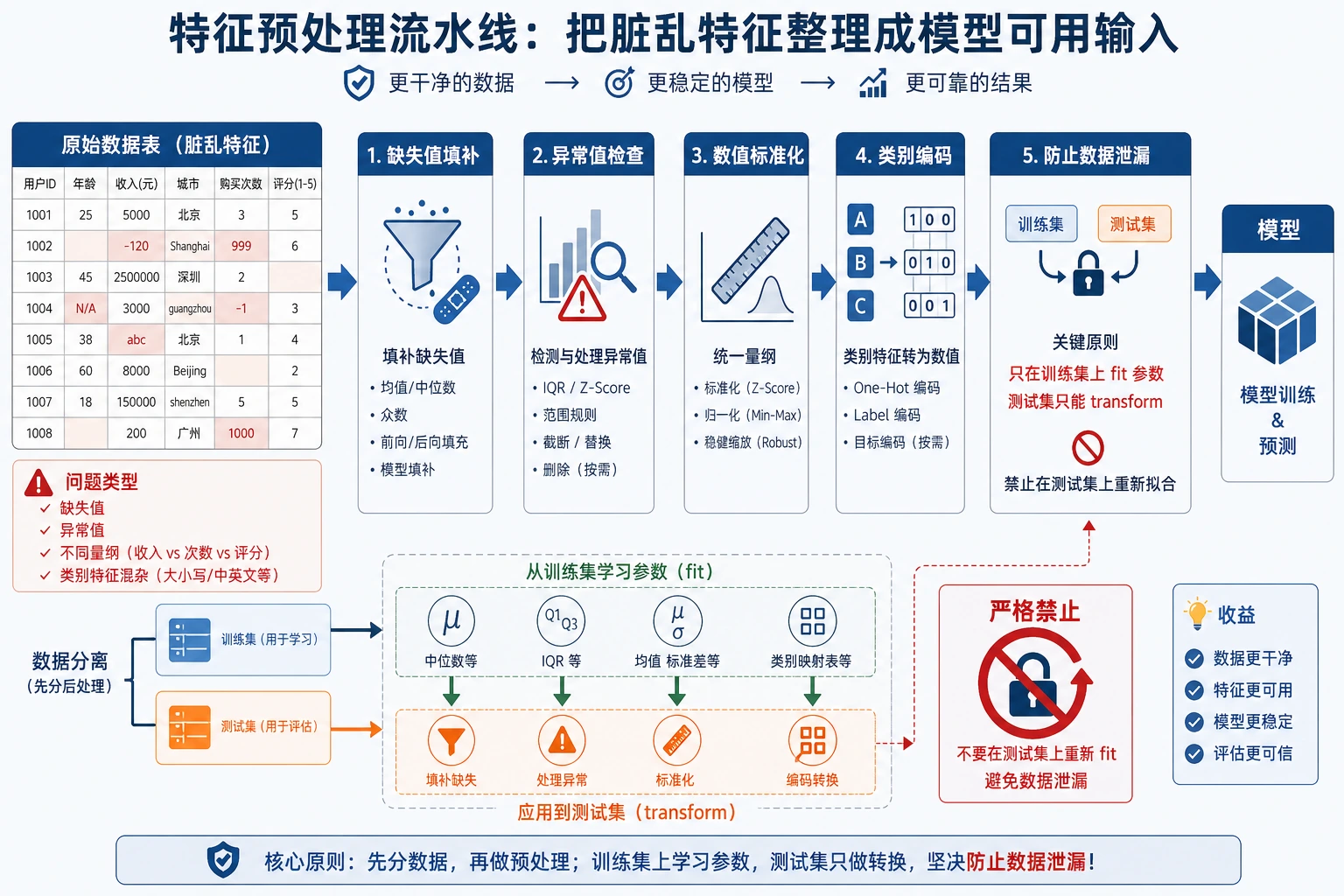
Section titled “先建立一张地图”flowchart LR A[原始特征] --> B[缺失值处理] B --> C[异常值处理] C --> D[数值缩放] D --> E[类别编码] E --> F[进入模型]这张图只是常见顺序,不是死流程。比如树模型通常不强依赖标准化,而线性模型、KNN、SVM、神经网络通常更需要缩放。
给下面示例准备一份可直接运行的数据
Section titled “给下面示例准备一份可直接运行的数据”为了让后面的代码块能单独运行,我们先准备一份很小的混合类型样本数据。它同时包含缺失值、数值列和类别列。
import numpy as npimport pandas as pdfrom sklearn.model_selection import train_test_split
df = pd.DataFrame({ "age": [25, np.nan, 39, 51, 45, np.nan, 33, 60], "income": [50000, 62000, np.nan, 120000, 85000, 76000, 54000, 200000], "amount": [80, 95, 120, 10000, 110, 130, 70, 150], "city": ["A", "B", "A", "C", None, "B", "D", "A"], "gender": ["F", "M", "F", "M", "F", None, "M", "F"], "target": [0, 1, 0, 1, 0, 1, 0, 1],})
X = df[["age", "income", "amount", "city", "gender"]]y = df["target"]X_train, X_test, y_train, y_test = train_test_split( X, y, test_size=0.25, random_state=42, stratify=y)一、缺失值处理
Section titled “一、缺失值处理”缺失值有时是脏数据,有时本身就是信号。比如“用户没有填写公司”可能代表普通个人用户;“体检指标缺失”可能只是系统录入问题。处理前要先问:为什么缺失。
import pandas as pd
missing_rate = df.isna().mean().sort_values(ascending=False)print(missing_rate)常见策略包括删除缺失很多的列、用均值或中位数填充数值特征、用众数或“未知”填充类别特征、增加一个是否缺失的标记列。不要一上来就全部 dropna(),否则很容易丢掉大量样本。
二、异常值处理
Section titled “二、异常值处理”异常值不一定都是错误。金融欺诈、设备故障、极端消费行为,本来就可能是模型最关心的样本。处理异常值时要结合业务含义。
q1 = df["amount"].quantile(0.25)q3 = df["amount"].quantile(0.75)iqr = q3 - q1lower = q1 - 1.5 * iqrupper = q3 + 1.5 * iqroutliers = df[(df["amount"] < lower) | (df["amount"] > upper)]print(outliers.head())如果异常来自录入错误,可以修正或删除;如果异常代表真实稀有行为,应考虑保留,并用稳健模型或分箱方式处理。
三、数值缩放:什么时候需要标准化
Section titled “三、数值缩放:什么时候需要标准化”标准化解决的是不同特征量纲差异过大的问题。例如年龄是几十,收入可能是几万,如果模型依赖距离或梯度,尺度差异会影响训练。
| 模型类型 | 是否通常需要缩放 | 原因 |
|---|---|---|
| 线性回归 / 逻辑回归 | 建议需要 | 梯度和正则项受尺度影响 |
| KNN / SVM | 通常需要 | 距离计算受尺度影响 |
| 神经网络 | 通常需要 | 有助于稳定训练 |
| 决策树 / 随机森林 / GBDT | 通常不需要 | 按阈值切分,对单调缩放不敏感 |
from sklearn.preprocessing import StandardScaler
numeric_cols = ["age", "income", "amount"]scaler = StandardScaler()X_train_scaled = scaler.fit_transform(X_train[numeric_cols])X_test_scaled = scaler.transform(X_test[numeric_cols])print(X_train_scaled[:2])注意只能在训练集上 fit,再对测试集 transform。如果你在全量数据上 fit scaler,就把测试集信息泄漏进训练过程了。
四、类别编码
Section titled “四、类别编码”类别特征不能直接喂给大多数传统模型,需要编码。最常见的是 One-Hot Encoding,它适合无序类别,例如城市、颜色、职业。
from sklearn.preprocessing import OneHotEncoder
encoder = OneHotEncoder(handle_unknown="ignore")X_train_cat = encoder.fit_transform(X_train[["city"]])X_test_cat = encoder.transform(X_test[["city"]])print(X_train_cat.shape, X_test_cat.shape)有序类别可以用 Ordinal Encoding,例如学历、小中大尺码。但不要把无序类别随便编码成 0、1、2,否则模型可能误以为类别之间有大小关系。
Target Encoding 对高基数类别有用,但非常容易泄漏。比如用“每个城市的平均转化率”编码城市时,必须只基于训练折计算,不能直接用全量标签。
五、用 Pipeline 防止泄漏
Section titled “五、用 Pipeline 防止泄漏”最稳的方式是把预处理和模型放进同一个 Pipeline,让交叉验证时每一折都只在训练部分 fit 预处理器。
from sklearn.compose import ColumnTransformerfrom sklearn.pipeline import Pipelinefrom sklearn.impute import SimpleImputerfrom sklearn.preprocessing import OneHotEncoder, StandardScalerfrom sklearn.linear_model import LogisticRegression
num_features = ["age", "income", "amount"]cat_features = ["city", "gender"]
preprocess = ColumnTransformer([ ("num", Pipeline([ ("imputer", SimpleImputer(strategy="median")), ("scaler", StandardScaler()), ]), num_features), ("cat", Pipeline([ ("imputer", SimpleImputer(strategy="most_frequent")), ("onehot", OneHotEncoder(handle_unknown="ignore")), ]), cat_features),])
model = Pipeline([ ("preprocess", preprocess), ("clf", LogisticRegression(max_iter=1000)),])
model.fit(X_train, y_train)print(model.score(X_test, y_test))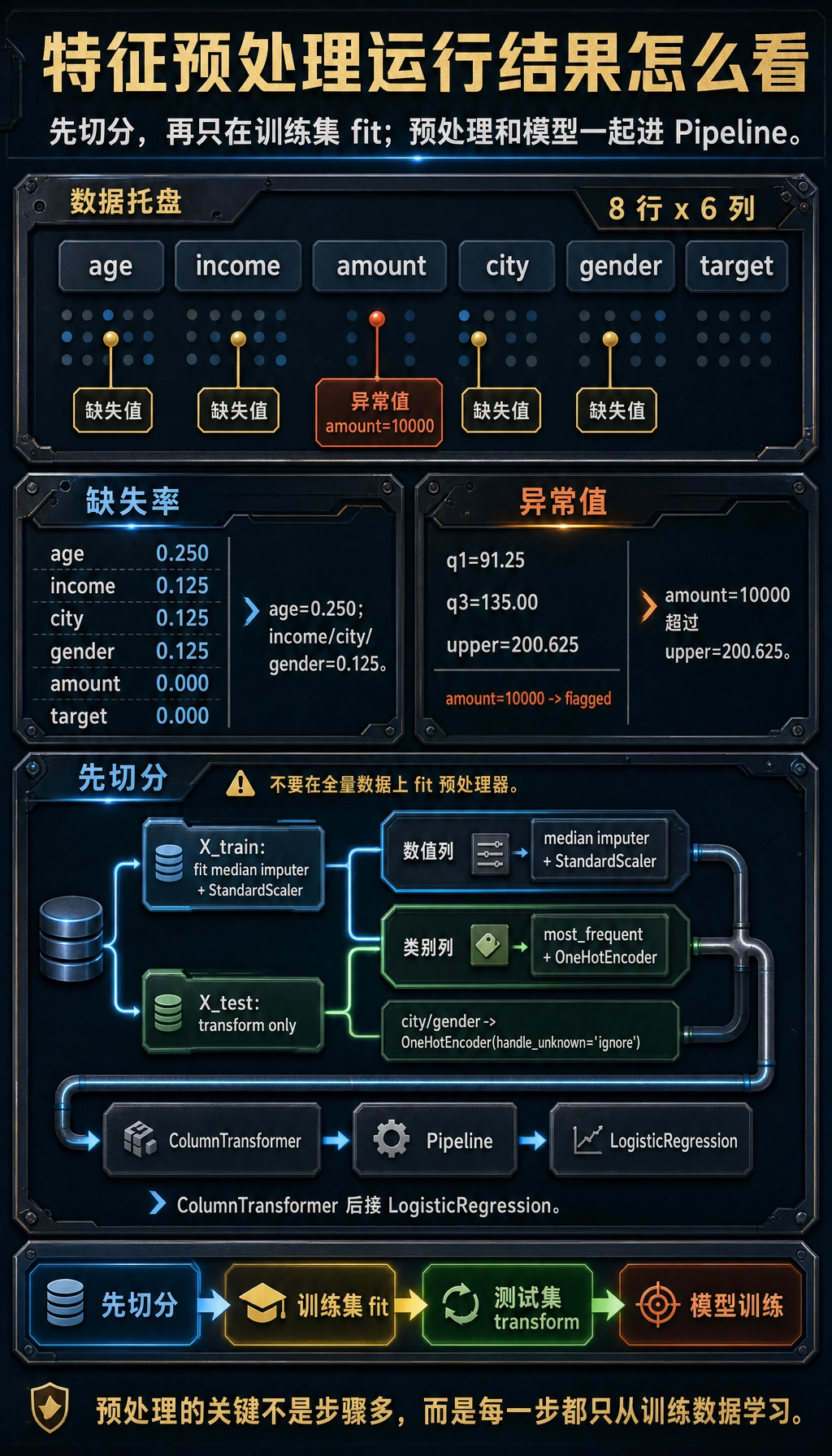
学完这一页,至少保留这张证据卡:
- 特征状态
- 原始列、类型、缺失值、尺度,以及与目标的关系
- 特征变换
- 预处理、构造、选择或流水线步骤
- 输出
- 转换后的特征表、pipeline 对象、分数变化,或选出的特征
- 失败检查
- 泄漏、训练/测试转换不一致、高基数陷阱或无意义特征
- 期望产出
- 带有前后对比和指标影响的特征流水线证据
第一个误区是所有模型都标准化。树模型通常不需要,做了也未必有收益。第二个误区是在切分训练集和测试集之前做预处理,这会造成数据泄漏。第三个误区是把类别随便映射成数字,导致模型学到不存在的大小关系。第四个误区是过度清理异常值,把真正有价值的极端样本删掉。
- 用 Titanic 数据集分别统计缺失率,并为每列设计处理方案。
- 对同一份数据分别训练 LogisticRegression 和 RandomForest,比较标准化对两者的影响。
- 解释为什么 scaler 应该
fit在训练集,而不是全量数据。 - 找一个高基数类别特征,思考 One-Hot 和 Target Encoding 各有什么风险。
解题思路与讲解
- 缺失率低的列通常可以用中位数/众数填补;缺失率高的列可能需要缺失指示器、领域复核或删除。处理方案应逐列说明理由。
- LogisticRegression 通常对尺度敏感,因为系数和优化过程受数值大小影响;RandomForest 对尺度不太敏感,因为树分裂主要依赖排序。
- scaler 只能从训练集学习均值和方差。若在全量数据上 fit,就把测试集分布信息泄漏进训练流程。
- One-Hot 面对高基数类别会产生大量稀疏列;Target Encoding 如果不放进交叉验证内部并做平滑,容易泄漏标签信息。
学完本节后,你应该能为一份表格数据写出预处理方案,能解释每一步处理的理由,能用 Pipeline 避免数据泄漏,并能判断某个模型是否真的需要标准化或类别编码。