9.9.3 运行时管理
- 理解并发、超时、重试、熔断分别在防什么
- 学会搭一个最小运行时管理器
- 理解为什么运行指标和模型指标一样重要
- 建立“系统稳定性优先于单次成功”的工程意识
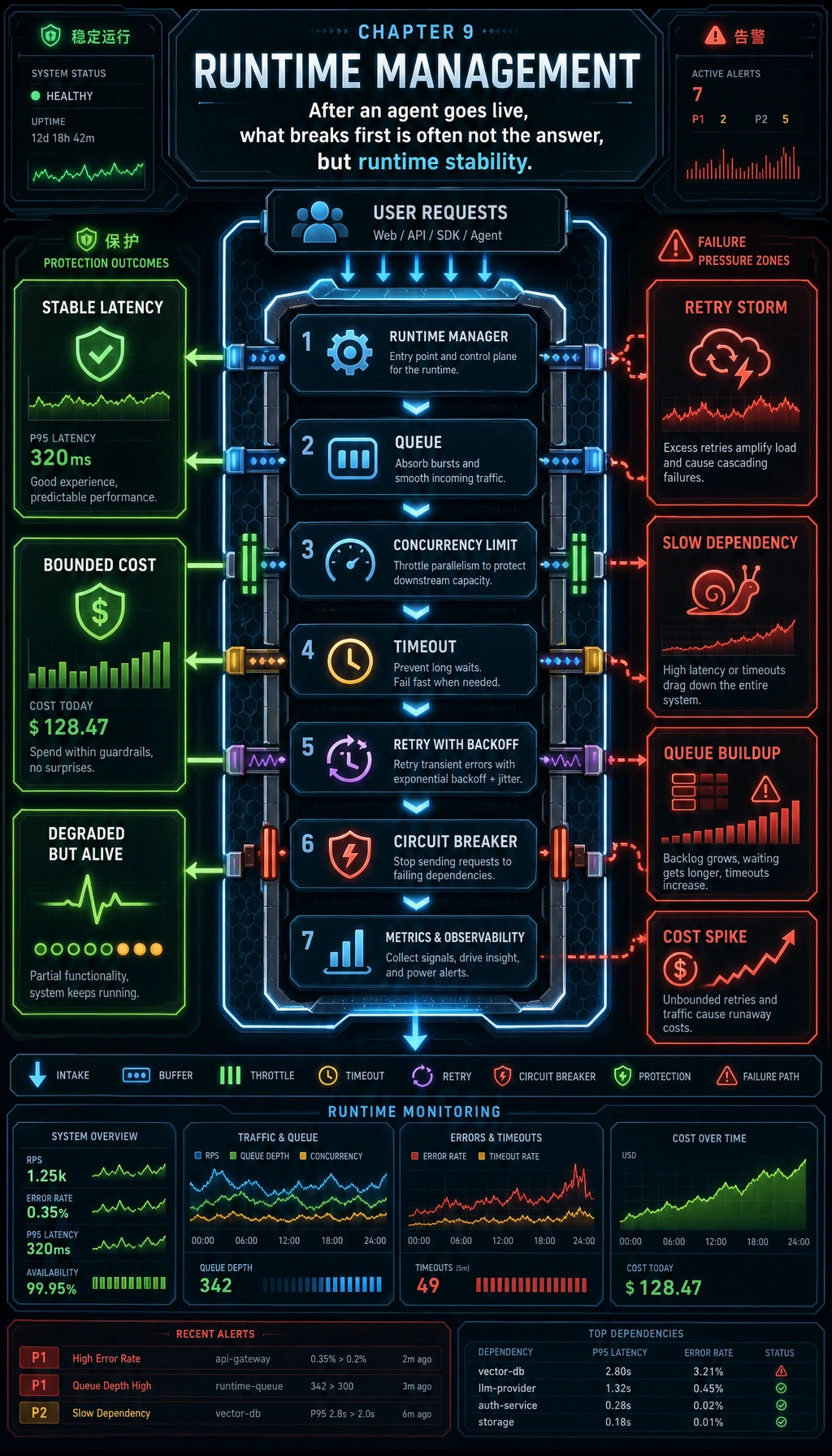
为什么 Agent 特别容易遇到运行时问题?
Section titled “为什么 Agent 特别容易遇到运行时问题?”一次请求往往不是一次调用
Section titled “一次请求往往不是一次调用”Agent 常见链路包括:
- 模型推理
- 工具调用
- 检索
- 再推理
这意味着一条用户请求可能包含多段子调用。 链路越长,运行时波动越容易被放大。
上线后最先暴露的往往不是“答错”,而是“跑不稳”
Section titled “上线后最先暴露的往往不是“答错”,而是“跑不稳””典型症状:
- 高并发时超时变多
- 上游暂时失败后重试风暴
- 请求排队过长
- 个别慢请求拖垮整体吞吐
所以运行时管理本质上是在保护系统可用性。
四个最关键的运行时机制
Section titled “四个最关键的运行时机制”限制同时执行的任务数,避免资源被瞬间打满。
为每个步骤设边界,防止请求无限挂起。
只对临时错误做有限重试,而不是所有错误都重来。
当某个依赖连续失败时,短期停止继续打它,避免把故障放大。
先跑一个最小运行时管理器
Section titled “先跑一个最小运行时管理器”import asyncio
class AgentRuntime: def __init__(self, max_concurrency=2, timeout_sec=0.8, max_retries=1, breaker_threshold=2): self.semaphore = asyncio.Semaphore(max_concurrency) self.timeout_sec = timeout_sec self.max_retries = max_retries self.breaker_threshold = breaker_threshold
self.breaker_open = False self.failure_streak = 0 self.metrics = { "total": 0, "success": 0, "timeout": 0, "error": 0, "retry": 0, "rejected_by_breaker": 0, "latency_ms_total": 0.0, }
async def _upstream_call(self, task): await asyncio.sleep(task["latency"]) if task.get("should_fail"): raise RuntimeError("upstream_error") return {"task_id": task["id"], "result": f"ok:{task['payload']}"}
async def handle(self, task): self.metrics["total"] += 1
if self.breaker_open: self.metrics["rejected_by_breaker"] += 1 return {"ok": False, "error": "circuit_open"}
last_error = None
for attempt in range(self.max_retries + 1): if attempt > 0: self.metrics["retry"] += 1
try: async with self.semaphore: result = await asyncio.wait_for( self._upstream_call(task), timeout=self.timeout_sec, )
latency_ms = task["latency"] * 1000 self.metrics["success"] += 1 self.metrics["latency_ms_total"] += latency_ms self.failure_streak = 0 return {"ok": True, "result": result, "attempts": attempt + 1}
except asyncio.TimeoutError: last_error = "timeout" if attempt == self.max_retries: self.metrics["timeout"] += 1 self.failure_streak += 1 break except Exception as e: last_error = str(e) if attempt == self.max_retries: self.metrics["error"] += 1 self.failure_streak += 1 break
if self.failure_streak >= self.breaker_threshold: self.breaker_open = True
return {"ok": False, "error": last_error}
def summary(self): avg_latency = ( self.metrics["latency_ms_total"] / self.metrics["success"] if self.metrics["success"] else 0.0 ) return {**self.metrics, "avg_latency_ms": round(avg_latency, 2)}
async def main(): runtime = AgentRuntime(max_concurrency=2, timeout_sec=0.7, max_retries=1, breaker_threshold=2)
tasks = [ {"id": "r1", "payload": "refund", "latency": 0.2}, {"id": "r2", "payload": "slow", "latency": 1.0}, {"id": "r3", "payload": "fail", "latency": 0.1, "should_fail": True}, {"id": "r4", "payload": "normal", "latency": 0.3}, {"id": "r5", "payload": "after_breaker", "latency": 0.1}, ]
results = [] for task in tasks: results.append(await runtime.handle(task))
print("results:") for item in results: print(item)
print("\nmetrics:") print(runtime.summary()) print("breaker_open:", runtime.breaker_open)
asyncio.run(main())预期输出:
results:{'ok': True, 'result': {'task_id': 'r1', 'result': 'ok:refund'}, 'attempts': 1}{'ok': False, 'error': 'timeout'}{'ok': False, 'error': 'upstream_error'}{'ok': False, 'error': 'circuit_open'}{'ok': False, 'error': 'circuit_open'}
metrics:{'total': 5, 'success': 1, 'timeout': 1, 'error': 1, 'retry': 2, 'rejected_by_breaker': 2, 'latency_ms_total': 200.0, 'avg_latency_ms': 200.0}breaker_open: True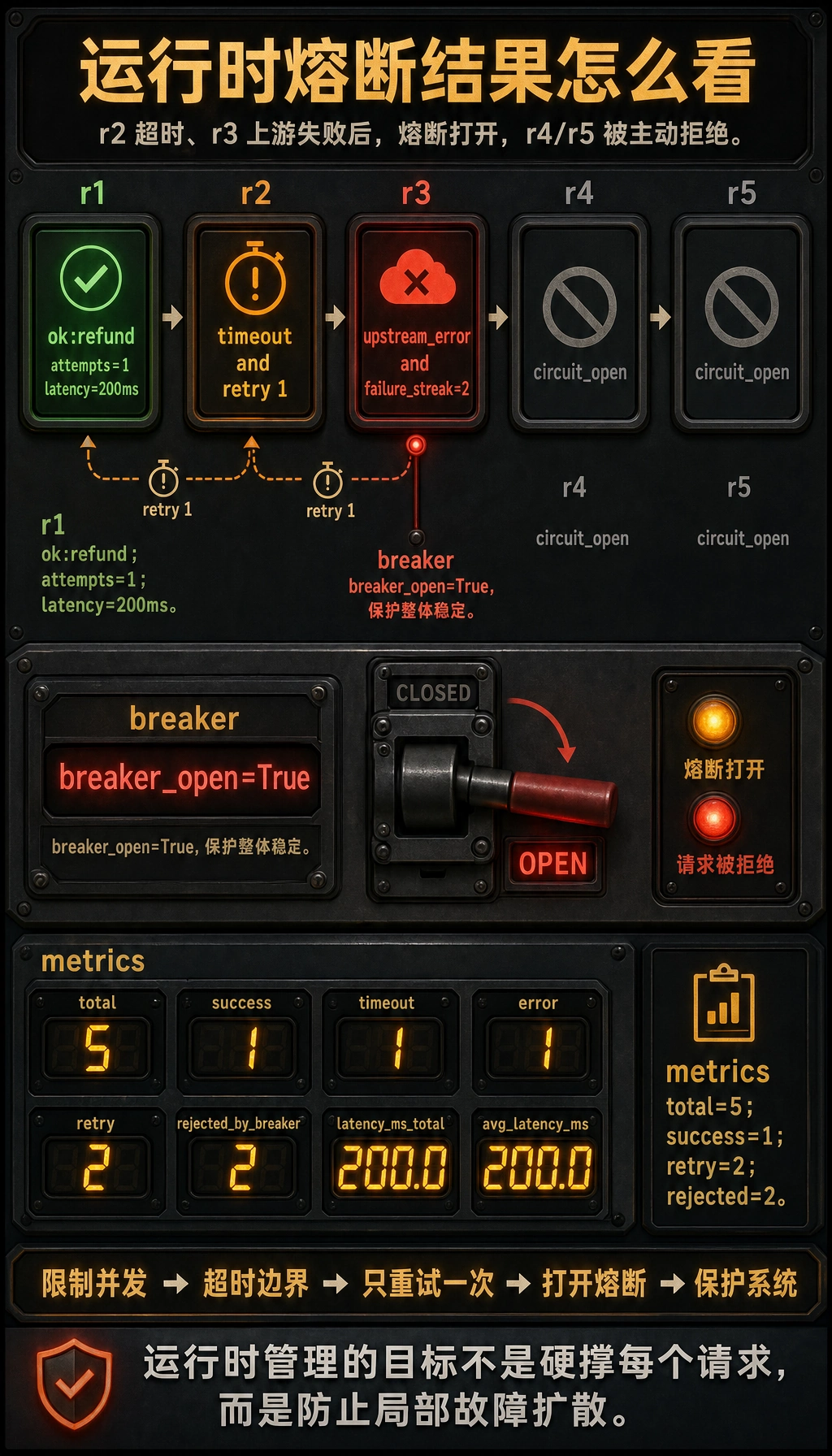
这段代码最该看哪几处?
Section titled “这段代码最该看哪几处?”Semaphore:并发限制wait_for:超时attempt > 0:重试计数breaker_open:熔断
为什么这已经很接近真实运行时问题?
Section titled “为什么这已经很接近真实运行时问题?”因为它覆盖了三类真实线上情况:
- 正常成功
- 慢请求超时
- 连续失败触发保护
运行时指标该怎么读?
Section titled “运行时指标该怎么读?”优先看这几项:
success / total:成功率timeout / total:超时率retry / total:重试比rejected_by_breaker:熔断拒绝量avg_latency_ms:平均成功延迟
如果超时率高,先查:
- 上游慢不慢
- 超时阈值是否太小
- 并发是否太高导致排队
如果重试比高,先查:
- 是不是在重试不可恢复错误
- 上游是否不稳定
运行时优化最常见的方向
Section titled “运行时优化最常见的方向”当系统接近满载时,要主动:
- 拒绝低优先级请求
- 或排队上限控制
例如:
- 关闭高成本工具链
- 切换到缓存结果
- 返回更轻量的安全答复
分依赖设置策略
Section titled “分依赖设置策略”不同工具不应共用完全相同的:
- 超时
- 重试
- 熔断阈值
因为它们稳定性和成本不同。
误区一:并发越高越好
Section titled “误区一:并发越高越好”并发太高可能直接把系统和上游一起压垮。
误区二:重试一定提升成功率
Section titled “误区二:重试一定提升成功率”错误分类不对时,重试只会放大故障。
误区三:只看平均延迟
Section titled “误区三:只看平均延迟”高分位延迟和超时率往往更能反映真实体验。
学完这一页,至少保留这张证据卡:
- 运行时
- 队列、worker、状态存储、工具服务,以及模型端点
- 持久化
- 检查点、事件日志、记忆存储和恢复路径
- 运维信号
- 延迟、成本、错误率、trace 覆盖率和饱和度
- 失败检查
- 运行卡住、重复动作、部分失败或成本失控
- 恢复动作
- 继续、回滚、取消、人工接管,或优雅降级
这节最重要的是建立一个部署视角:
Agent 运行时管理的核心,不是让每次请求“尽量试到成功”,而是用并发、超时、重试和熔断把系统整体稳定性保护住。
当这层补齐后,系统才算真正具备了上线基础。
- 把示例的
max_concurrency改成1和3,比较结果变化。 - 把
timeout_sec调大,观察超时率会怎么变。 - 为什么说“重试次数”不能脱离“错误类型”单独设计?
- 想一想:如果某个工具特别贵,你会在运行时层加什么保护?
参考实现与讲解
max_concurrency=1时运行更容易理解但更慢;max_concurrency=3会提升吞吐,但共享资源、rate limit 和 trace 顺序会变得更重要。- 增大
timeout_sec可以减少慢但健康调用的超时错误,但也可能让卡住的任务占用 runtime 更久。要同时看成功率和等待时间。 - retry 必须看错误类型:timeout 和临时 rate limit 可以重试;validation error 应先修参数;permission error 应停止或请求批准。
- 对昂贵 tool,应加 budget limit、concurrency limit、cache、pre-check、更便宜 fallback model/tool,以及花费或调用量异常时的告警。