10.5.1 高级视觉路线图:OCR、人脸、视频、3D
高级视觉不是模型名称集合,而是建立在同一视觉基础上的应用方向:输入更复杂、输出更复杂、约束和风险也更多。
这些高级任务为什么要分开学
Section titled “这些高级任务为什么要分开学”分类、检测、分割已经能处理很多图像问题,但真实视觉项目常常多出新的维度:文字、身份、时间和空间。高级视觉方向就是围绕这些新增维度拆出来的。
| 方向 | 从普通图像任务多了什么 | 为什么要单独处理 |
|---|---|---|
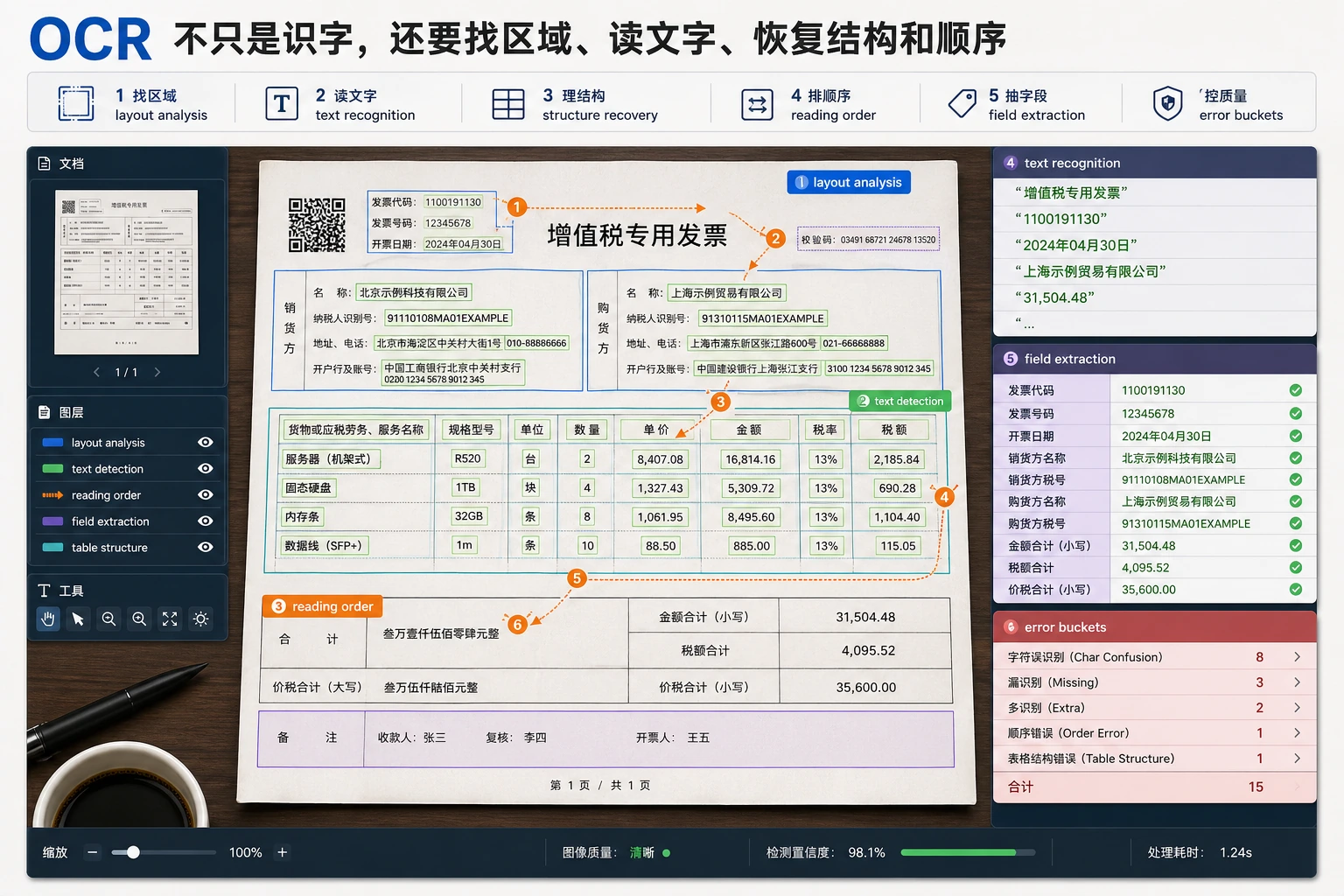
| OCR | 文字位置、字符序列、阅读顺序和版面结构 | 识别字只是一步,文档结构同样影响结果 |
| 人脸 | 身份、相似度阈值、隐私和误识风险 | 不只是检测脸,还涉及身份判断和合规 |
| 视频 | 时间、轨迹、事件过程 | 单帧正确不等于跨帧事件正确 |
| 3D | 深度、点云、多视角几何 | 平面图像缺少真实空间距离和结构 |
所以这章的学习重点是:先判断任务新增了哪一类信息,再选择对应流水线,而不是把所有问题都塞给一个视觉模型。
先看方向地图
Section titled “先看方向地图”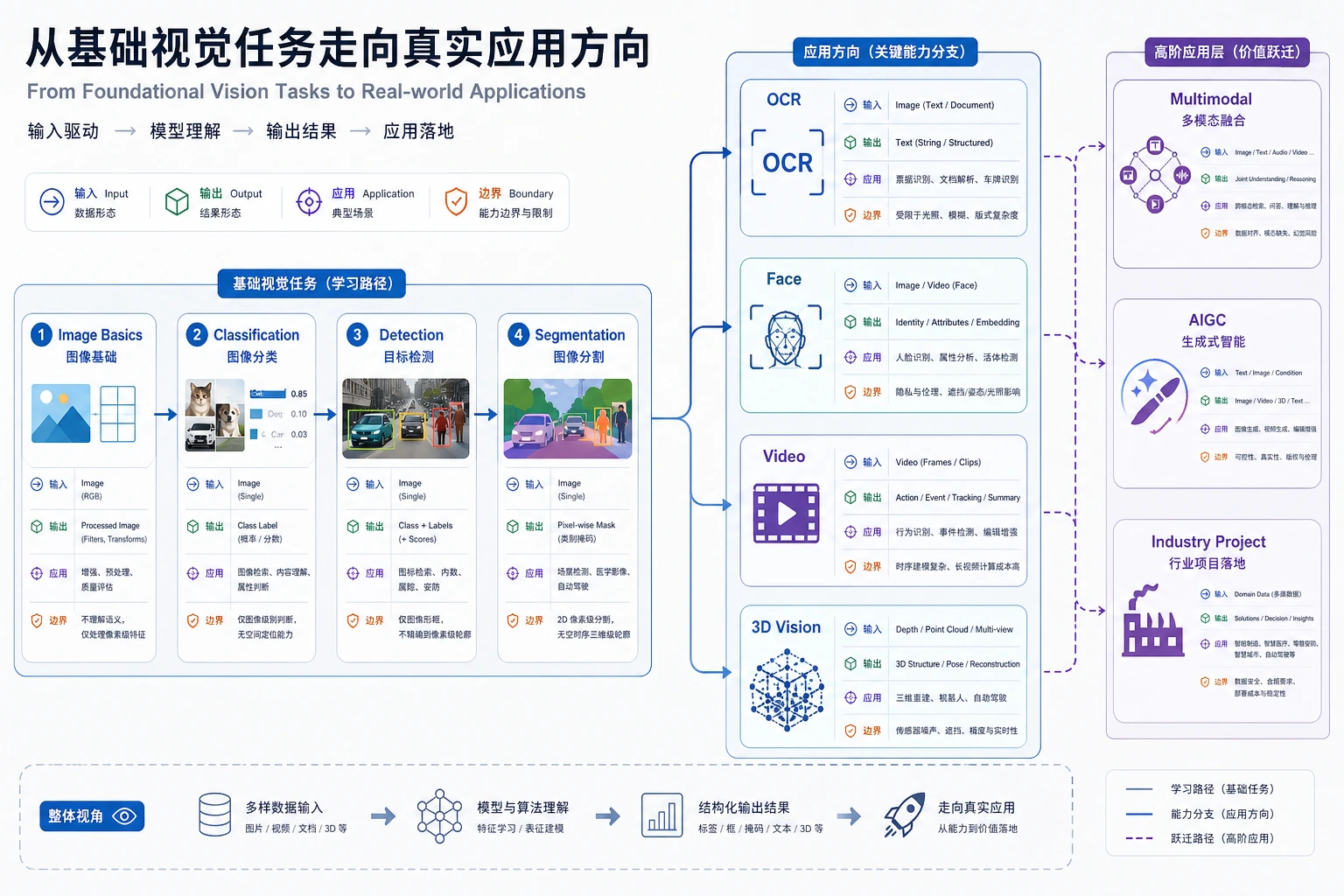
![]()
OCR 适合文档,人脸识别适合身份敏感场景,视频适合时间和运动,3D 视觉适合空间结构。
跑一个方向选择检查
Section titled “跑一个方向选择检查”选择一个方向深入,不要四个方向都浅尝辄止。
requirement = { "input": "screenshot", "needs_text": True, "needs_identity": False, "needs_time": False, "needs_depth": False,}
if requirement["needs_text"]: direction = "OCR"elif requirement["needs_identity"]: direction = "Face"elif requirement["needs_time"]: direction = "Video"elif requirement["needs_depth"]: direction = "3D"else: direction = "Classification or detection"
print("direction:", direction)print("first_output:", "text with layout")预期输出:
direction: OCRfirst_output: text with layout做人脸、监控、医疗或身份项目时,先写清隐私和使用边界,再展示结果。
按这个顺序学
Section titled “按这个顺序学”| 步骤 | 方向 | 实操产出 |
|---|---|---|
| 1 | OCR | 抽取文本、版面、字段、置信度和失败样例 |
| 2 | 人脸 | 检测人脸,解释阈值、隐私和偏见风险 |
| 3 | 视频 | 跨帧追踪事件并记录时间维度失败 |
| 4 | 3D 视觉 | 解释深度、点云、几何和传感器假设 |
如果你能选择一个方向,定义输入/输出,运行最小项目,并记录失败案例和使用边界,就通过了本章。
检查思路与讲解
- 合格答案要把任务映射到正确的视觉输出:类别标签、检测框、mask、OCR 文本、embedding 或视频事件。
- 证据应包含渲染后的视觉产物,以及一个指标或定性错误说明。
- 自检时要能指出一个视觉失败模式,例如类别混淆、漏检、mask 边界差、光照变化、领域偏移或标注质量弱。
学完这一页,至少保留这张证据卡:
- 场景边界
- 人脸、视频、OCR、3D、医疗,或其他视觉场景
- 输入样本
- 源图像/帧/文档以及期望的输出类型
- 结果工件
- 提取文本、跟踪事件、深度线索、诊断标记,或审查备注
- 失败检查
- 隐私、光照、时间漂移、布局、标定或领域风险
- 期望产出
- 带指标或人工复查说明的场景特定产物