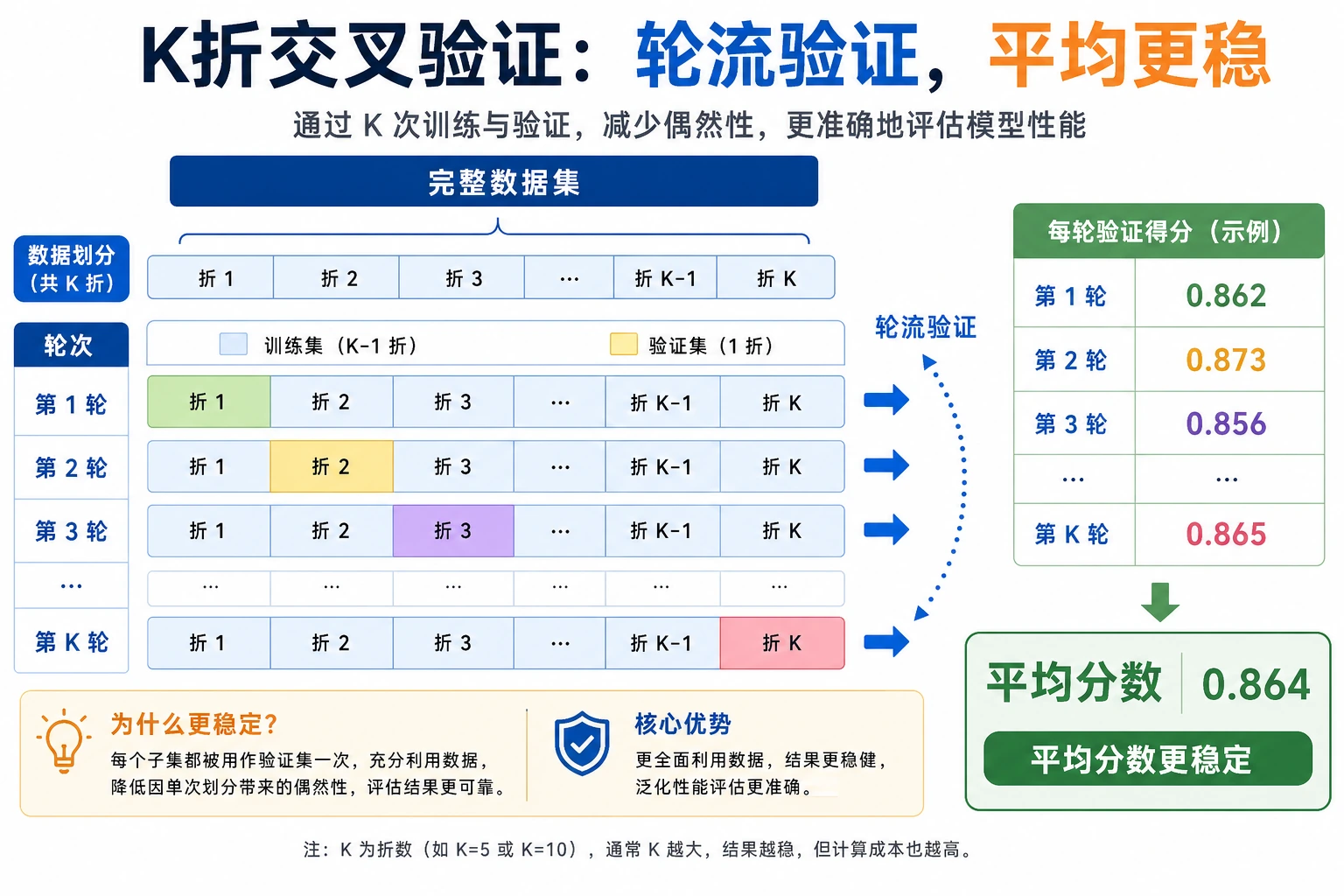
5.4.3 交叉验证
你会做出什么
Section titled “你会做出什么”本节会演示:
- 为什么单次 train-test 切分会有噪声;
- 分类任务如何使用
StratifiedKFold; - 如何用
cross_validate同时评估多个指标; - 为什么预处理必须放进
Pipeline; - 什么时候随机 K-Fold 是错的,尤其是时间序列。
python -m pip install -U scikit-learn numpy运行完整实验
Section titled “运行完整实验”新建 cv_lab.py:
import numpy as npfrom sklearn.datasets import load_breast_cancerfrom sklearn.linear_model import LogisticRegressionfrom sklearn.metrics import accuracy_scorefrom sklearn.model_selection import StratifiedKFold, cross_validate, train_test_splitfrom sklearn.pipeline import Pipelinefrom sklearn.preprocessing import StandardScaler
X, y = load_breast_cancer(return_X_y=True)
print("single_split_variance")for seed in [1, 2, 3, 4, 5]: X_train, X_test, y_train, y_test = train_test_split( X, y, test_size=0.25, random_state=seed, stratify=y ) model = Pipeline([ ("scale", StandardScaler()), ("clf", LogisticRegression(max_iter=2000, random_state=42)), ]) model.fit(X_train, y_train) print(f"seed={seed} accuracy={accuracy_score(y_test, model.predict(X_test)):.3f}")
print("cross_validation_lab")cv = StratifiedKFold(n_splits=5, shuffle=True, random_state=42)model = Pipeline([ ("scale", StandardScaler()), ("clf", LogisticRegression(max_iter=2000, random_state=42)),])result = cross_validate( model, X, y, cv=cv, scoring=["accuracy", "precision", "recall", "f1"],)for i, score in enumerate(result["test_accuracy"], start=1): print(f"fold={i} accuracy={score:.3f}")print( "summary " f"accuracy={np.mean(result['test_accuracy']):.3f}+/-{np.std(result['test_accuracy']):.3f} " f"precision={np.mean(result['test_precision']):.3f} " f"recall={np.mean(result['test_recall']):.3f} " f"f1={np.mean(result['test_f1']):.3f}")运行:
python cv_lab.py预期输出:
single_split_varianceseed=1 accuracy=0.965seed=2 accuracy=0.972seed=3 accuracy=0.986seed=4 accuracy=0.972seed=5 accuracy=0.979cross_validation_labfold=1 accuracy=0.974fold=2 accuracy=0.947fold=3 accuracy=0.965fold=4 accuracy=0.991fold=5 accuracy=0.991summary accuracy=0.974+/-0.017 precision=0.968 recall=0.992 f1=0.979
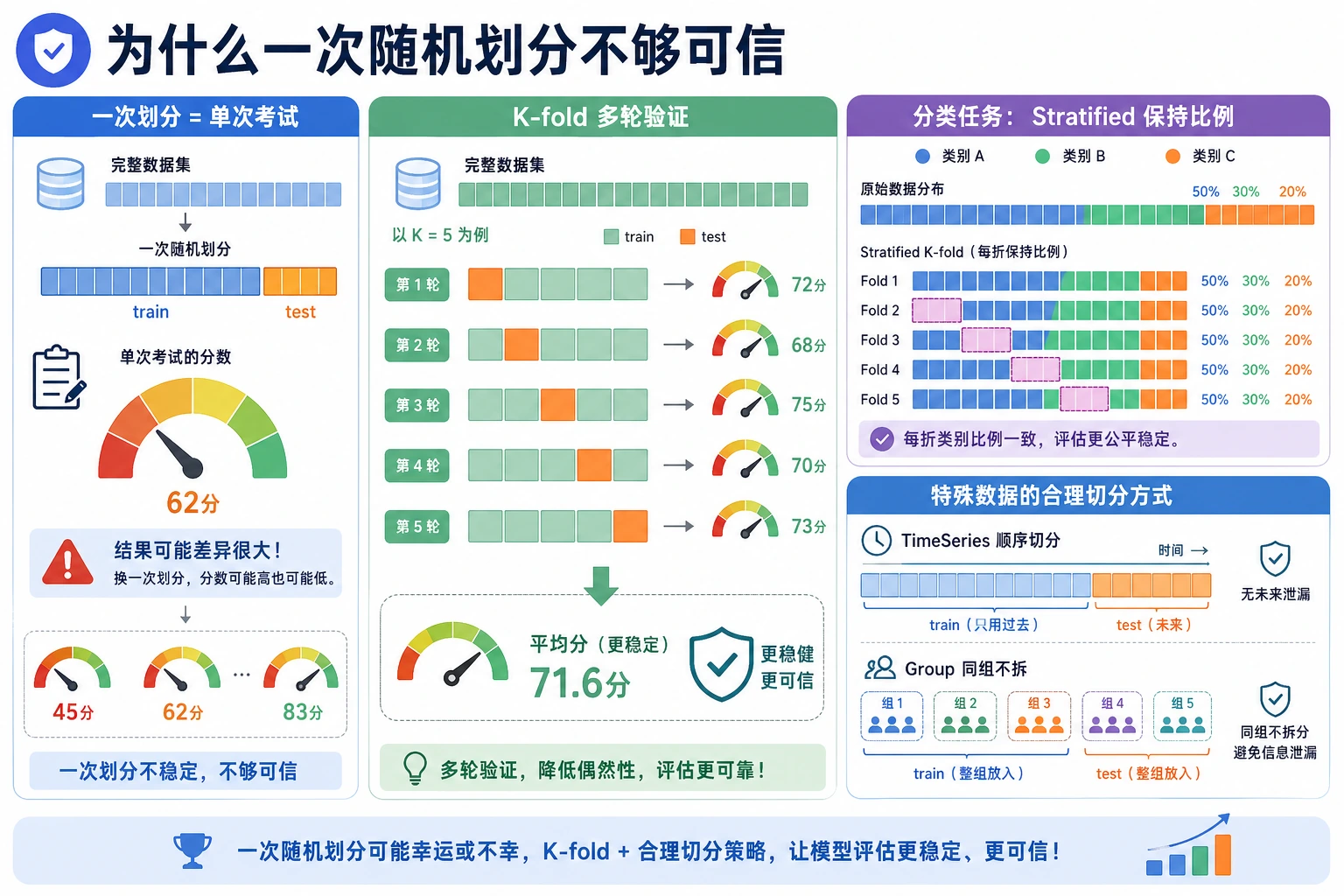
为什么一次切分不够
Section titled “为什么一次切分不够”同一个模型在不同随机切分下分数不同:
seed=1 accuracy=0.965seed=3 accuracy=0.986这两个数字都不是假的,只是不同快照。交叉验证真正想问的是:在多个快照上,平均表现是多少,波动有多大?
Stratified K-Fold
Section titled “Stratified K-Fold”分类任务优先使用 StratifiedKFold。它会尽量保持每个 fold 的类别比例接近整体数据,尤其适合不平衡分类。
cv = StratifiedKFold(n_splits=5, shuffle=True, random_state=42)K=5 是实用默认值:
- 比单次切分稳定;
- 比 10 折在大数据上更省;
- 容易向团队解释。
使用防泄漏 Pipeline
Section titled “使用防泄漏 Pipeline”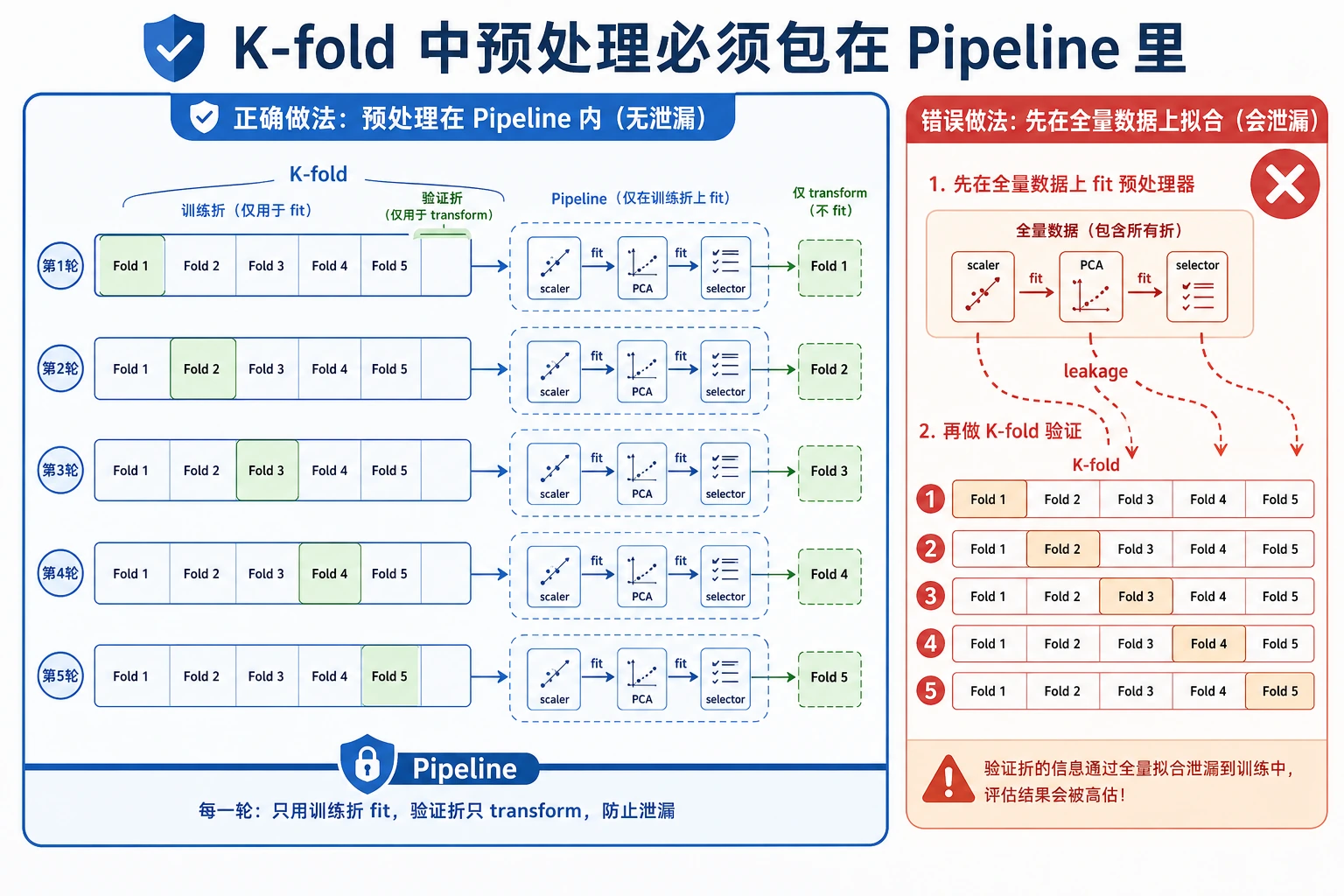
安全模式是:
Pipeline([ ("scale", StandardScaler()), ("clf", LogisticRegression(max_iter=2000, random_state=42)),])交叉验证时,每个 fold 的 scaler 只能在该 fold 的训练部分上 fit。如果先对全量数据缩放再做 CV,验证 fold 的信息就泄漏进训练了。
读平均值和波动
Section titled “读平均值和波动”summary 比单个 fold 更有用:
summary accuracy=0.974+/-0.017 precision=0.968 recall=0.992 f1=0.979可以这样读:
- 平均 accuracy 约为
0.974; - fold 之间波动约为
0.017; - recall 很高,如果漏掉正类代价高,这一点很重要。
如果标准差很大,可能说明模型不稳定、数据太少,或某些 fold 特别难。
什么时候 K-Fold 是错的
Section titled “什么时候 K-Fold 是错的”下面这些情况不要随机 shuffle:
- 时间序列数据;
- 同一个用户、会话、设备的多行数据可能同时出现在训练和验证;
- 样本按患者、客户、文档或实验分组;
- 未来信息会泄漏到过去。
要使用符合真实部署的数据切分:TimeSeriesSplit、group split,或按时间保留最后一段作为 holdout。
实用选择指南
Section titled “实用选择指南”| 情况 | 使用 |
|---|---|
| 基础分类 | StratifiedKFold(n_splits=5, shuffle=True) |
| 回归 | KFold(n_splits=5, shuffle=True) |
| 时间序列 | TimeSeriesSplit 或按时间验证 |
| 同一实体出现多次 | group-aware splitting |
| 超参数调优 | nested CV 或最终 untouched test set |
给有经验的读者:模型选择结束后,保留一个没有参与调参的最终 holdout 或接近生产的 backtest。
学完这一页,至少保留这张证据卡:
- 评估设置
- 划分、交叉验证、指标、基线和对比目标
- 结果
- 分数表、曲线、混淆矩阵、验证结果,或搜索结果
- 决策
- 是否更改数据、特征、模型、阈值或超参数
- 失败检查
- 泄漏、验证不稳定、指标错误或在测试集上调参
- 期望产出
- 支持下一步建模决策的评估记录
常见排查清单
Section titled “常见排查清单”| 现象 | 可能原因 | 修复方式 |
|---|---|---|
| CV 分数远高于测试分数 | 泄漏或过度调参 | 把预处理放进 pipeline;保留最终 holdout |
| fold 分数波动很大 | 数据少或存在困难分群 | 检查 fold 构成和分群指标 |
| 某个分类 fold 没有正类 | 没有 stratify | 使用 StratifiedKFold |
| 时间序列模型好得不正常 | 未来数据泄漏 | 按时间验证 |
| CV 太慢 | fold 太多或模型太重 | 先减少 fold 或使用更快基线 |
- 把
n_splits改成3和10。均值和标准差怎么变? - 去掉单次切分里的
stratify=y。分数是否更不稳定? - 在 scoring 列表里加入
roc_auc。 - 故意把
StandardScaler()移到 pipeline 外面,然后解释为什么不安全。 - 为“每个用户有多行事件”的数据设计验证切分。
参考实现与讲解
- 折数少时,每次训练数据更少,估计可能更粗;折数多时训练数据更多但成本更高。要同时看平均分和标准差。
- 去掉 stratify 后,训练/测试里的类别比例可能漂移,尤其在类别不均衡时更明显,分数通常更不稳定。
roc_auc增加了排序视角,适合阈值还没定时使用;但在不均衡任务中仍应配合 precision/recall 一起看。- 把缩放放在 pipeline 外面,会让验证折的信息影响 scaler,验证数据就不再真正未见,这是数据泄漏。
- 用户事件数据应避免同一用户的多行同时出现在训练和验证中。可用按用户分组的 split;如果预测未来行为,还应考虑按时间验证。
你能解释下面几点,就完成本节:
- 单次 train-test 切分只是一个快照;
- K-Fold 估计平均表现和波动;
- 分类任务通常应使用 stratified folds;
- 预处理必须放进 pipeline;
- 验证策略必须匹配真实部署的数据流。