13.1 计算路线:本地 CPU、免费 Colab、租 GPU
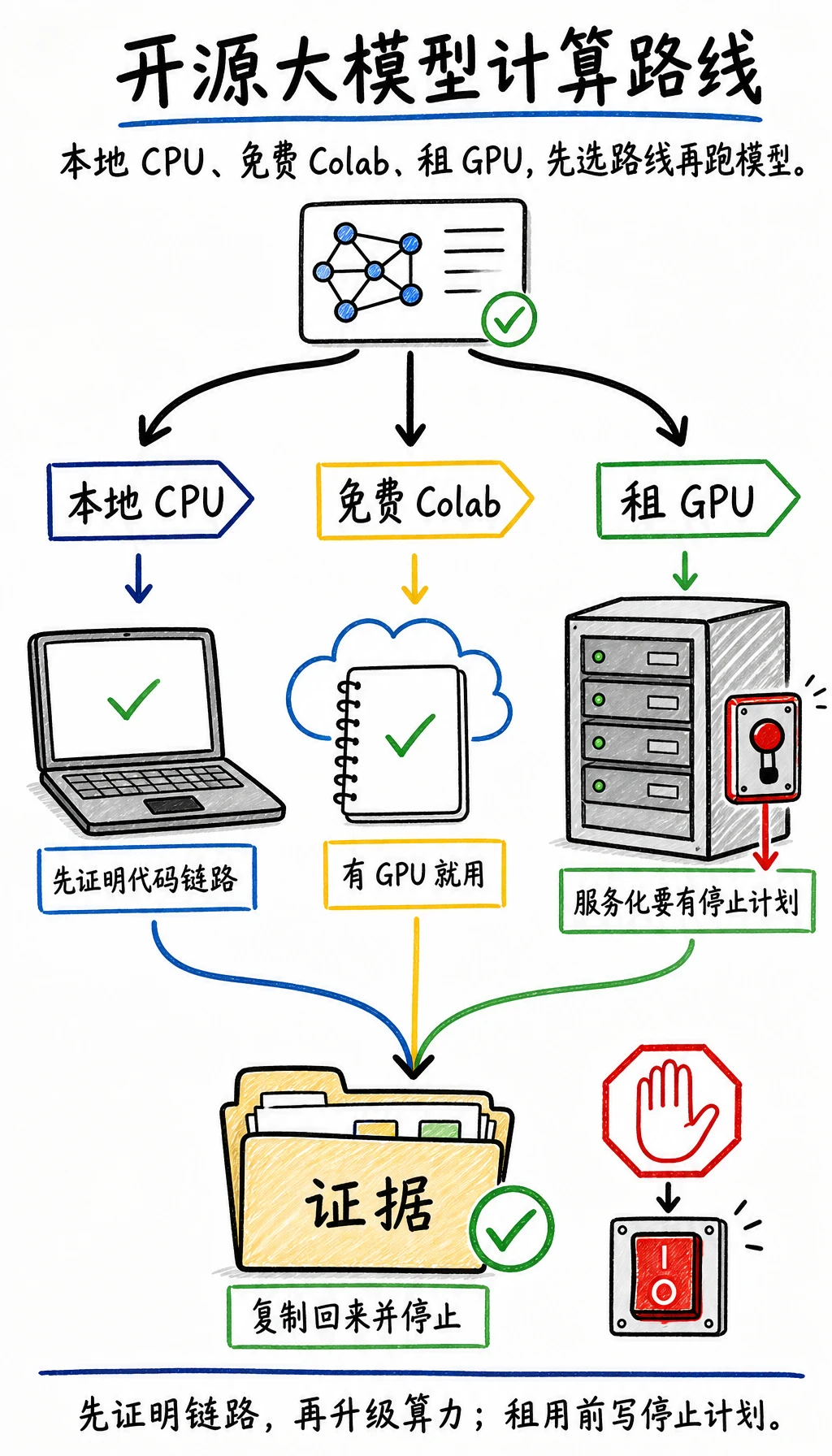
在选择模型名字前,先选择实验在哪里跑。好的计算路线会告诉你今天能证明什么、什么应该暂缓、要留下什么证据,以及怎样在成本或复杂度失控前停下来。
这一页给出三条路线:
- 本地 CPU:最安全的第一轮,不租机器,先证明代码和证据链。
- 免费 Colab:免费 GPU 可用时很有帮助,但不能保证一直有。
- 租 GPU:适合 vLLM 服务化或 7B 级模型测试,但必须先写预算、安全和关机计划。
本地 CPU
- 适合
- 想在自己的机器上安全跑通第一轮。
- 第一目标
sshleifer/tiny-gpt2、量化小模型、评估脚本、本地 API 骨架。- 不适合
- 证明 7B 质量、高吞吐、长上下文服务。
- 留下证据
environment_report.txt、first_run.md、eval_results.csv。
免费 Colab
- 适合
- 需要临时 Notebook,且可能拿到 GPU。
- 第一目标
- 小型 instruct 模型、tokenizer 检查、短评估、小型 LoRA 预演。
- 不适合
- 私密数据、长任务、公开服务、保证 GPU 的计划。
- 留下证据
- Notebook 副本、runtime 类型、
nvidia-smi或 CPU 记录、保存输出。
租 GPU
- 适合
- 需要稳定显存、SSH、服务化或 7B 级测试。
- 第一目标
- vLLM/SGLang 服务、固定评估集、延迟和显存检查。
- 不适合
- 没预算就开始、公开暴露端口、评估前先训练。
- 留下证据
gpu_plan.md、environment_report.txt、请求/响应日志、关机证明。
Colab 是很好的学习路线,但要把它当成“有机会就用”的资源。Google Colab FAQ 说明:Colab 可以免费提供包含 GPU/TPU 在内的计算资源,但资源不保证、不是无限的,使用限制也会波动。你的计划应该保证即使拿不到免费 GPU,也能先在 CPU 上跑通实验闭环。
先做最小证明
Section titled “先做最小证明”根据你要回答的问题选择路线:
| 问题 | 路线 |
|---|---|
| “我的 Python 环境能加载模型并生成文本吗?” | 本地 CPU |
| “同一套代码能在临时托管 Notebook 里跑吗?” | 免费 Colab |
| “这个模型能在明确显存、延迟和关机流程下服务化吗?” | 租 GPU |
| “我该不该微调?” | 先不选算力;先跑固定评估集 |
第一个有价值的证明不是一句漂亮回答,而是一条可复现轨迹:环境 -> 模型 -> Prompt -> 输出 -> 评估 -> 停止。
写 compute_route.md
Section titled “写 compute_route.md”运行命令前,先写这个文件:
# Compute Route
goal: prove the open-source LLM deployment loop for one small projectroute: local_cpu / free_colab / rented_gpuselected_model:runtime:expected_runtime_limit:privacy_level:budget_limit:stop_time:fallback_route:
## Why this route
## What this route can prove
## What this route cannot prove yet
## Evidence to copy back
## Stop or rollback step如果 stop_time、fallback_route 或 evidence to copy back 为空,先不要租 GPU。
路线 A:本地 CPU
Section titled “路线 A:本地 CPU”先用这条路线。默认 tiny 模型足够你完成 13.2 实操:跑通并服务化一个开源大模型 的大部分流程。
mkdir openllm_labcd openllm_lab
python -m venv .venvsource .venv/bin/activatepython -m pip install -U pippython -m pip install "torch" "transformers>=4.41" "accelerate" "safetensors" "sentencepiece" "fastapi" "uvicorn"然后用默认烟雾测试模型运行实验:
python environment_report.pypython run_local_llm.pypython eval_openllm.pyuvicorn serve_openai_like:app --host 127.0.0.1 --port 8000用 Ctrl+C 停止服务。通过标准不是回答质量,而是环境、推理、评估、API 和停止路径都能工作。
当你需要快速改代码时,用本地 CPU。模型质量判断留给更合适的模型和固定评估集。
路线 B:免费 Colab
Section titled “路线 B:免费 Colab”当你需要托管 Notebook,并且可能拿到 GPU 时,用这条路线。不要假设 GPU 总会分配给你。
在 Notebook 里运行:
!python -V!nvidia-smi || true!python -m pip install -U pip!python -m pip install "torch" "transformers>=4.41" "accelerate" "safetensors" "sentencepiece"然后把实操页的本地推理和评估代码复制到单元格里。先从默认模型开始:
MODEL_ID="sshleifer/tiny-gpt2" python run_local_llm.pypython eval_openllm.py如果 GPU 可用且 Notebook 稳定,再尝试小型 instruct 模型:
MODEL_ID="Qwen/Qwen2.5-0.5B-Instruct" python run_local_llm.py保留这些 Colab 记录:
runtime_type:gpu_visible: yes/nonotebook_url_or_copy:install_cells:first_run_output:files_downloaded_back:what_would_break_if_runtime_resets:不要把私密文档、密钥或长时间服务任务放进免费 Notebook。需要稳定服务时,转向租 GPU 或可控的本地/服务器环境。
路线 C:租 GPU
Section titled “路线 C:租 GPU”只有在本地 CPU 或 Colab 路线已经产出工作证据包后,才租 GPU。租用机器应该只回答一个边界明确的问题,例如:
- 7B 级 instruct 模型能否通过 vLLM 服务化?
- 固定评估集在更大模型上是否通过?
- 这条路线的延迟和显存表现是什么?
先写 gpu_plan.md:
# GPU Plan
goal:model:runtime:instance_vram:disk:region:hourly_budget:hard_stop_time:ports_to_open:access_method: SSH keyevidence_to_copy_back:shutdown_proof:fallback_if_oom:在远程机器上:
python -Vnvidia-smidf -hpython -m pip install -U pippython -m pip install "vllm"先绑定到 localhost:
vllm serve Qwen/Qwen2.5-0.5B-Instruct --host 127.0.0.1 --port 8000从本地机器建立 SSH 隧道:
ssh -L 8000:127.0.0.1:8000 user@your-gpu-host测试 OpenAI 兼容端点:
curl http://127.0.0.1:8000/v1/chat/completions \ -H "Content-Type: application/json" \ -d '{ "model": "Qwen/Qwen2.5-0.5B-Instruct", "messages": [{"role": "user", "content": "Give one deployment rule for a rented GPU."}] }'测试结束后,把证据复制回来,并停止或销毁实例。一个模型 demo 跑通了但机器还在悄悄计费,仍然是一次失败的工程运行。
路线决策练习
Section titled “路线决策练习”继续前先填写:
我会使用 _____,因为 _____。这条路线可以证明 _____。这条路线暂时不能证明 _____。当 _____ 时,我会停止或回退。我必须复制回来的证据是 _____。怎样判断答案是否合格
好的答案会说出约束,而不是只说“更快”。例如:本地 CPU 能证明代码链路,但不能证明服务吞吐;Colab 能测试 Notebook 路径,但不能保证 GPU;租 GPU 能测试服务化,但需要预算、SSH、端口和关机证明。如果答案只写“因为快”,路线决策还不完整。
- Compute Route
- local_cpu / free_colab / rented_gpu and why
- Environment
- Python, torch, CUDA/MPS/CPU, disk, runtime reset risk
- Budget Or Limit
- free quota caveat or rental stop time
- Security
- private data policy, secrets policy, exposed ports
- First Run
- model, command, prompt, output, latency or memory note
- Stop Proof
- Ctrl+C, notebook saved, or rented instance stopped
当你能选择一条计算路线,解释它能证明什么和不能证明什么,运行环境检查,并在进入实操页前说出明确停止或回退步骤,就通过本节。