9.5.3 MCP 架构与核心概念
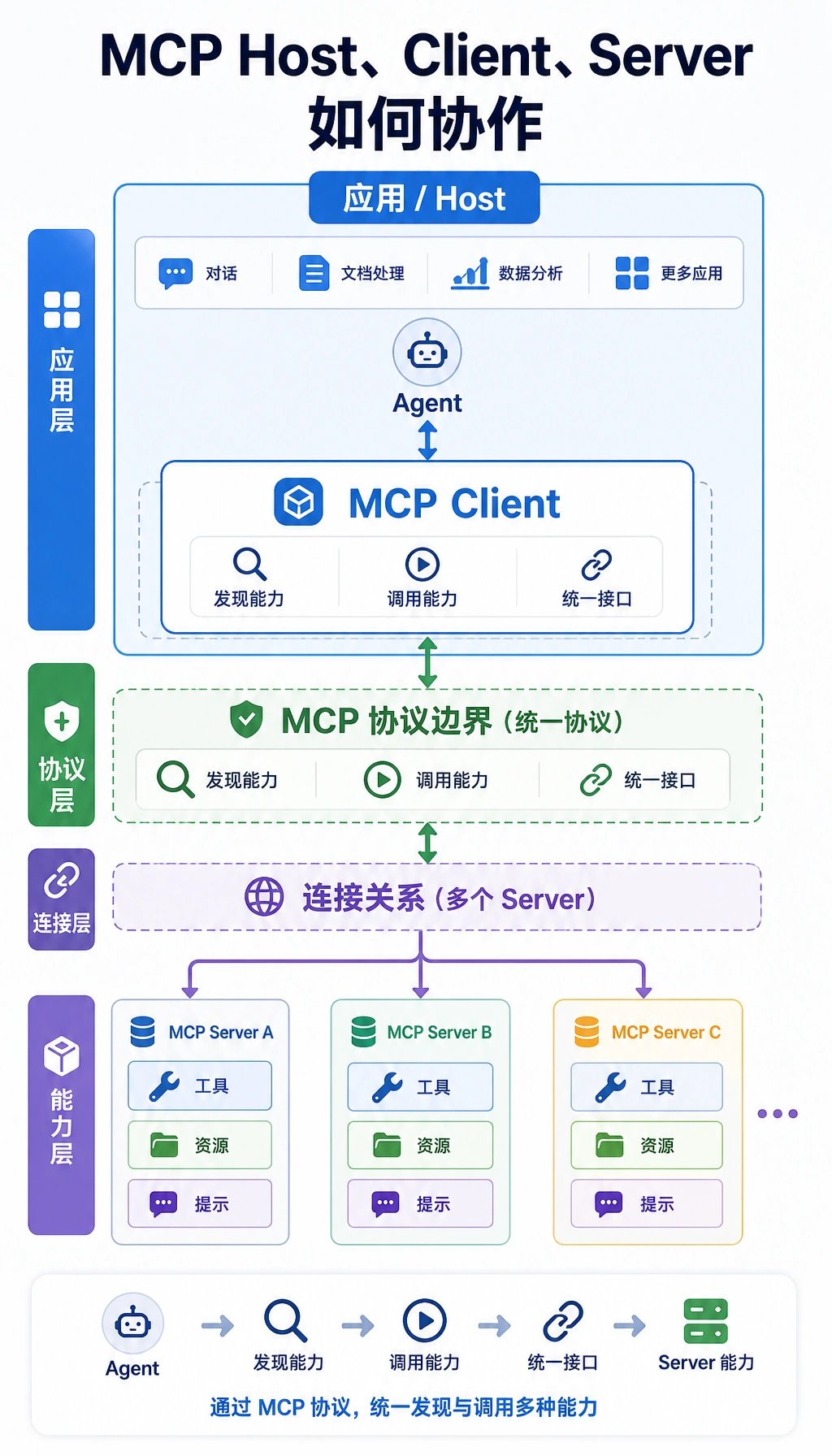
- 理解 MCP 系统里的核心角色分工
- 看懂一条完整的工具发现与调用链路
- 理解 transport 在架构里的位置
- 建立对“协议流”而不是“单个接口”的理解
先把整张架构图看清楚
Section titled “先把整张架构图看清楚”flowchart LR A["Client"] --> B["Transport"] B --> C["MCP Server"] C --> D["Tools / Resources / Prompts"]
C --> E["本地工具逻辑"] C --> F["外部服务"] C --> G["文件系统 / 数据库"]
style A fill:#e3f2fd,stroke:#1565c0,color:#333 style B fill:#fff3e0,stroke:#e65100,color:#333 style C fill:#f3e5f5,stroke:#6a1b9a,color:#333 style D fill:#e8f5e9,stroke:#2e7d32,color:#333 style E fill:#fffde7,stroke:#f9a825,color:#333 style F fill:#fffde7,stroke:#f9a825,color:#333 style G fill:#fffde7,stroke:#f9a825,color:#333这张图里最值得记的不是节点名字,而是:
客户端不直接操作底层世界,而是通过 MCP 服务器这个统一入口拿能力。
客户端到底在做什么?
Section titled “客户端到底在做什么?”客户端的职责通常包括:
- 建立连接
- 发现服务器暴露了哪些能力
- 根据当前任务决定要不要调用
- 发起请求并接收结果
你可以把客户端理解成“使用者”。
在真实系统里,它可能是:
- IDE 插件
- 聊天助手
- 桌面 Agent
- 工作流引擎
它最核心的价值不是“自己会做事”,而是:
知道什么时候该向服务器要什么能力。
服务器到底在做什么?
Section titled “服务器到底在做什么?”服务器的职责通常包括:
- 描述和暴露能力
- 接收客户端请求
- 调用本地或外部工具
- 返回结构化结果
换句话说,服务器更像“能力提供方”。
它相当于对外说:
- 我有什么工具
- 每个工具怎么调用
- 我支持怎样的上下文对象
所以服务器是整个协议落地的核心承载体。
Transport 为什么不能忽略?
Section titled “Transport 为什么不能忽略?”很多初学者会只盯着:
- 客户端
- 服务器
但真正让两者能沟通的,是 transport。
它在解决什么问题?
Section titled “它在解决什么问题?”简单说,它决定:
这些协议消息到底通过什么通道传来传去。
例如:
- 本地进程间通信
- 标准输入输出
- 网络连接
为什么 transport 很重要?
Section titled “为什么 transport 很重要?”因为它会影响:
- 延迟
- 可靠性
- 部署形态
- 调试方式
所以 transport 不是“顺手一选”的小细节,而是架构层的一部分。
MCP 系统里最常见的三类能力
Section titled “MCP 系统里最常见的三类能力”虽然大家经常说“工具”,但更完整一点看,常见暴露内容可以理解成三类:
工具(Tools)
Section titled “工具(Tools)”能被调用执行的能力。
例如:
- 搜索
- 读文件
- 查天气
资源(Resources)
Section titled “资源(Resources)”更偏“可读取的信息源”。
例如:
- 文档内容
- 配置数据
- 数据表快照
提示词(Prompts)
Section titled “提示词(Prompts)”更偏“可复用的提示模板”。
这三类东西并不完全一样,但都属于“对外暴露可用能力”的范畴。
一条完整消息流长什么样?
Section titled “一条完整消息流长什么样?”list_request = { "jsonrpc": "2.0", "id": 1, "method": "tools/list", "params": {}}
list_response = { "jsonrpc": "2.0", "id": 1, "result": { "tools": [ {"name": "search_docs", "description": "搜索课程文档"}, {"name": "get_weather", "description": "查询天气"} ] }}
print(list_request)print(list_response)预期输出:
{'jsonrpc': '2.0', 'id': 1, 'method': 'tools/list', 'params': {}}{'jsonrpc': '2.0', 'id': 1, 'result': {'tools': [{'name': 'search_docs', 'description': '搜索课程文档'}, {'name': 'get_weather', 'description': '查询天气'}]}}call_request = { "jsonrpc": "2.0", "id": 2, "method": "tools/call", "params": { "name": "search_docs", "arguments": {"query": "退款政策"} }}
call_response = { "jsonrpc": "2.0", "id": 2, "result": { "content": [{"type": "text", "text": "课程购买后 7 天内且学习进度低于 20% 可退款。"}] }}
print(call_request)print(call_response)预期输出:
{'jsonrpc': '2.0', 'id': 2, 'method': 'tools/call', 'params': {'name': 'search_docs', 'arguments': {'query': '退款政策'}}}{'jsonrpc': '2.0', 'id': 2, 'result': {'content': [{'type': 'text', 'text': '课程购买后 7 天内且学习进度低于 20% 可退款。'}]}}这两步真正说明了什么?
Section titled “这两步真正说明了什么?”它说明 MCP 不是单纯“调一个函数”,而是先有:
- 能力发现
- 能力调用
这样客户端才不需要把所有工具细节都写死。
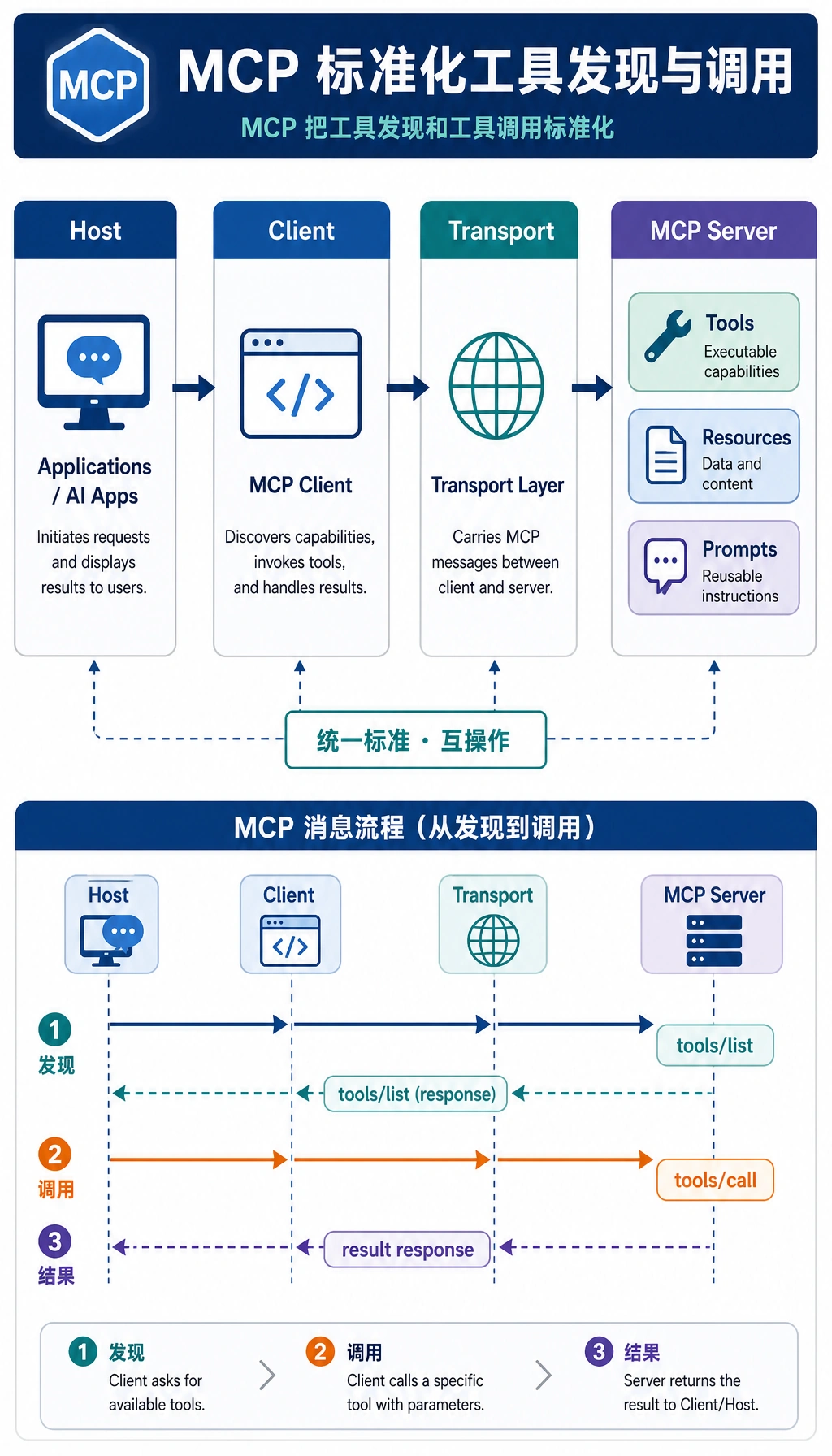
为什么说 MCP 是“解耦层”?
Section titled “为什么说 MCP 是“解耦层”?”没有 MCP 时
Section titled “没有 MCP 时”客户端通常得直接知道:
- 工具怎么命名
- 参数怎么写
- 返回结果长什么样
这会导致客户端和工具提供方强耦合。
有了 MCP 以后
Section titled “有了 MCP 以后”客户端更多依赖的是:
- 统一协议
- 统一发现方式
- 统一调用方式
这让系统形成一种更清晰的分层:
- 上层做任务编排
- 下层做能力提供
所以你可以把 MCP 理解成:
工具生态里的适配层和解耦层。
一个最小的架构模拟
Section titled “一个最小的架构模拟”下面用纯 Python 模拟一个极简的 MCP 交互过程。
class MockMCPServer: def __init__(self): self.tools = { "search_docs": lambda query: f"检索结果: {query}" }
def list_tools(self): return [{"name": name} for name in self.tools]
def call_tool(self, name, arguments): if name not in self.tools: return {"error": "unknown_tool"} return {"result": self.tools[name](**arguments)}
class MockMCPClient: def __init__(self, server): self.server = server
def discover(self): return self.server.list_tools()
def call(self, name, arguments): return self.server.call_tool(name, arguments)
server = MockMCPServer()client = MockMCPClient(server)
print(client.discover())print(client.call("search_docs", {"query": "退款政策"}))预期输出:
[{'name': 'search_docs'}]{'result': '检索结果: 退款政策'}这个例子很小,但非常有教学价值
Section titled “这个例子很小,但非常有教学价值”因为它已经体现了三层分工:
- 客户端负责请求
- 服务器负责能力暴露
- tool 负责具体执行
只要这三层分工想清楚,后面再看更真实的 MCP 系统就会稳很多。
最常见的架构误区
Section titled “最常见的架构误区”把服务器当成工具本身
Section titled “把服务器当成工具本身”服务器不是工具,而是:
工具的协议化出口。
觉得 transport 可有可无
Section titled “觉得 transport 可有可无”transport 直接影响部署和稳定性。
以为 MCP 自动解决权限和策略问题
Section titled “以为 MCP 自动解决权限和策略问题”不会。 它解决的是“统一接入”,不是“自动治理”。
学完这一页,至少保留这张证据卡:
- 能力
- 服务器暴露的资源、Prompt 或工具
- 契约
- schema、传输、权限和错误形式
- 调用轨迹
- 发现、调用、响应和失败处理
- 失败检查
- 架构不兼容、缺少认证、不安全工具或服务器错误
- 集成动作
- 在加入自主能力前先验证服务端契约
这一节最重要的不是记住客户端/服务器这几个词,而是看懂:
MCP 架构的核心,是让能力提供方和能力使用方通过统一消息流和统一边界发生关系。
只要这条流动逻辑清楚,后面再学服务器开发、客户端集成和生态实践时,就不容易发虚。
- 用自己的话解释:为什么客户端和服务器的职责必须分开?
- 想一想:如果 transport 换掉,为什么上层调用逻辑最好尽量不变?
- 给
MockMCPServer再加一个get_weather工具。 - 用自己的话解释:为什么说 MCP 是“解耦层”,而不是“工具本身”?
参考实现与讲解
- client 和 server 要分工,是因为 client 负责编排、用户上下文和策略,server 负责能力实现与契约。如果混在一起,每新增工具或更换 transport,都会牵动整个系统。
- transport 应该可替换,因为一次工具调用的语义不应该依赖它走 stdio、HTTP 还是别的通道。好的架构会保持调用契约稳定,只替换传输方式。
- 一个合格的
get_weather扩展,应该包含清晰的名称、描述、必需的city参数、对空字符串或非字符串城市名的校验,以及输入无效时稳定的错误结构。 - MCP 被称为解耦层,是因为它定义跨边界描述和调用能力的方式。它不是工具本身;天气查询、文件读取、数据库查询这些真正能力仍然在 server 实现后面。