7.3.1 Transformer 深入路线图:Block、Mask、成本
本小章往 Transformer 内部看一层,帮助你调试 LLM 行为,并理解上下文长度、attention、KV cache 和模型变体为什么重要。


第二张图按调试路线来读:信息流、计算成本和任务适配要放在一起判断。
构造 causal mask
Section titled “构造 causal mask”seq_len = 4mask = []for query_pos in range(seq_len): row = [] for key_pos in range(seq_len): row.append("allow" if key_pos <= query_pos else "block") mask.append(row)
for row in mask: print(row)预期输出:
['allow', 'block', 'block', 'block']['allow', 'allow', 'block', 'block']['allow', 'allow', 'allow', 'block']['allow', 'allow', 'allow', 'allow']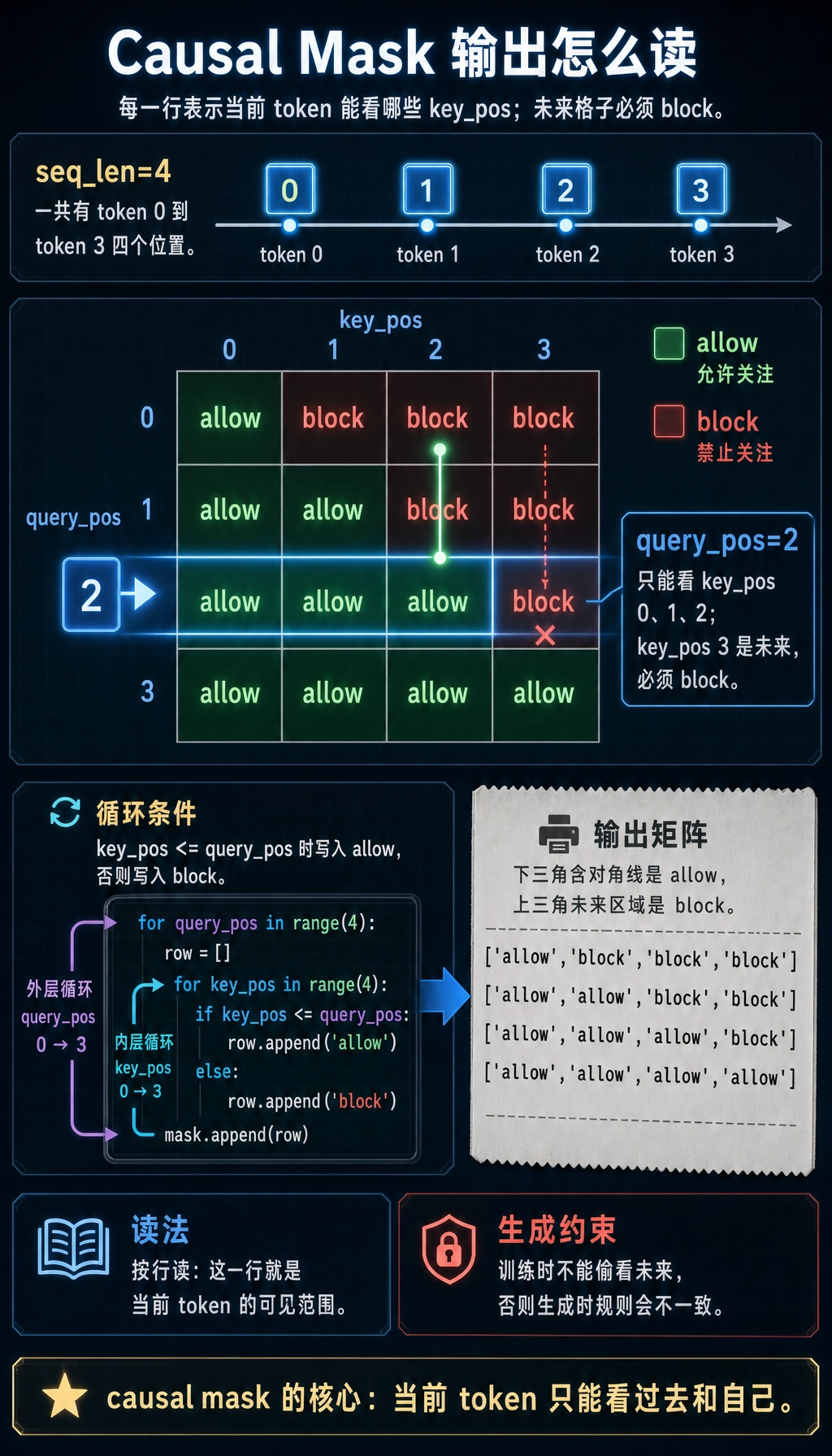
生成任务使用这种“不看未来”的规则:一个 token 可以看前面的 token,但不能看未来 token。
按这个顺序学
Section titled “按这个顺序学”| 顺序 | 阅读 | 先抓住什么 |
|---|---|---|
| 1 | 7.3.2 架构回顾 | attention、残差、归一化 |
| 2 | 7.3.3 现代解码器块 | 仅解码器 LLM 块 |
| 3 | 7.3.4 模型变体 | 编码器、解码器、编码器-解码器 |
| 4 | 7.3.5 高效 Attention | KV cache、MQA/GQA、长上下文 |
| 5 | 7.3.6 规模与计算 | 成本、延迟、显存 |
学完这一页,至少保留这张证据卡:
- 块契约
- 输入和输出都是 [batch, seq, d_model]
- mask 检查
- 因果掩码阻止未来位置
- KV 缓存原因
- 推理会复用之前的 keys 和 values
- 计算说明
- 注意力成本随序列长度增加
- 桥接
- 这些细节解释了应用中的延迟和上下文限制
能解释 decoder-only 模型为什么需要 causal mask、为什么上下文变长会让 attention 变贵,以及 KV cache 为什么能帮助生成,就算通过。
检查思路与讲解
- 合格答案要说明 token、上下文、attention、prompt 和生成行为如何组成一次请求到回答的路径。
- 证据至少包含一个可复现 prompt 或结构化输出测试,并说明输出为什么通过或失败。
- 自检时要区分 prompt、RAG、微调和对齐:优先使用能解决已观察问题的最轻方案。