E.A.4 推理引擎
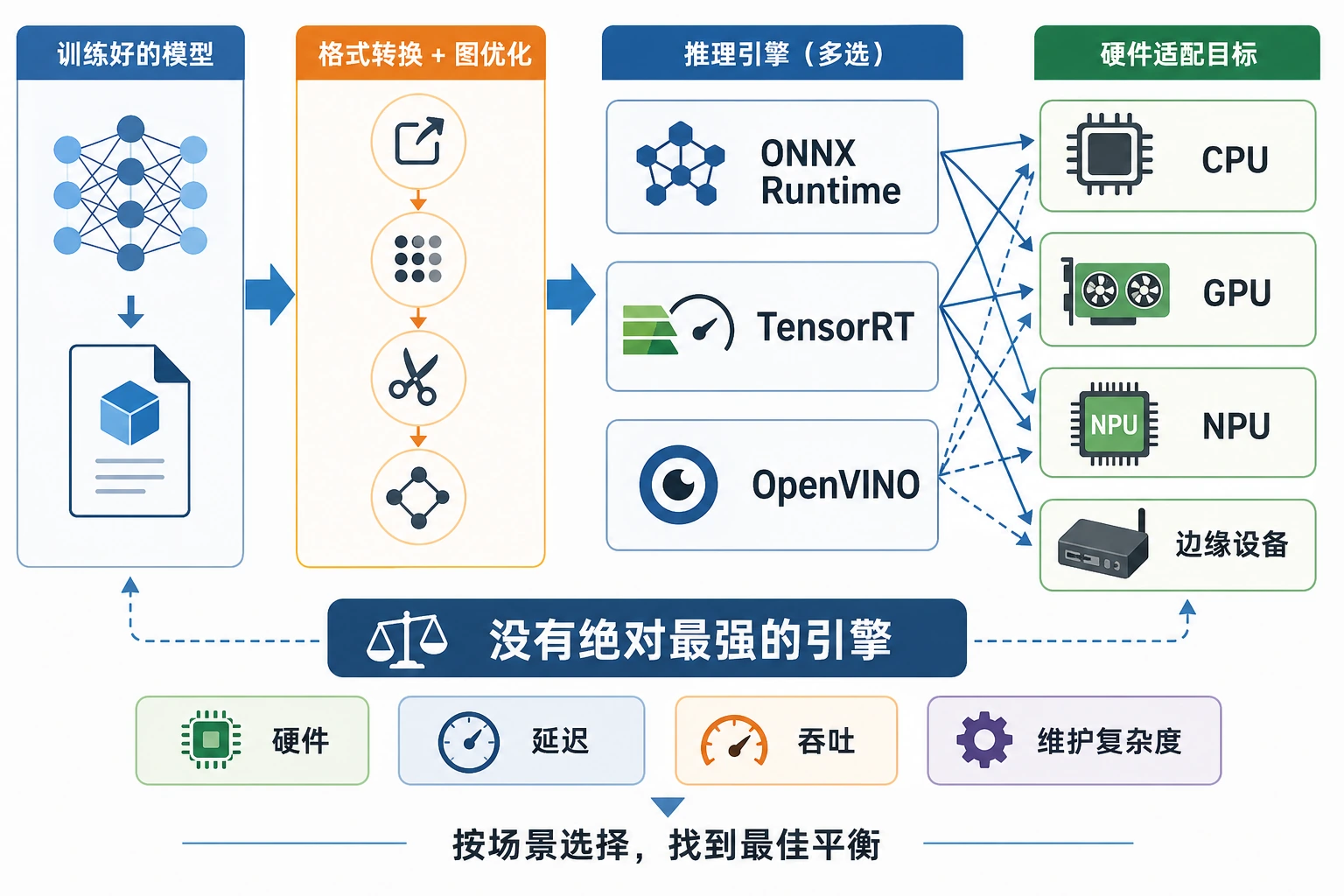
推理引擎是训练好的模型和真实硬件之间的运行层。模型说明“要算什么”,推理引擎决定“怎样在 CPU、GPU、NPU 或边缘硬件上高效执行”。
这一节先做一个选型小练习。不要把某个引擎记成永远最好,要看部署约束。
- Python 3.10+
- 不需要第三方包
- 花 5 分钟运行并修改一个评分脚本
- Latency(延迟):一次请求从进入到拿到结果要等多久。
- Throughput(吞吐):系统每秒能完成多少请求。
- Backend(后端):面向具体硬件的执行路径,例如 CPU、CUDA、TensorRT、OpenVINO。
- ONNX:常用的模型交换格式。
- Operator(算子):模型图里的一个操作,例如矩阵乘法、卷积、归一化。
运行引擎选择器
Section titled “运行引擎选择器”创建 engine_selector.py:
engines = [ { "name": "ONNX Runtime", "hardware": ["cpu", "nvidia"], "formats": ["onnx"], "latency": "medium", "ops": "easy", }, { "name": "TensorRT", "hardware": ["nvidia"], "formats": ["onnx", "engine"], "latency": "low", "ops": "hard", }, { "name": "OpenVINO", "hardware": ["cpu", "intel"], "formats": ["onnx", "ir"], "latency": "low", "ops": "medium", },]
need = {"hardware": "nvidia", "format": "onnx", "latency": "low"}
for engine in engines: score = 0 score += 2 if need["hardware"] in engine["hardware"] else -3 score += 2 if need["format"] in engine["formats"] else -2 score += 1 if need["latency"] == engine["latency"] else 0 score -= 1 if engine["ops"] == "hard" else 0 engine["score"] = score
best = max(engines, key=lambda item: item["score"])
for engine in engines: print(engine["name"], engine["score"])
print("selected:", best["name"])运行:
python engine_selector.py预期输出:
ONNX Runtime 4TensorRT 4OpenVINO 0selected: ONNX Runtime这里 ONNX Runtime 和 TensorRT 分数相同,脚本选择了第一个。这个结果是故意保留的:真实部署里,如果更快的路线会增加构建和维护成本,简单路线反而可能更适合作为第一版。
把:
need = {"hardware": "nvidia", "format": "onnx", "latency": "low"}print(need)第一个片段的预期输出:
{'hardware': 'nvidia', 'format': 'onnx', 'latency': 'low'}改成:
need = {"hardware": "intel", "format": "onnx", "latency": "low"}print(need)第二个片段的预期输出:
{'hardware': 'intel', 'format': 'onnx', 'latency': 'low'}再次运行。预期结果:
ONNX Runtime -1TensorRT -2OpenVINO 5selected: OpenVINO核心结论很简单:硬件变了,引擎选择也会变。
实用选型顺序
Section titled “实用选型顺序”做高级调优前,先按这个顺序判断:
- 确认目标硬件。
- 确认引擎能加载的模型格式。
- 检查是否有不支持的算子。
- 用相同输入尺寸比较延迟和吞吐。
- 选择能达标且最容易维护的引擎。
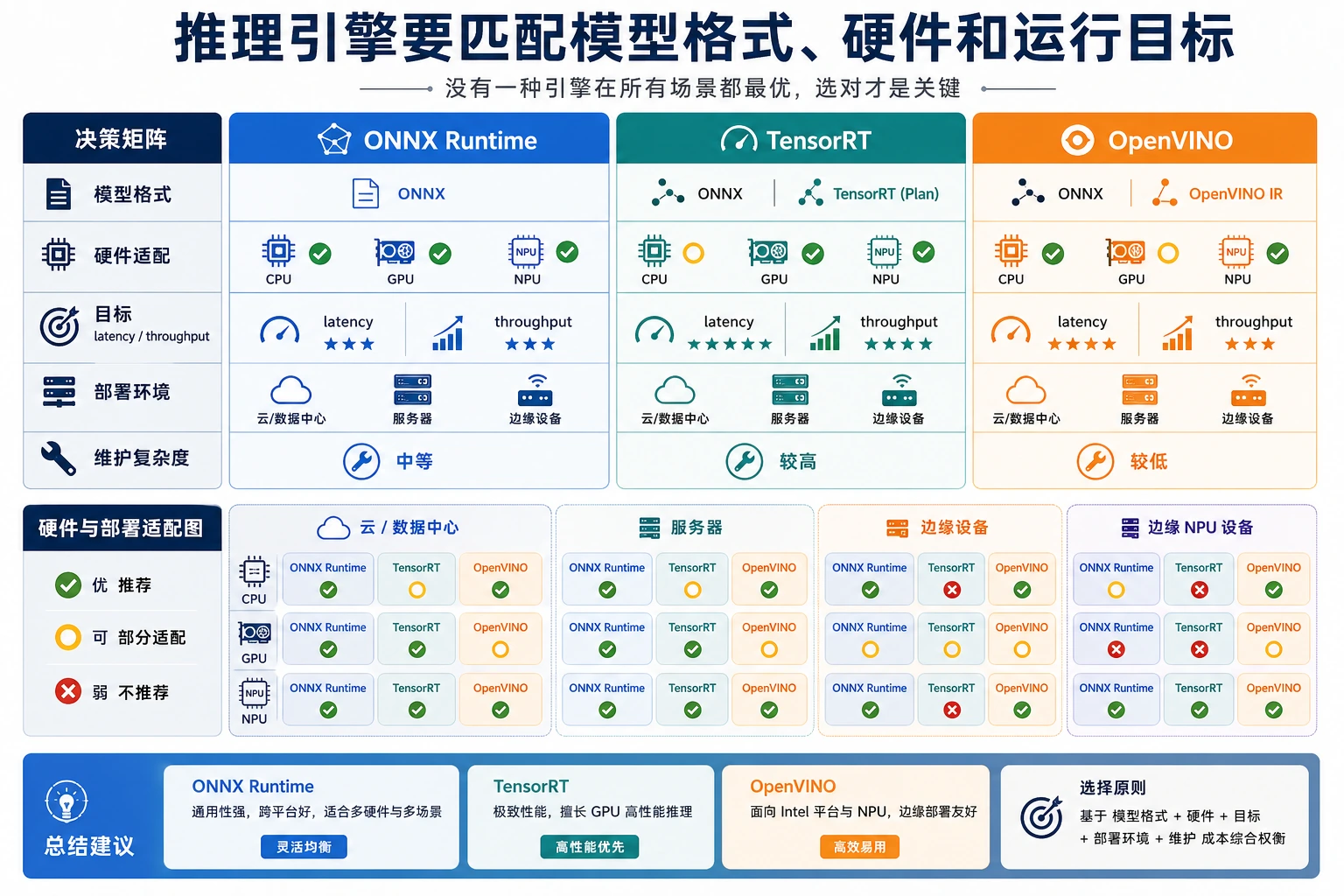
推理引擎选择要同时写下“为什么选它”和“为什么暂时不选另一个”。例如 TensorRT 可能更快,但构建流程、算子兼容和团队维护成本也更高。ONNX Runtime 可能不是极限性能路线,却常常适合第一版可复现交付。
复盘时至少保留三个证据:目标硬件、模型格式和一组相同输入下的延迟/吞吐记录。没有这些证据,就不要把选择写成“最佳引擎”。
学完这一页,至少保留这张证据卡:
- 部署目标
- 本地推理、边缘设备、模型服务器或优化实验
- 工件
- C++ 代码片段、基准测试、模型工件、服务配置或部署说明
- 指标
- 延迟、内存、吞吐量、模型大小、准确率下降或可靠性
- 失败检查
- ABI/构建问题、硬件不匹配、量化损失或服务瓶颈
- 期望产出
- 可复现的部署或优化证据,而不只是理论笔记
- 因为 TensorRT 快,就不考虑团队是否能维护 engine 构建流程。
- 用很小的输入测试,生产输入变大后才发现很慢。
- 到上线前一周才发现有算子不支持。
给每个引擎加一个 memory 字段;如果超过设备内存,就扣 1 分。然后分别用 CPU-only、NVIDIA GPU、Intel 设备三种场景重新选择。
参考实现与讲解
好的答案会把内存当成真实约束,而不是装饰性字段。比如目标设备只允许 memory_limit=1024,某个引擎的 memory=1800,即使延迟分数很好,也应该扣分或标记为高风险。
预期推理方式:
- CPU-only 场景通常选择 CPU 支持好且内存不过线的引擎。
- NVIDIA GPU 场景在格式和算子都支持时可能偏向 TensorRT。
- Intel 硬件通常会把选择推向 OpenVINO。
- 最终选择要同时说明分数和部署风险,而不是只说谁最快。