3.6.1 实战项目:探索性数据分析(EDA)
先建立一张地图
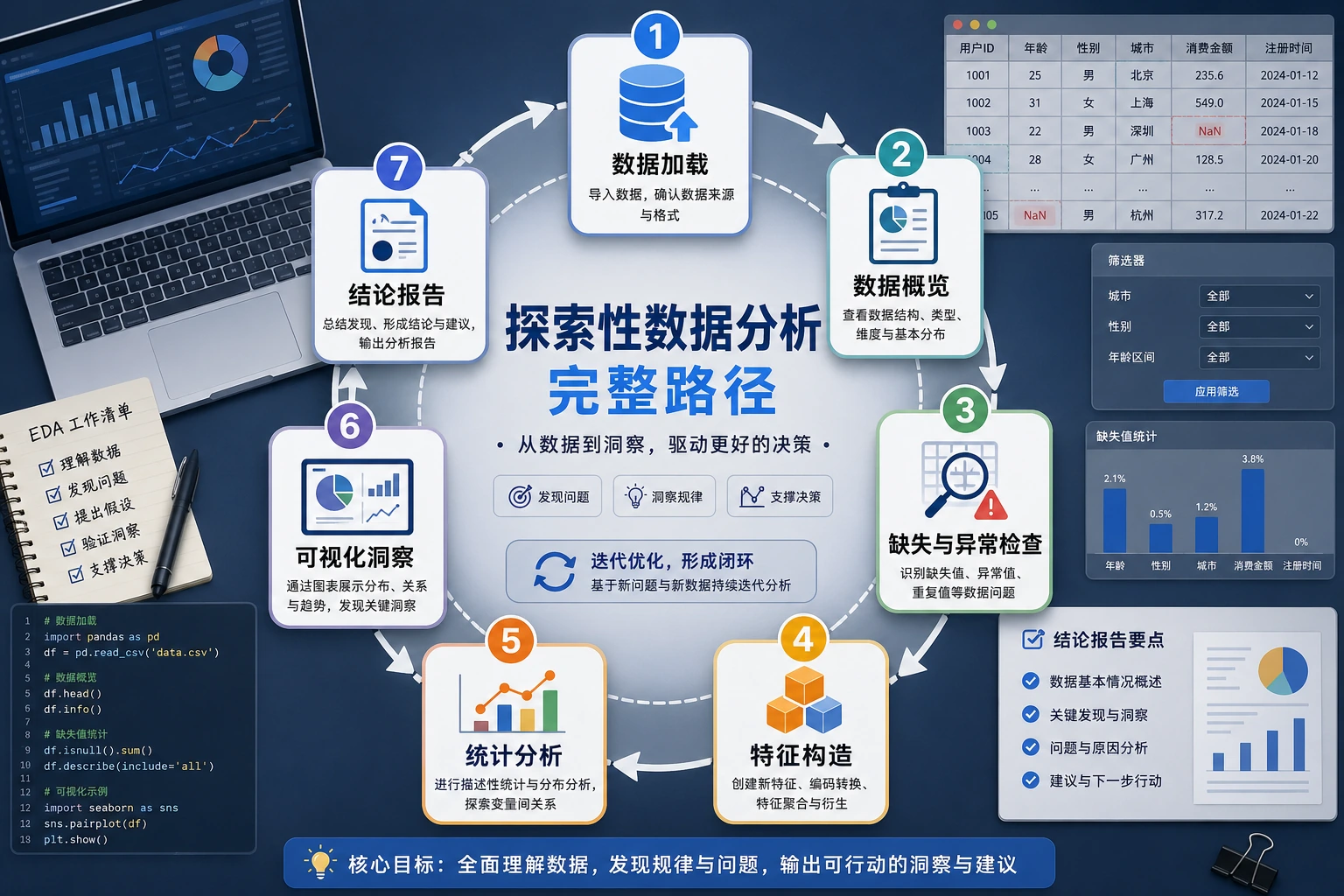
Section titled “先建立一张地图”第一次做 EDA 项目,最稳的顺序不是“先把图都画出来”,而是先看清:
flowchart LR A["先摸底数据"] --> B["再做清洗"] B --> C["再做统计和分组分析"] C --> D["再画图验证结论"] D --> E["最后写出清楚结论"]所以这个项目真正想练的是:
- 不是会不会写几张图
- 而是能不能把“看数据 -> 得结论”走成一条完整链
探索性数据分析(Exploratory Data Analysis, EDA) 是数据科学项目的第一步——在建模之前,先用统计和可视化手段”摸清”数据的底细。
flowchart LR A["拿到数据"] --> B["初步了解"] B --> C["数据清洗"] C --> D["统计分析"] D --> E["可视化探索"] E --> F["得出结论 & 撰写报告"]
style A fill:#e3f2fd,stroke:#1565c0,color:#333 style F fill:#e8f5e9,stroke:#2e7d32,color:#333一个更适合新人的总类比
Section titled “一个更适合新人的总类比”你可以把 EDA 理解成:
- 真正做模型前的一次现场勘察
你不会在还没看清地形的时候就直接开工。 同样地,在数据项目里,你也不该在还没看清:
- 分布
- 缺失
- 异常
- 变量关系
之前就急着建模。
你将练到的技能
Section titled “你将练到的技能”| 技能 | 对应章节 |
|---|---|
| Pandas 数据读取与清洗 | 第 3 章 |
| 统计摘要与分组聚合 | 第 3 章 |
| Matplotlib / Seaborn 可视化 | 第 4 章 |
| NumPy 数值计算 | 第 2 章 |
完成后你会得到一份完整的 EDA 分析报告(Jupyter Notebook),包含数据概览、清洗过程、统计发现和可视化图表。
一、项目准备
Section titled “一、项目准备”我们选用 Seaborn 内置的 tips 数据集——一个美国餐厅的小费记录。
| 字段 | 含义 | 类型 |
|---|---|---|
total_bill | 消费总额(美元) | 连续型 |
tip | 小费金额(美元) | 连续型 |
sex | 顾客性别 | 分类型 |
smoker | 是否吸烟 | 分类型 |
day | 星期几 | 分类型 |
time | 午餐/晚餐 | 分类型 |
size | 就餐人数 | 离散型 |
# 导入所有需要的库import numpy as npimport pandas as pdimport matplotlib.pyplot as pltimport seaborn as sns
# 设置中文显示(macOS)plt.rcParams['font.sans-serif'] = ['Arial Unicode MS']# Windows 用户可以用:plt.rcParams['font.sans-serif'] = ['SimHei']plt.rcParams['axes.unicode_minus'] = False
# 设置 Seaborn 主题sns.set_theme(style="whitegrid", font_scale=1.1)
# Jupyter 中图表内嵌显示# %matplotlib inline# 加载内置数据集tips = sns.load_dataset("tips")
# 第一眼:看看数据长什么样print(f"数据集大小:{tips.shape[0]} 行 × {tips.shape[1]} 列")tips.head(10)输出示例:
这个数据集包含这些列:total_bill、tip、sex、smoker、day、time、size。
第一眼只需要看两条样本:
| 行号 | 这条记录说明什么 |
|---|---|
| 0 | 周日晚餐,2 人,总消费 16.99,小费 1.01,非吸烟顾客 |
| 1 | 周日晚餐,3 人,总消费 10.34,小费 1.66,非吸烟顾客 |
二、数据概览——先”摸底”
Section titled “二、数据概览——先”摸底””EDA 的第一步,不是急着画图,而是先搞清楚:数据有多大?每列是什么类型?有没有缺失值?
第一次看数据时,最该先问什么?
Section titled “第一次看数据时,最该先问什么?”最值得先问这 4 个问题:
- 这张表有多大?
- 每列是什么类型?
- 有没有缺失值?
- 目标分析字段大概长什么样?
只要这 4 个问题先答清楚,后面很多分析动作就不会乱。
# 数据类型和非空计数tips.info()输出会告诉你:
- 7 列,244 行
- 没有缺失值(Non-Null Count 全是 244)
total_bill和tip是 float64sex、smoker、day、time是 category
# 统计摘要tips.describe()| total_bill | tip | size | |
|---|---|---|---|
| count | 244.0 | 244.0 | 244.0 |
| mean | 19.79 | 3.00 | 2.57 |
| std | 8.90 | 1.38 | 0.95 |
| min | 3.07 | 1.00 | 1.00 |
| 25% | 13.35 | 2.00 | 2.00 |
| 50% | 17.80 | 2.90 | 2.00 |
| 75% | 24.13 | 3.56 | 3.00 |
| max | 50.81 | 10.00 | 6.00 |
发现:
- 人均消费约 19.79 美元,小费约 3.00 美元
- 小费最少 1 美元,最多 10 美元
- 就餐人数大多是 2 人
分类变量分布
Section titled “分类变量分布”# 分类变量各取值的计数for col in ['sex', 'smoker', 'day', 'time']: print(f"\n--- {col} ---") print(tips[col].value_counts())发现:
- 男性顾客多于女性(157 vs 87)
- 不吸烟的多于吸烟的(151 vs 93)
- 周六和周日数据最多
- 晚餐数据远多于午餐(176 vs 68)
添加衍生特征
Section titled “添加衍生特征”好的分析师会创造新特征来帮助发现规律:
# 小费比例 = 小费 / 消费总额tips['tip_pct'] = (tips['tip'] / tips['total_bill'] * 100).round(2)
# 人均消费tips['per_person'] = (tips['total_bill'] / tips['size']).round(2)
tips[['total_bill', 'tip_pct', 'per_person']].head()| 行号 | total_bill | tip_pct | per_person |
|---|---|---|---|
| 0 | 16.99 | 5.94 | 8.50 |
| 1 | 10.34 | 16.05 | 3.45 |
| 2 | 21.01 | 16.66 | 7.00 |
三、数据清洗——检查数据质量
Section titled “三、数据清洗——检查数据质量”这个数据集比较干净,但真实项目中这一步通常最耗时间。我们依然走一遍完整流程:
# 缺失值统计missing = tips.isnull().sum()print("缺失值统计:")print(missing[missing > 0] if missing.sum() > 0 else "无缺失值 ✓")# 完全重复的行dup_count = tips.duplicated().sum()print(f"重复行数:{dup_count}")
if dup_count > 0: tips = tips.drop_duplicates() print(f"已删除重复行,剩余 {len(tips)} 行")用 IQR(四分位距)方法检测异常值:
def detect_outliers_iqr(df, column): """用 IQR 方法检测异常值""" Q1 = df[column].quantile(0.25) Q3 = df[column].quantile(0.75) IQR = Q3 - Q1 lower = Q1 - 1.5 * IQR upper = Q3 + 1.5 * IQR
outliers = df[(df[column] < lower) | (df[column] > upper)] return outliers, lower, upper
# 检查各数值列的异常值for col in ['total_bill', 'tip', 'tip_pct']: outliers, lower, upper = detect_outliers_iqr(tips, col) print(f"\n{col}:正常范围 [{lower:.2f}, {upper:.2f}],异常值 {len(outliers)} 个") if len(outliers) > 0: print(f" 异常值示例:{outliers[col].values[:5]}")四、统计分析——用数字说话
Section titled “四、统计分析——用数字说话”核心统计指标
Section titled “核心统计指标”# 按性别分组的小费统计tips.groupby('sex')[['total_bill', 'tip', 'tip_pct']].agg(['mean', 'median', 'std'])# 按 day 分组day_stats = tips.groupby('day')[['total_bill', 'tip']].agg(['mean', 'count'])print(day_stats)# 透视表:不同性别 + 是否吸烟 的小费比例pivot = tips.pivot_table( values='tip_pct', index='sex', columns='smoker', aggfunc='mean').round(2)
print("小费比例(%):")print(pivot)示例输出:
| smoker | No | Yes |
|---|---|---|
| Female | 15.69 | 18.22 |
| Male | 16.07 | 15.28 |
发现:女性吸烟者给的小费比例最高,男性吸烟者给的最低。
# 数值列的相关系数numeric_cols = ['total_bill', 'tip', 'size', 'tip_pct', 'per_person']corr_matrix = tips[numeric_cols].corr().round(3)print(corr_matrix)关键发现:
total_bill和tip正相关(约 0.68)→ 消费越多,小费越多total_bill和tip_pct负相关(约 -0.09)→ 消费越多,小费比例反而略低size和total_bill正相关(约 0.60)→ 人越多,消费越高
一个新人很适合先记的分析顺序
Section titled “一个新人很适合先记的分析顺序”做 EDA 时,更稳的顺序通常是:
- 先看单变量分布
- 再看分类变量计数
- 再看两个变量关系
- 最后才做组合分析和多维对比
这样会比一开始就直接上复杂分面图更容易看清主线。
五、可视化探索——让数据说话
Section titled “五、可视化探索——让数据说话”fig, axes = plt.subplots(1, 3, figsize=(15, 4))
# 消费总额分布axes[0].hist(tips['total_bill'], bins=20, color='steelblue', edgecolor='white')axes[0].set_title('消费总额分布')axes[0].set_xlabel('金额(美元)')axes[0].set_ylabel('频次')
# 小费分布axes[1].hist(tips['tip'], bins=20, color='coral', edgecolor='white')axes[1].set_title('小费分布')axes[1].set_xlabel('金额(美元)')
# 小费比例分布axes[2].hist(tips['tip_pct'], bins=20, color='mediumseagreen', edgecolor='white')axes[2].set_title('小费比例(%)分布')axes[2].set_xlabel('百分比')
plt.tight_layout()plt.savefig('01_distribution.png', dpi=150, bbox_inches='tight')plt.show()解读:消费总额和小费都呈右偏分布——大多数人消费在 10-25 美元之间,小费在 2-4 美元之间。
分类变量可视化
Section titled “分类变量可视化”fig, axes = plt.subplots(2, 2, figsize=(12, 10))
# 按天统计sns.countplot(data=tips, x='day', order=['Thur', 'Fri', 'Sat', 'Sun'], palette='Blues_d', ax=axes[0, 0])axes[0, 0].set_title('各天的顾客数')
# 按时间段sns.countplot(data=tips, x='time', palette='Set2', ax=axes[0, 1])axes[0, 1].set_title('午餐 vs 晚餐')
# 按性别sns.countplot(data=tips, x='sex', palette='Pastel1', ax=axes[1, 0])axes[1, 0].set_title('顾客性别分布')
# 按吸烟状态sns.countplot(data=tips, x='smoker', palette='Pastel2', ax=axes[1, 1])axes[1, 1].set_title('吸烟 vs 不吸烟')
plt.tight_layout()plt.savefig('02_categorical.png', dpi=150, bbox_inches='tight')plt.show()关键关系探索
Section titled “关键关系探索”消费与小费的关系
Section titled “消费与小费的关系”fig, axes = plt.subplots(1, 2, figsize=(14, 5))
# 散点图:消费 vs 小费sns.scatterplot(data=tips, x='total_bill', y='tip', hue='time', style='smoker', s=80, alpha=0.7, ax=axes[0])axes[0].set_title('消费金额 vs 小费')axes[0].set_xlabel('消费总额(美元)')axes[0].set_ylabel('小费(美元)')
# 回归线sns.regplot(data=tips, x='total_bill', y='tip', scatter_kws={'alpha': 0.5}, line_kws={'color': 'red'}, ax=axes[1])axes[1].set_title('消费金额 vs 小费(含趋势线)')axes[1].set_xlabel('消费总额(美元)')axes[1].set_ylabel('小费(美元)')
plt.tight_layout()plt.savefig('03_bill_vs_tip.png', dpi=150, bbox_inches='tight')plt.show()解读:消费金额越高,小费也越高,呈明显的线性趋势。但也能看到一些”离群点”——有人消费 40 多美元只给了 1.5 美元小费。
不同场景的小费比较
Section titled “不同场景的小费比较”fig, axes = plt.subplots(1, 3, figsize=(16, 5))
# 按天比较小费sns.boxplot(data=tips, x='day', y='tip', order=['Thur', 'Fri', 'Sat', 'Sun'], palette='coolwarm', ax=axes[0])axes[0].set_title('各天小费分布')
# 按时间段比较sns.violinplot(data=tips, x='time', y='tip', palette='Set2', ax=axes[1])axes[1].set_title('午餐 vs 晚餐小费分布')
# 按就餐人数比较sns.boxplot(data=tips, x='size', y='tip', palette='YlOrRd', ax=axes[2])axes[2].set_title('不同就餐人数的小费')
plt.tight_layout()plt.savefig('04_tip_comparison.png', dpi=150, bbox_inches='tight')plt.show()解读:
- 周日的小费中位数最高
- 晚餐小费整体高于午餐(因为晚餐消费更多)
- 人数越多,小费越高
相关性热力图
Section titled “相关性热力图”plt.figure(figsize=(8, 6))
# 绘制热力图sns.heatmap( corr_matrix, annot=True, # 显示数字 fmt='.2f', # 保留两位小数 cmap='RdBu_r', # 红蓝配色 center=0, # 0 为中心 square=True, # 正方形格子 linewidths=0.5 # 格线宽度)plt.title('数值变量相关性矩阵')plt.tight_layout()plt.savefig('05_correlation.png', dpi=150, bbox_inches='tight')plt.show()组合多维度分析
Section titled “组合多维度分析”# FacetGrid:按性别和是否吸烟,看消费-小费关系g = sns.FacetGrid(tips, col='sex', row='smoker', height=4, aspect=1.2, margin_titles=True)g.map_dataframe(sns.scatterplot, x='total_bill', y='tip', hue='time', alpha=0.7)g.add_legend()g.set_axis_labels('消费总额(美元)', '小费(美元)')g.fig.suptitle('按性别 × 吸烟状态分面', y=1.02, fontsize=14)plt.savefig('06_facet.png', dpi=150, bbox_inches='tight')plt.show()六、分析结论
Section titled “六、分析结论”经过完整的 EDA,我们得出以下结论:
root((EDA 核心发现)) 消费模式 大多数消费在 10-25 美元 晚餐消费高于午餐 周末顾客最多 小费规律 平均小费约 15-16% 消费越高 小费金额越大 但小费比例略有下降 人群差异 男性消费略高于女性 吸烟者和非吸烟者差异不大 就餐人数是关键因素- 消费与小费正相关:消费总额越高,小费金额越高(相关系数 0.68),但小费比例反而略有下降
- 晚餐消费高于午餐:晚餐的平均消费和小费都显著高于午餐
- 周末是高峰:周六和周日的顾客最多,消费也最高
- 就餐人数影响大:人数越多,总消费越高(相关系数 0.60)
- 性别差异小:男女在小费比例上差异不大(约 1 个百分点)
- 吸烟状态影响有限:吸烟与否对小费比例影响不显著
给餐厅的建议
Section titled “给餐厅的建议”- 周末晚餐是营收重点时段,应确保服务质量
- 鼓励大桌就餐(人多消费多,小费也多)
- 可以针对午餐推出套餐,提高午间客流
一个很适合初学者先记的“结论写法”
Section titled “一个很适合初学者先记的“结论写法””好的 EDA 结论通常不是:
- 我画了很多图
而是:
- 我发现了什么
- 我是根据哪些图和统计发现的
- 这对业务意味着什么
这个顺序特别重要,因为它会让你的 Notebook 从“图很多”变成“有分析结论”。
七、代码整合——完整分析脚本
Section titled “七、代码整合——完整分析脚本”将上面的分析整合成一个结构清晰的脚本:
"""Tips 数据集 - 探索性数据分析(EDA)====================================分析目标:理解餐厅消费和小费的影响因素"""
# ========== 1. 导入与配置 ==========import numpy as npimport pandas as pdimport matplotlib.pyplot as pltimport seaborn as sns
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS']plt.rcParams['axes.unicode_minus'] = Falsesns.set_theme(style="whitegrid", font_scale=1.1)
# ========== 2. 数据加载 ==========tips = sns.load_dataset("tips")print(f"数据集:{tips.shape[0]} 行 × {tips.shape[1]} 列\n")
# ========== 3. 数据概览 ==========print("=== 基本信息 ===")tips.info()print("\n=== 统计摘要 ===")print(tips.describe().round(2))
# ========== 4. 特征工程 ==========tips['tip_pct'] = (tips['tip'] / tips['total_bill'] * 100).round(2)tips['per_person'] = (tips['total_bill'] / tips['size']).round(2)
# ========== 5. 数据质量检查 ==========print(f"\n缺失值:{tips.isnull().sum().sum()}")print(f"重复行:{tips.duplicated().sum()}")
# ========== 6. 统计分析 ==========print("\n=== 按性别分组 ===")print(tips.groupby('sex')[['total_bill', 'tip', 'tip_pct']].mean().round(2))
print("\n=== 按天分组 ===")print(tips.groupby('day')[['total_bill', 'tip']].agg(['mean', 'count']).round(2))
print("\n=== 相关性矩阵 ===")print(tips[['total_bill', 'tip', 'size', 'tip_pct']].corr().round(3))
# ========== 7. 可视化 ==========# 此处参考上面第五节的可视化代码# 在 Jupyter Notebook 中逐个运行效果最佳
print("\n分析完成!")八、进阶挑战
Section titled “八、进阶挑战”完成基础 EDA 后,试试这些挑战:
挑战 1:换一个数据集
Section titled “挑战 1:换一个数据集”用 Seaborn 内置的 diamonds 数据集做 EDA:
diamonds = sns.load_dataset("diamonds")print(diamonds.shape) # 53940 行 × 10 列print(diamonds.head())分析方向:
- 哪些因素影响钻石价格?
- 切工(cut)、颜色(color)、净度(clarity)如何影响价格?
- 克拉数(carat)和价格是线性关系吗?
挑战 2:自动化 EDA 报告
Section titled “挑战 2:自动化 EDA 报告”试试用代码自动生成一份简单的报告:
def quick_eda(df, title="EDA Report"): """快速生成 EDA 报告""" print(f"{'='*50}") print(f" {title}") print(f"{'='*50}")
# 基本信息 print(f"\n📊 数据集大小:{df.shape[0]} 行 × {df.shape[1]} 列")
# 数据类型统计 print(f"\n📋 数据类型:") print(df.dtypes.value_counts().to_string())
# 缺失值 missing = df.isnull().sum() if missing.sum() > 0: print(f"\n⚠️ 缺失值:") print(missing[missing > 0].to_string()) else: print(f"\n✅ 无缺失值")
# 数值列统计 num_cols = df.select_dtypes(include=[np.number]).columns if len(num_cols) > 0: print(f"\n📈 数值列统计:") print(df[num_cols].describe().round(2).to_string())
# 分类列统计 cat_cols = df.select_dtypes(include=['object', 'category']).columns for col in cat_cols: print(f"\n🏷️ {col} 分布:") print(df[col].value_counts().head(5).to_string())
return None
# 使用quick_eda(tips, "Tips 数据集 EDA")挑战 3:用 Plotly 做交互版
Section titled “挑战 3:用 Plotly 做交互版”如果你学了第 4 章的 Plotly,试试把静态图表替换成交互版:
import plotly.express as px
# 交互式散点图fig = px.scatter( tips, x='total_bill', y='tip', color='time', size='size', hover_data=['sex', 'smoker', 'day'], title='消费金额 vs 小费(交互版)')fig.show()九、EDA 检查清单
Section titled “九、EDA 检查清单”完成项目后,对照检查:
| 检查项 | 是否完成 |
|---|---|
| 加载数据并查看前几行 | ☐ |
查看 info() 和 describe() | ☐ |
| 检查缺失值和重复值 | ☐ |
| 检测异常值 | ☐ |
| 创建有意义的衍生特征 | ☐ |
| 绘制数值变量的分布图 | ☐ |
| 绘制分类变量的计数图 | ☐ |
| 探索变量之间的关系(散点图、箱线图) | ☐ |
| 绘制相关性热力图 | ☐ |
| 多维度交叉分析(分面图、透视表) | ☐ |
| 写出 3-5 条有价值的发现 | ☐ |
| 给出数据驱动的建议 | ☐ |
一个新人可直接照抄的 EDA 检查表
Section titled “一个新人可直接照抄的 EDA 检查表”第一次做 EDA 项目时,最稳的检查表通常是:
- 数据概览有没有做清楚?
- 缺失值和异常值有没有交代?
- 单变量、双变量和分组分析有没有各做至少一轮?
- 每张关键图有没有一句明确结论?
- 最后有没有把发现翻译成业务建议?
如果这 5 件事都做到位,这个项目就已经不只是“画图练习”,而是一份真正像样的分析报告。
项目交付参考与讲解
- EDA 项目没有唯一数值答案。高质量提交应包含原始数据位置、数据字典、清洗日志、摘要统计、至少三张由问题驱动的图、结论和限制。
- 每张图都应回答一个命名问题,并能追溯到清洗后的数据集。如果某张图无法对应问题,就删除它或重写问题。
- 最终 README 要让别人能复现分析,并理解哪些处理是判断性决策。
版本路线建议
Section titled “版本路线建议”| 版本 | 目标 | 交付重点 |
|---|---|---|
| 基础版 | 跑通最小闭环 | 能输入、能处理、能输出,并保留一组示例 |
| 标准版 | 形成可展示项目 | 增加配置、日志、错误处理、README 和截图 |
| 挑战版 | 接近作品集质量 | 增加评估、对比实验、失败样本分析和下一步路线 |
建议先完成基础版,不要一开始就追求大而全。每提升一个版本,都要把“新增了什么能力、怎么验证、还有什么问题”写进 README。
学完这一页,至少保留这张证据卡:
- 分析目标
- 业务/数据问题和成功标准
- 数据证据
- 来源、清洗说明、特征和图表/表格输出
- 结果
- 洞察、指标、仪表板,或报告部分
- 失败检查
- 脏数据、偏置样本、错误聚合或 Notebook 无法复现
- 期望产出
- 可复现的分析文件夹,包含数据、图表和简短报告