3.3.5 数据清洗
- 掌握缺失值的检测、删除和填充策略
- 学会处理重复值
- 了解异常值检测方法
- 掌握数据类型转换和字符串处理
先建立一张地图
Section titled “先建立一张地图”数据清洗更适合按“先检查,再决定怎么处理”来理解:
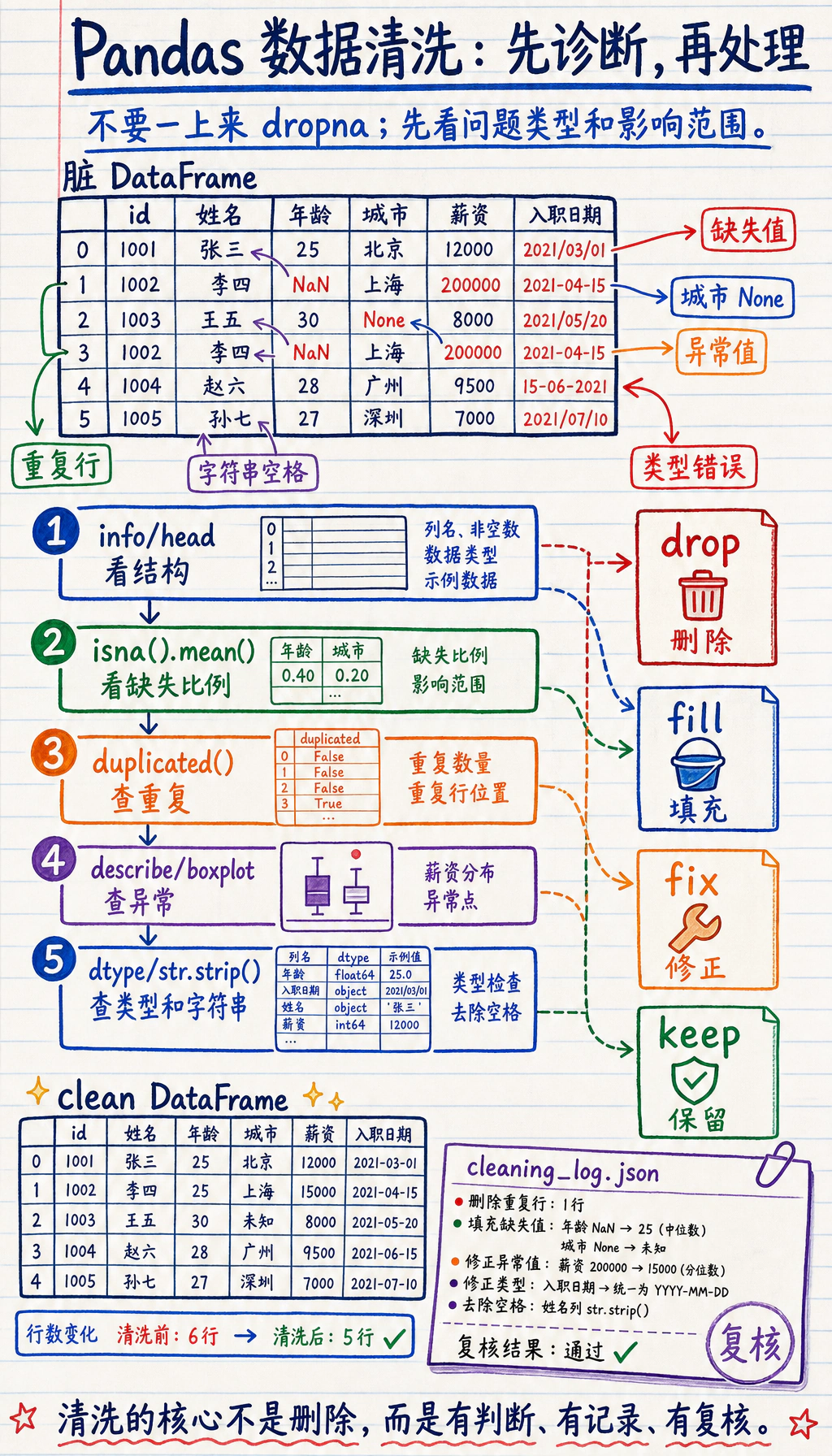
所以这节真正想解决的是:
- 真实数据最常见的问题有哪些
- 你第一次拿到脏数据时,最稳的排查顺序是什么
为什么需要数据清洗?
Section titled “为什么需要数据清洗?”真实世界的数据很脏——缺失值、重复行、格式不统一、异常值……如果不清洗就直接分析,结果一定不靠谱。
“数据科学家 80% 的时间花在数据清洗上,20% 花在抱怨数据清洗上。” —— 业界名言
flowchart LR A["原始数据<br/>(脏)"] --> B["数据清洗"] B --> C["干净数据"] C --> D["分析 / 建模"]
B --> B1["处理缺失值"] B --> B2["去除重复值"] B --> B3["处理异常值"] B --> B4["统一格式"]
style A fill:#f44336,color:#fff style C fill:#4caf50,color:#fff一个更适合新人的总类比
Section titled “一个更适合新人的总类比”你可以把数据清洗理解成:
- 做饭前的洗菜、择菜和备料
你不是为了“看起来更整齐”才做这些动作, 而是为了:
- 后面真正开始分析时,不会被坏掉、重复或格式混乱的数据带偏
创建含缺失值的数据
Section titled “创建含缺失值的数据”import pandas as pdimport numpy as np
df = pd.DataFrame({ "姓名": ["张三", "李四", "王五", "赵六", "钱七"], "年龄": [22, np.nan, 25, 28, np.nan], "城市": ["北京", "上海", None, "深圳", "杭州"], "薪资": [15000, 22000, np.nan, 35000, 12000]})print(df)# 检测每个位置是否缺失print(df.isna()) # True = 缺失(isnull() 也一样)print(df.notna()) # True = 非缺失
# 每列的缺失数量print(df.isna().sum())# 姓名 0# 年龄 2# 城市 1# 薪资 1
# 缺失比例print(df.isna().mean())# 年龄 0.4# 城市 0.2# 薪资 0.2
# 有缺失值的行print(df[df.isna().any(axis=1)])# 删除任何含缺失值的行df_cleaned = df.dropna()print(df_cleaned) # 只剩 2 行(张三、赵六)
# 删除全部为缺失值的行df.dropna(how="all")
# 只看特定列df.dropna(subset=["年龄"]) # 年龄缺失的行删除df.dropna(subset=["年龄", "薪资"]) # 年龄或薪资缺失的行删除
# 保留至少 N 个非缺失值的行df.dropna(thresh=3) # 至少 3 个列有值才保留# 用固定值填充df["城市"].fillna("未知")
# 用均值填充(数值列常用)df["年龄"].fillna(df["年龄"].mean())
# 用中位数填充df["薪资"].fillna(df["薪资"].median())
# 用前一个值填充(时间序列常用)df["年龄"].ffill() # forward fill
# 用后一个值填充df["年龄"].bfill() # backward fill
# 对不同列用不同策略df_filled = df.fillna({ "年龄": df["年龄"].median(), "城市": "未知", "薪资": 0})print(df_filled)缺失值处理策略
Section titled “缺失值处理策略”| 策略 | 适用场景 | 方法 |
|---|---|---|
| 删除行 | 缺失比例小(低于 5%)、数据量大 | dropna() |
| 均值/中位数填充 | 数值型、分布对称 | fillna(mean/median) |
| 众数填充 | 分类变量 | fillna(mode()[0]) |
| 前/后值填充 | 时间序列数据 | ffill() / bfill() |
| 固定值填充 | 业务逻辑明确 | fillna(0) 或 fillna("未知") |
| 插值 | 连续数据 | interpolate() |
第一次处理缺失值时,最稳的默认顺序
Section titled “第一次处理缺失值时,最稳的默认顺序”更稳的顺序通常是:
- 先统计缺失比例
- 再判断这列重不重要
- 缺得很少再考虑删行
- 缺得较多再考虑填充策略
这样会比一上来就直接 dropna() 更不容易把数据删坏。
df = pd.DataFrame({ "姓名": ["张三", "李四", "张三", "王五", "李四"], "部门": ["技术", "市场", "技术", "技术", "市场"], "薪资": [15000, 18000, 15000, 22000, 18000]})
# 检测重复行print(df.duplicated())# 0 False# 1 False# 2 True ← 和第 0 行完全相同# 3 False# 4 True ← 和第 1 行完全相同
# 重复行数量print(f"重复行数: {df.duplicated().sum()}") # 2
# 删除重复行df_unique = df.drop_duplicates()print(df_unique) # 3 行
# 按特定列判断重复df.drop_duplicates(subset=["姓名"]) # 同姓名只保留第一条df.drop_duplicates(subset=["姓名"], keep="last") # 保留最后一条重复值最容易被误解成什么?
Section titled “重复值最容易被误解成什么?”很多新人会以为“重复值 = 一定删掉”。 但更稳妥的想法是:
- 先确认它是不是真重复
- 还是业务上合理的多次记录
例如:
- 同一个用户多次下单,并不是脏数据
- 同一条订单被导入两次,才是真正要清理的重复
Z-score 方法
Section titled “Z-score 方法”rng = np.random.default_rng(seed=42)df = pd.DataFrame({ "薪资": np.concatenate([ rng.normal(20000, 5000, 97), # 正常数据 np.array([100000, 150000, 200000]) # 异常值 ])})
# 计算 Z-scorez_scores = (df["薪资"] - df["薪资"].mean()) / df["薪资"].std()
# |Z| > 3 视为异常outliers = df[z_scores.abs() > 3]print(f"检测到 {len(outliers)} 个异常值")print(outliers)
# 去除异常值df_clean = df[z_scores.abs() <= 3]IQR 方法(更稳健)
Section titled “IQR 方法(更稳健)”Q1 = df["薪资"].quantile(0.25)Q3 = df["薪资"].quantile(0.75)IQR = Q3 - Q1
lower = Q1 - 1.5 * IQRupper = Q3 + 1.5 * IQR
print(f"正常范围: [{lower:.0f}, {upper:.0f}]")
# 去除范围外的数据df_clean = df[(df["薪资"] >= lower) & (df["薪资"] <= upper)]
# 或者将异常值截断到边界df["薪资_clipped"] = df["薪资"].clip(lower, upper)一个很适合初学者先记的判断表
Section titled “一个很适合初学者先记的判断表”| 现象 | 更稳的第一反应 |
|---|---|
| 缺失值很多 | 先判断这列还能不能保留 |
| 数值特别离谱 | 先检查是不是录入错误 |
| 同一行出现多次 | 先确认是不是导入重复 |
| 一列明明是数字却是字符串 | 先做类型转换 |
这个表很适合新人,因为它会把“数据很脏”重新拆成几类可处理的问题。
数据类型转换
Section titled “数据类型转换”df = pd.DataFrame({ "ID": ["001", "002", "003"], "价格": ["12.5", "23.8", "15.0"], "数量": ["3", "5", "2"], "日期": ["2024-01-15", "2024-02-20", "2024-03-10"]})print(df.dtypes) # 全是 object(字符串)
# 转换数据类型df["价格"] = df["价格"].astype(float)df["数量"] = df["数量"].astype(int)df["日期"] = pd.to_datetime(df["日期"])print(df.dtypes)# ID object# 价格 float64# 数量 int64# 日期 datetime64[ns]
# 处理转换错误dirty = pd.Series(["10", "20", "abc", "40"])# dirty.astype(int) # ❌ 报错
# 用 to_numeric 优雅处理clean = pd.to_numeric(dirty, errors="coerce") # 无法转换的变成 NaNprint(clean)# 0 10.0# 1 20.0# 2 NaN# 3 40.0字符串处理(str 访问器)
Section titled “字符串处理(str 访问器)”Pandas 的 .str 访问器让你对整列字符串进行批量操作:
df = pd.DataFrame({ "姓名": [" 张三 ", "李四", " 王五 "], "手机": ["138-0000-1111", "139-2222-3333", "137-4444-5555"]})
# 去除空格df["姓名"] = df["姓名"].str.strip()
# 转小写df["邮箱"] = df["邮箱"].str.lower()
# 替换df["手机_clean"] = df["手机"].str.replace("-", "")
# 包含判断print(df["邮箱"].str.contains("email")) # 全是 True
# 提取df["手机前3位"] = df["手机"].str[:3]
# 分割df["邮箱用户名"] = df["邮箱"].str.split("@").str[0]
print(df)常用 str 方法
Section titled “常用 str 方法”| 方法 | 作用 | 示例 |
|---|---|---|
.str.strip() | 去除前后空格 | " hello " → "hello" |
.str.lower() | 转小写 | "ABC" → "abc" |
.str.upper() | 转大写 | "abc" → "ABC" |
.str.replace() | 替换 | "a-b".replace("-","") |
.str.contains() | 包含判断 | 返回布尔 Series |
.str.startswith() | 开头判断 | 返回布尔 Series |
.str.len() | 字符串长度 | "hello" → 5 |
.str.split() | 分割 | "a,b".split(",") |
.str.extract() | 正则提取 | 提取匹配的部分 |
实战:清洗一份脏数据
Section titled “实战:清洗一份脏数据”import pandas as pdimport numpy as np
# 创建一份"脏"数据dirty_data = pd.DataFrame({ "姓名": [" 张三", "李四 ", "王五", "张三", " 赵六", "钱七", "李四"], "年龄": [22, 28, np.nan, 22, "未知", 150, 28], # 有缺失、非数字、异常值 "城市": ["北京", "上海 ", None, "北京", " 广州", "深圳", "上海"], "薪资": [15000, 22000, 18000, 15000, 20000, -5000, 22000] # 有负数})
print("=== 原始数据 ===")print(dirty_data)print(f"\n行数: {len(dirty_data)}")
# 第1步:去除字符串空格dirty_data["姓名"] = dirty_data["姓名"].str.strip()dirty_data["城市"] = dirty_data["城市"].str.strip()
# 第2步:转换数据类型dirty_data["年龄"] = pd.to_numeric(dirty_data["年龄"], errors="coerce")
# 第3步:处理异常值dirty_data.loc[dirty_data["年龄"] > 120, "年龄"] = np.nan # 年龄>120 不合理dirty_data.loc[dirty_data["薪资"] < 0, "薪资"] = np.nan # 薪资<0 不合理
# 第4步:填充缺失值dirty_data["年龄"] = dirty_data["年龄"].fillna(dirty_data["年龄"].median())dirty_data["城市"] = dirty_data["城市"].fillna("未知")dirty_data["薪资"] = dirty_data["薪资"].fillna(dirty_data["薪资"].median())
# 第5步:删除重复行dirty_data = dirty_data.drop_duplicates()
print("\n=== 清洗后 ===")print(dirty_data)print(f"\n行数: {len(dirty_data)}")这个小实战最值得先学到什么?
Section titled “这个小实战最值得先学到什么?”最值得先学到的不是某一个函数名, 而是清洗动作通常有一条比较稳的顺序:
- 先统一格式
- 再转类型
- 再处理异常
- 最后再补缺失和去重
顺序理清后,很多脏数据问题都会好拆很多。
一个新人可直接照抄的数据清洗检查表
Section titled “一个新人可直接照抄的数据清洗检查表”第一次做数据清洗时,最稳的检查表通常是:
- 每列类型对不对?
- 缺失值比例高不高?
- 有没有明显异常值?
- 有没有重复记录?
- 清洗规则能不能解释给别人听?
最后这一条特别重要,因为清洗本质上也是决策。 如果你自己都说不清为什么这样删、这样补,后面的分析就很难让人信服。
学完这一页,至少保留这张证据卡:
- 数据框状态
- 列、数据类型、行数、缺失值和样本行
- 操作
- 读/写、select/filter、清洗、转换、groupby、merge,或时间序列步骤
- 输出
- 结果表、保存的文件、聚合、连接结果,或时间索引视图
- 失败检查
- dtype 不匹配、缺失数据、重复键、链式赋值或时间频率错误
- 期望产出
- 前后对比表格样本,以及转换原因
| 类型 | 检测 | 处理方法 |
|---|---|---|
| 缺失值 | isna(), info() | dropna(), fillna() |
| 重复值 | duplicated() | drop_duplicates() |
| 异常值 | Z-score, IQR | clip(), 删除, 替换为 NaN |
| 类型错误 | dtypes | astype(), pd.to_numeric() |
| 字符串脏数据 | 目测, str.contains() | str.strip(), str.replace() |
练习 1:缺失值处理
Section titled “练习 1:缺失值处理”# 创建一个包含缺失值的 DataFrame(至少 20 行 5 列)# 1. 统计每列的缺失比例# 2. 对数值列用中位数填充# 3. 对类别列用众数填充# 4. 删除缺失值超过 50% 的列(如果有的话)练习 2:完整清洗流程
Section titled “练习 2:完整清洗流程”# 创建一份包含各种问题的数据,然后完成完整的清洗流程:# 字符串空格 → 类型转换 → 异常值处理 → 缺失值填充 → 去重参考实现与讲解
- 先用
isna().sum()和isna().mean()做缺失值报告。逐列决定是删除、用中位数或众数填充,还是把缺失本身当成有意义的信号保留。 - 数值列在可能有异常值时通常用中位数;类别列通常用众数或显式的
Unknown。缺失率很高的列如果要继续使用,必须写清理由。 - 保留清洗日志:原始行数、删除行数、填充值、重复行规则和异常值规则。没有这份日志,清洗后的数据很难被信任。