A.9 学习资源速查表
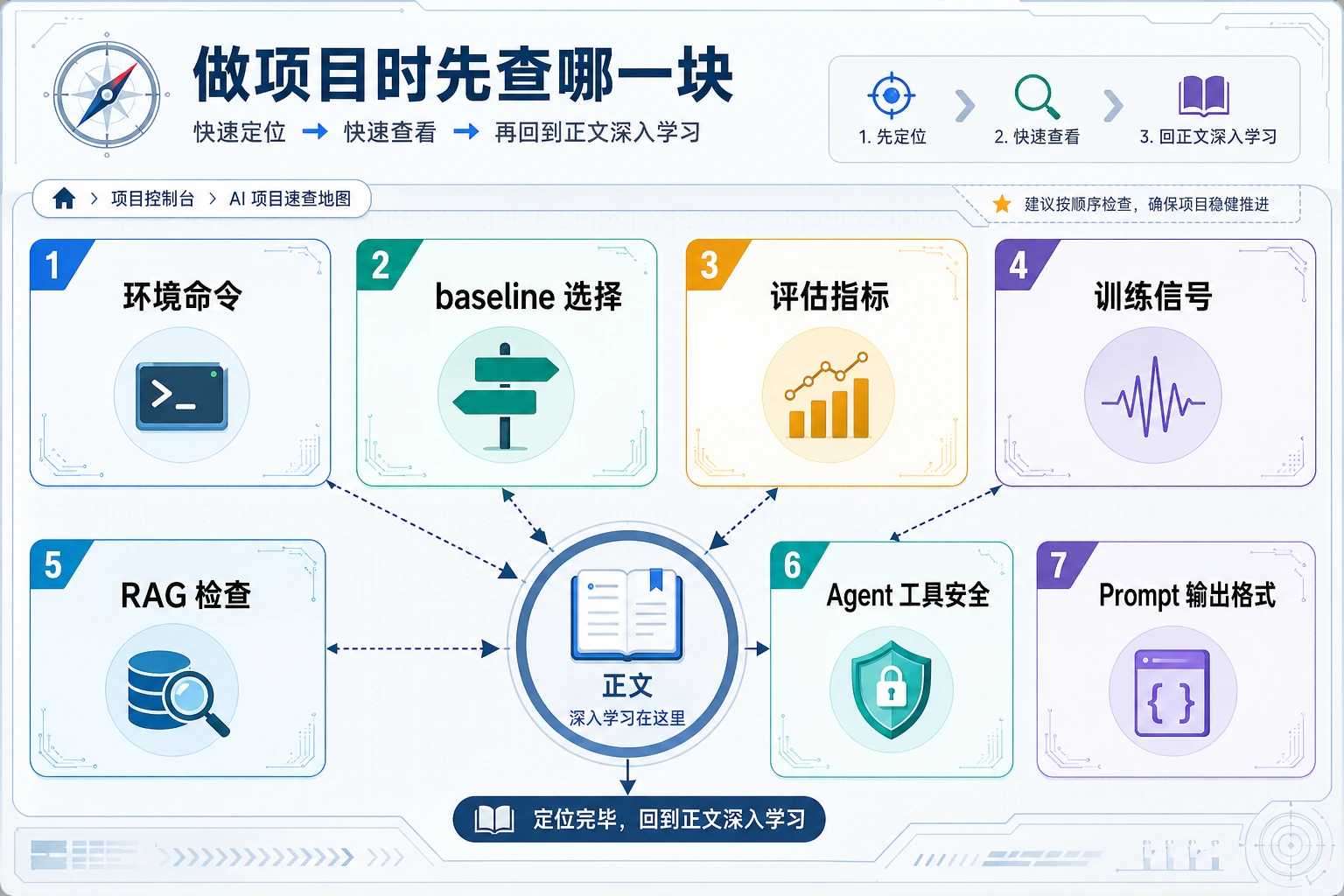
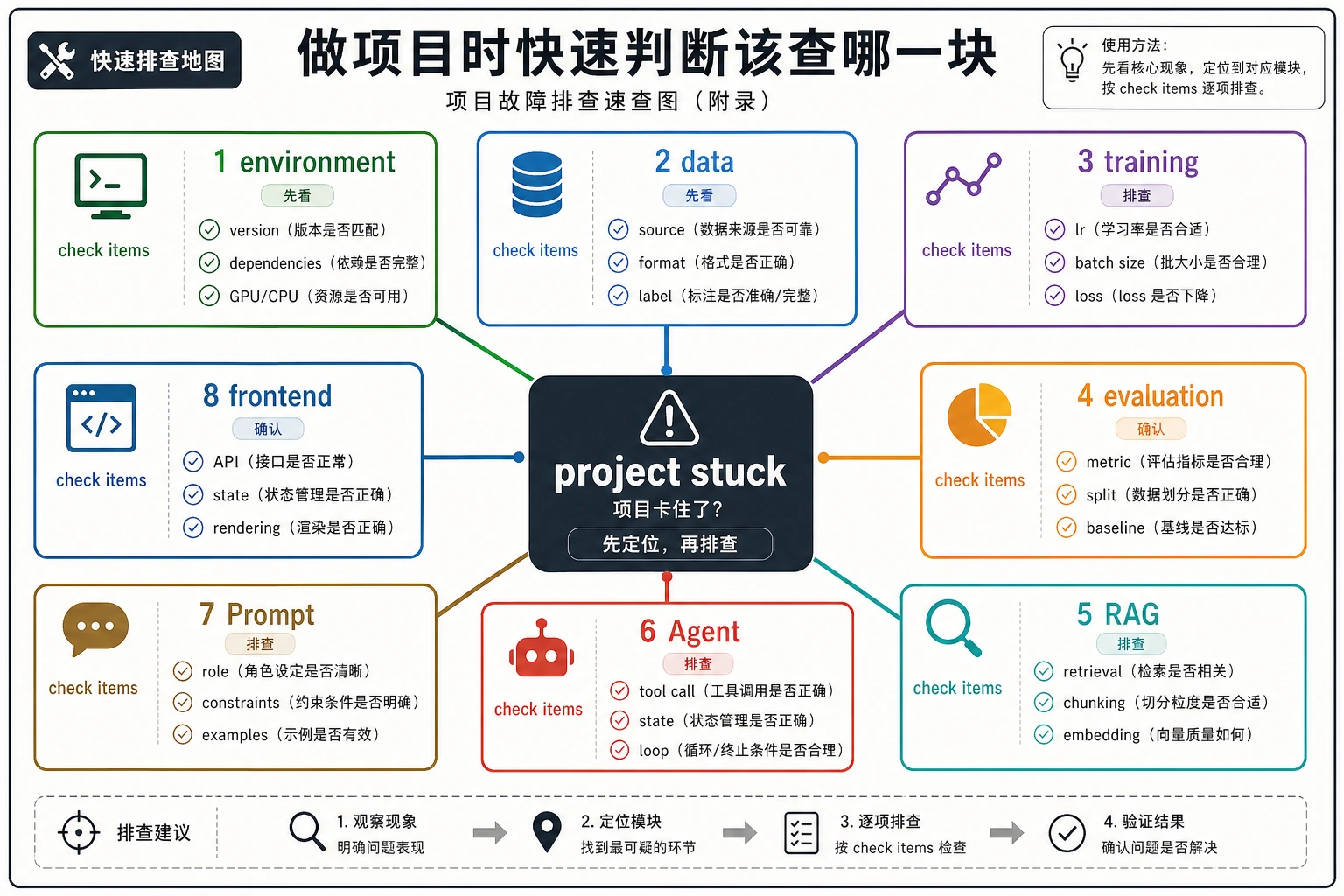
先用第一张图定位项目阶段,再用第二张图按错误类型回到对应检查项。
做项目时查这一页,不需要从头读到尾。
python --versionwhich pythonpip --versionpip listpwdls文档站点:
npm installnpm run startnpm run buildNVIDIA GPU:
nvidia-smi| 任务 | 优先尝试 |
|---|---|
| 表格分类/回归 | 线性模型或树模型 |
| 文本分类 | TF-IDF + LogisticRegression |
| 图像分类 | 迁移学习 |
| 命名实体识别 | 规则/词典 baseline,再上序列模型 |
| 文档问答 | 关键词/BM25 检索,再上 RAG |
| Agent 工具调用 | 单 Agent + 一个安全工具 |
| 任务 | 先看哪些指标 |
|---|---|
| 类别均衡分类 | Accuracy、F1 |
| 类别不均衡分类 | Precision、Recall、F1、混淆矩阵 |
| 回归 | MAE、RMSE、残差复盘 |
| 检索 / RAG | Hit@K、MRR、引用准确率、人工复查 |
| Agent | 成功率、工具错误、成本、trace 复盘 |
| 现象 | 先检查 |
|---|---|
| loss 不下降 | 标签、loss 函数、学习率、输入格式 |
| 训练好、验证差 | 过拟合、数据泄漏、分布不一致 |
| accuracy 不变 | 特征弱、标签错、模型没学到 |
| GPU OOM | batch size、输入长度、模型大小 |
| 结果不稳定 | 随机种子、数据太少、划分不一致 |
RAG 检查表
Section titled “RAG 检查表”- 文档是否正确切分?
- 检索能否召回正确 chunk?
- 答案是否包含来源?
- 答案是否真的使用了检索内容?
- 是否有权限过滤和无法回答策略?
Agent 检查表
Section titled “Agent 检查表”- 从单轮问答开始。
- 加一个工具。
- 加严格参数 schema。
- 加日志和 trace 回放。
- 加权限边界和停止条件。
Prompt 模板
Section titled “Prompt 模板”你是 ____。你的任务是 ____。输入:输出格式:约束:如果信息不足,请明确说明。最小训练循环
Section titled “最小训练循环”data = [(1.0, 2.0), (2.0, 4.0), (3.0, 6.0)]w = 0.0lr = 0.01
for epoch in range(3): total_loss = 0.0 for x, y in data: pred = w * x error = pred - y total_loss += error * error grad = 2 * error * x w -= lr * grad print(f"epoch={epoch} w={w:.3f} loss={total_loss:.3f}")预期输出:
epoch=0 w=0.521 loss=48.630epoch=1 w=0.907 loss=26.580epoch=2 w=1.192 loss=14.528按这个顺序读:数据 -> 预测 -> 损失 -> 梯度 -> 参数更新。
学完这一页,至少保留这张证据卡:
- 学习差距
- 需要加强的概念、代码技能、项目技能、论文或部署技能
- 资源选择
- 一个主要资源,以及它为何适合当前瓶颈
- 时间盒
- 在回到项目之前使用它的时长
- 风险检查
- 收集资源而不是产出证据
- 期望产出
- 一份简短的资源计划,附带阅读后要产出的一个成果