9.9.4 持久化与恢复
- 理解“持久化”和“恢复”在 Agent 任务中的意义
- 学会区分状态快照和事件日志两类数据
- 通过可运行示例实现最小 checkpoint + 恢复流程
- 理解幂等在恢复链路里为什么重要
为什么 Agent 特别需要可恢复能力?
Section titled “为什么 Agent 特别需要可恢复能力?”因为很多任务不是瞬时完成的
Section titled “因为很多任务不是瞬时完成的”例如:
- 研究报告生成
- 多工具审批流程
- 多轮后台爬取与整理
这类任务经常会跨越:
- 多次调用
- 多个步骤
- 更长时间窗口
没有恢复能力会带来什么问题?
Section titled “没有恢复能力会带来什么问题?”- 任务一中断就全部重来
- 已执行动作可能被重复执行
- 用户无法知道当前进度
没有持久化的 Agent 像“断电就失忆”的工作站。 真正能上生产的系统,更像带自动保存和恢复点的 IDE。
持久化到底在存什么?
Section titled “持久化到底在存什么?”最核心的是任务状态
Section titled “最核心的是任务状态”例如:
- 当前执行到哪一步
- 哪些步骤已完成
- 中间结果是什么
其次是事件日志
Section titled “其次是事件日志”事件日志回答的是:
- 之前到底发生过什么
例如:
- 调用了哪个工具
- 收到了什么返回
- 哪一步失败了
快照和日志的区别
Section titled “快照和日志的区别”可以先这样记:
checkpoint / snapshot:当前状态的压缩截面event log:系统一路发生过的事件流水
真实工程里两者常常配合使用。
先跑一个最小恢复工作流
Section titled “先跑一个最小恢复工作流”下面这个示例会模拟一个三步任务:
- 读取资料
- 生成摘要
- 写入报告
系统会在每步后写 checkpoint。 如果在第 2 步故障,就从上一次 checkpoint 继续。
import copy
TASK_PLAN = ["load_data", "summarize", "write_report"]
def execute_step(step, state): if step == "load_data": state["data"] = ["退款规则", "发票规则", "地址修改规则"] elif step == "summarize": state["summary"] = ";".join(state["data"]) elif step == "write_report": state["report"] = f"最终报告: {state['summary']}" return state
class WorkflowRunner: def __init__(self): self.event_log = [] self.last_checkpoint = None
def checkpoint(self, state): self.last_checkpoint = copy.deepcopy(state)
def log_event(self, event_type, payload): self.event_log.append({"type": event_type, "payload": copy.deepcopy(payload)})
def run(self, fail_on_step=None): state = self.last_checkpoint or {"current_index": 0, "completed_steps": []}
while state["current_index"] < len(TASK_PLAN): step = TASK_PLAN[state["current_index"]] self.log_event("step_started", {"step": step, "state": state})
if step == fail_on_step: self.log_event("step_failed", {"step": step}) raise RuntimeError(f"crash_on_{step}")
state = execute_step(step, state) state["completed_steps"].append(step) state["current_index"] += 1
self.checkpoint(state) self.log_event("step_completed", {"step": step, "state": state})
return state
runner = WorkflowRunner()
try: runner.run(fail_on_step="summarize")except RuntimeError as e: print("first run crashed:", e)
print("checkpoint after crash:", { "current_index": runner.last_checkpoint["current_index"], "completed_steps": runner.last_checkpoint["completed_steps"],})
final_state = runner.run()print("\nrestored final state:")print({ "completed_steps": final_state["completed_steps"], "report": final_state["report"],})
print("\nevent types:")print([event["type"] for event in runner.event_log])预期输出:
first run crashed: crash_on_summarizecheckpoint after crash: {'current_index': 1, 'completed_steps': ['load_data']}
restored final state:{'completed_steps': ['load_data', 'summarize', 'write_report'], 'report': '最终报告: 退款规则;发票规则;地址修改规则'}
event types:['step_started', 'step_completed', 'step_started', 'step_failed', 'step_started', 'step_completed', 'step_started', 'step_completed']
这个示例最值得学什么?
Section titled “这个示例最值得学什么?”它把恢复链路里最关键的三件事串起来了:
- 每步完成后写 checkpoint
- 出错时保留 event log
- 重启后从上一次 checkpoint 接着跑
为什么 checkpoint 不能只在任务结束时写?
Section titled “为什么 checkpoint 不能只在任务结束时写?”因为那样一旦任务中途崩溃, 你仍然什么都恢复不了。
所以长任务里更实用的是:
- 步骤级 checkpoint
为什么 event log 很重要?
Section titled “为什么 event log 很重要?”checkpoint 只能告诉你“现在是什么状态”, 但它不能完整解释:
- 为什么会变成这个状态
- 中间失败发生在哪
日志让你能做复盘和调试。
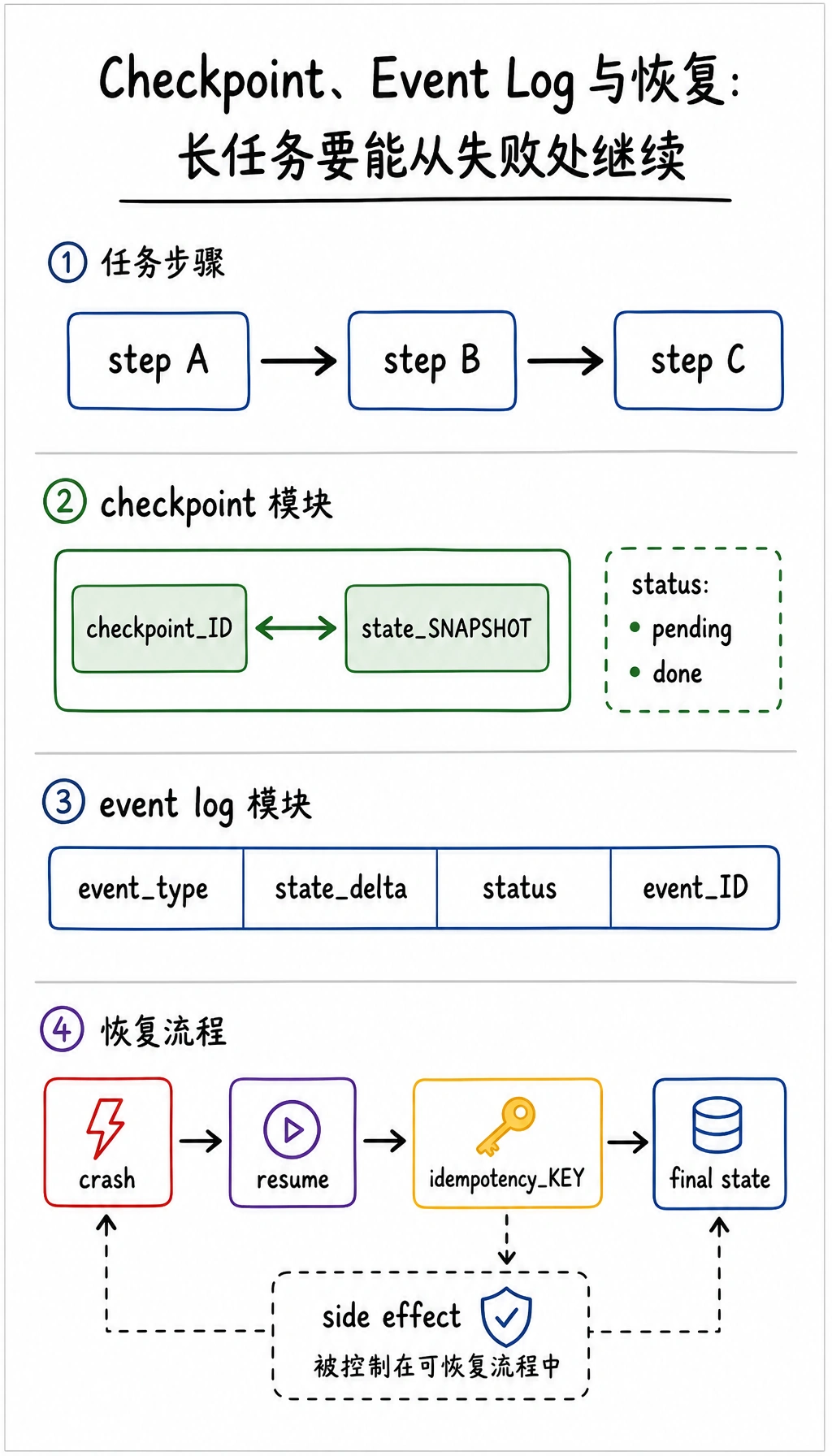
幂等为什么是恢复链路的核心?
Section titled “幂等为什么是恢复链路的核心?”幂等可以粗略理解成:
- 同一个动作重复执行多次,结果仍然一致
为什么恢复时特别需要它
Section titled “为什么恢复时特别需要它”如果系统在“写报告”之前崩了,你重启后可能不确定:
- 这一步到底做了没
如果动作不是幂等的,就会带来:
- 重复写入
- 重复扣费
- 重复发消息
一个简化例子
Section titled “一个简化例子”processed = set()
def send_email_once(task_id, address): if task_id in processed: return {"ok": True, "status": "skipped_duplicate"} processed.add(task_id) return {"ok": True, "status": f"sent_to:{address}"}
预期输出:
{'ok': True, 'status': 'sent_to:[email protected]'}{'ok': True, 'status': 'skipped_duplicate'}这就是最简单的幂等保护思路。
恢复设计时最容易漏掉什么?
Section titled “恢复设计时最容易漏掉什么?”状态只存“结果”,不存“进度”
Section titled “状态只存“结果”,不存“进度””如果你只存 summary,不存:
- 当前到第几步
恢复时仍然很难继续。
只存 checkpoint,不存日志
Section titled “只存 checkpoint,不存日志”这样能恢复,但不容易排查为什么失败。
外部副作用没有幂等键
Section titled “外部副作用没有幂等键”这会让恢复变得危险, 因为系统不确定重放是否会制造重复副作用。
真实系统里通常怎么做?
Section titled “真实系统里通常怎么做?”保存:
- 任务 id
- 当前步骤
- 当前状态快照
- 更新时间
保存:
- 事件类型
- 时间
- 输入输出摘要
- 错误信息
负责:
- 重启时扫描未完成任务
- 载入最近 checkpoint
- 从安全位置继续
误区一:只要有数据库就是“可恢复”
Section titled “误区一:只要有数据库就是“可恢复””不对。 关键是你有没有保存:
- 足够恢复的信息
误区二:恢复就是“再跑一遍”
Section titled “误区二:恢复就是“再跑一遍””再跑一遍往往会带来重复副作用。 恢复不是重做,而是有状态继续。
误区三:只有超长任务才需要恢复
Section titled “误区三:只有超长任务才需要恢复”只要任务包含外部副作用或多步执行, 恢复能力就很重要。
学完这一页,至少保留这张证据卡:
- 运行时
- 队列、worker、状态存储、工具服务,以及模型端点
- 持久化
- 检查点、事件日志、记忆存储和恢复路径
- 运维信号
- 延迟、成本、错误率、trace 覆盖率和饱和度
- 失败检查
- 运行卡住、重复动作、部分失败或成本失控
- 恢复动作
- 继续、回滚、取消、人工接管,或优雅降级
这节最重要的是建立一个生产级判断:
Agent 的持久化与恢复,不是简单把结果写盘,而是围绕 checkpoint、事件日志和幂等机制,让任务在失败后还能安全继续。
只要这条链路设计清楚, 系统就从“偶尔能跑”的演示,走向“失败后仍能继续”的生产系统。
- 给示例增加一个
retry_count字段,记录每步重试次数。 - 把
write_report改成带外部副作用的动作,再思考幂等该怎么做。 - 为什么说 checkpoint 和 event log 在恢复里缺一不可?
- 如果任务特别长,你会选择每步 checkpoint,还是每几步 checkpoint?为什么?
参考实现与讲解
retry_count应按 step 记录,而不只按整次 run 记录。这样才能看出哪一步不稳定,也能避免 retry storm 被一个最终状态掩盖。- 如果
write_report有外部副作用,就要用稳定 operation id、存在性检查、去重记录,以及“外部写入是否已成功”的状态来实现幂等。 - checkpoint 给你最近可恢复状态;event log 解释系统如何走到这个状态。恢复既需要快照,也需要决策和副作用历史。
- 长任务适合在重要、不可逆或昂贵步骤后 checkpoint,低风险步骤可以每隔几步一次。每步都 checkpoint 最安全,但会增加存储和延迟开销。