3.2.3 数组索引与切片
- 掌握一维和多维数组的基本索引与切片
- 学会使用布尔索引进行条件筛选
- 了解花式索引(Fancy Indexing)
- 理解视图(View)与拷贝(Copy)的区别
一维数组的索引与切片
Section titled “一维数组的索引与切片”一维数组的索引和 Python 列表基本一致:
import numpy as np
arr = np.array([10, 20, 30, 40, 50, 60, 70, 80])
# ===== 基本索引 =====print(arr[0]) # 10 第一个元素print(arr[3]) # 40 第四个元素print(arr[-1]) # 80 最后一个元素print(arr[-2]) # 70 倒数第二个
# ===== 切片 [start:stop:step] =====print(arr[2:5]) # [30 40 50] 索引 2 到 4print(arr[:3]) # [10 20 30] 前 3 个print(arr[5:]) # [60 70 80] 从索引 5 到末尾print(arr[::2]) # [10 30 50 70] 每隔一个取一个print(arr[::-1]) # [80 70 60 50 40 30 20 10] 反转二维数组的索引与切片
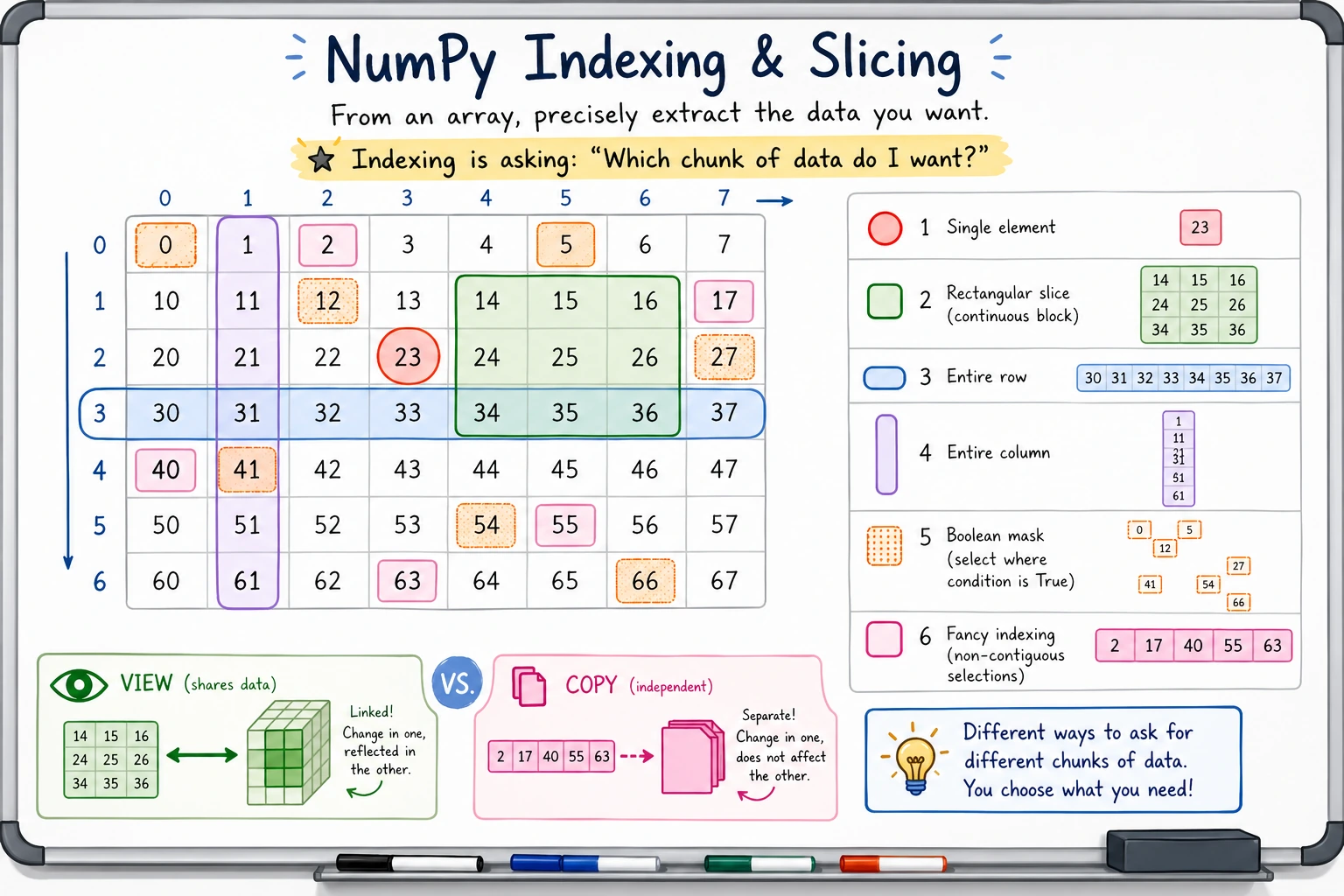
Section titled “二维数组的索引与切片”二维数组使用 [行, 列] 的方式访问:
matrix = np.array([ [1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12], [13, 14, 15, 16]])访问单个元素
Section titled “访问单个元素”print(matrix[0, 0]) # 1 第 0 行第 0 列print(matrix[1, 2]) # 7 第 1 行第 2 列print(matrix[-1, -1]) # 16 最后一行最后一列访问整行/整列
Section titled “访问整行/整列”print(matrix[0]) # [1 2 3 4] 第 0 行(整行)print(matrix[0, :]) # [1 2 3 4] 同上,更明确的写法
print(matrix[:, 0]) # [ 1 5 9 13] 第 0 列(整列)print(matrix[:, -1]) # [ 4 8 12 16] 最后一列# 取前 2 行、前 3 列sub = matrix[:2, :3]print(sub)# [[1 2 3]# [5 6 7]]
# 取第 1~2 行、第 2~3 列sub2 = matrix[1:3, 2:4]print(sub2)# [[ 7 8]# [11 12]]
# 每隔一行取(第 0、2 行)sub3 = matrix[::2]print(sub3)# [[ 1 2 3 4]# [ 9 10 11 12]]图解二维索引
Section titled “图解二维索引”| 表达式 | 选中了什么 | 结果 |
|---|---|---|
matrix[1, 2] | 第 1 行、第 2 列 | 7 |
matrix[:2, :3] | 前 2 行、前 3 列 | [[1,2,3], [5,6,7]] |
matrix[:, 1] | 所有行、第 1 列 | [2, 6, 10, 14] |
布尔索引:条件筛选
Section titled “布尔索引:条件筛选”这是 NumPy 最强大的功能之一——用条件表达式直接筛选数据!
arr = np.array([15, 23, 8, 42, 31, 5, 19, 27])
# 第一步:条件表达式生成布尔数组mask = arr > 20print(mask) # [False True False True True False False True]
# 第二步:用布尔数组作为索引,筛选出 True 对应的元素result = arr[mask]print(result) # [23 42 31 27]
# 通常合并成一行print(arr[arr > 20]) # [23 42 31 27]常用条件筛选
Section titled “常用条件筛选”scores = np.array([85, 92, 78, 65, 95, 43, 88, 72, 55, 90])
# 及格成绩(>= 60)print(scores[scores >= 60]) # [85 92 78 65 95 88 72 90]
# 优秀成绩(>= 90)print(scores[scores >= 90]) # [92 95 90]
# 不及格成绩(< 60)print(scores[scores < 60]) # [43 55]
# 60~80 之间的成绩(多条件用 & 连接,每个条件加括号)print(scores[(scores >= 60) & (scores <= 80)]) # [78 65 72]
# 低于 60 或高于 90 的成绩(多条件用 | 连接)print(scores[(scores < 60) | (scores > 90)]) # [92 95 43 55]
# 取反(~)print(scores[~(scores >= 60)]) # [43 55] 等价于 scores[scores < 60]布尔索引在二维数组中的应用
Section titled “布尔索引在二维数组中的应用”matrix = np.array([ [85, 92, 78], [65, 95, 43], [88, 72, 90]])
# 找出所有大于 80 的成绩print(matrix[matrix > 80]) # [85 92 95 88 90]# 注意:结果变成了一维数组!
# 把不及格的成绩改成 60(条件赋值)matrix[matrix < 60] = 60print(matrix)# [[85 92 78]# [65 95 60] ← 43 被改成了 60# [88 72 90]]花式索引(Fancy Indexing)
Section titled “花式索引(Fancy Indexing)”花式索引允许你用整数数组作为索引,一次取出多个指定位置的元素:
一维花式索引
Section titled “一维花式索引”arr = np.array([10, 20, 30, 40, 50, 60, 70])
# 取出索引 1、3、5 的元素print(arr[[1, 3, 5]]) # [20 40 60]
# 可以重复取print(arr[[0, 0, 2, 2]]) # [10 10 30 30]
# 可以用任意顺序print(arr[[6, 4, 2, 0]]) # [70 50 30 10]二维花式索引
Section titled “二维花式索引”matrix = np.array([ [1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]])
# 取第 0 行和第 2 行print(matrix[[0, 2]])# [[ 1 2 3 4]# [ 9 10 11 12]]
# 取特定位置:(0,1), (1,2), (2,3) 三个元素rows = [0, 1, 2]cols = [1, 2, 3]print(matrix[rows, cols]) # [ 2 7 12]视图(View)vs 拷贝(Copy)
Section titled “视图(View)vs 拷贝(Copy)”
这是新手容易踩的坑——NumPy 切片返回的是视图,不是副本!
视图:修改会影响原数组
Section titled “视图:修改会影响原数组”arr = np.array([1, 2, 3, 4, 5])
# 切片是视图sub = arr[1:4]print(sub) # [2 3 4]
# 修改 sub 会影响 arr!sub[0] = 99print(sub) # [99 3 4]print(arr) # [ 1 99 3 4 5] ← 原数组也变了!拷贝:互不影响
Section titled “拷贝:互不影响”arr = np.array([1, 2, 3, 4, 5])
# 使用 copy() 创建独立副本sub = arr[1:4].copy()print(sub) # [2 3 4]
# 修改 sub 不会影响 arrsub[0] = 99print(sub) # [99 3 4]print(arr) # [1 2 3 4 5] ← 原数组不受影响什么时候是视图?什么时候是拷贝?
Section titled “什么时候是视图?什么时候是拷贝?”| 操作 | 返回类型 | 示例 |
|---|---|---|
| 切片 | 视图 | arr[2:5] |
| 布尔索引 | 拷贝 | arr[arr > 3] |
| 花式索引 | 拷贝 | arr[[1, 3, 5]] |
.copy() | 拷贝 | arr[2:5].copy() |
.reshape() | 视图(通常) | arr.reshape(2, 3) |
实战示例:用索引分析数据
Section titled “实战示例:用索引分析数据”回到 Titanic 的场景,用 NumPy 索引来分析数据:
import numpy as np
# 模拟 10 位乘客的数据ages = np.array([22, 38, 26, 35, 35, np.nan, 54, 2, 27, 14])fares = np.array([7.25, 71.28, 7.92, 53.10, 8.05, 8.46, 51.86, 21.08, 11.13, 30.07])survived = np.array([0, 1, 1, 1, 0, 0, 0, 0, 1, 1])
# 找出幸存者的平均票价survivor_fares = fares[survived == 1]print(f"幸存者平均票价: ${np.mean(survivor_fares):.2f}")
# 找出年龄大于 30 的乘客票价(需要排除 NaN)valid_mask = ~np.isnan(ages) # 排除 NaNage_mask = ages > 30combined_mask = valid_mask & age_maskprint(f"30 岁以上乘客票价: {fares[combined_mask]}")
# 找出票价最高的 3 位乘客的索引top3_indices = np.argsort(fares)[-3:][::-1] # 排序后取最后 3 个,反转print(f"票价 Top 3 的索引: {top3_indices}")print(f"对应票价: {fares[top3_indices]}")学完这一页,至少保留这张证据卡:
- 数组状态
- 操作前的形状、dtype、轴和样本值
- 操作
- 索引、切片、广播、reshape、线性代数,或随机/统计函数
- 输出
- 结果数组形状、值,或统计量
- 失败检查
- 轴混淆、视图/副本陷阱、广播不匹配或形状错误
- 期望产出
- 打印的形状和值,便于检查数组运算
| 索引方式 | 语法 | 返回类型 | 适用场景 |
|---|---|---|---|
| 基本索引 | arr[i], arr[i, j] | 元素值 | 获取单个元素 |
| 切片 | arr[start:stop:step] | 视图 | 获取连续区域 |
| 布尔索引 | arr[arr > 5] | 拷贝 | 条件筛选 |
| 花式索引 | arr[[1, 3, 5]] | 拷贝 | 取不连续位置 |
练习 1:基本切片
Section titled “练习 1:基本切片”arr = np.arange(1, 21) # [1, 2, 3, ..., 20]
# 1. 取出前 5 个元素# 2. 取出所有奇数位置的元素(索引 1, 3, 5, ...)# 3. 取出最后 3 个元素# 4. 反转数组练习 2:二维切片
Section titled “练习 2:二维切片”matrix = np.arange(1, 26).reshape(5, 5)print(matrix)# [[ 1 2 3 4 5]# [ 6 7 8 9 10]# [11 12 13 14 15]# [16 17 18 19 20]# [21 22 23 24 25]]
# 1. 取出中间 3×3 的子矩阵# 2. 取出第 2 列的所有元素# 3. 取出对角线元素 [1, 7, 13, 19, 25](提示:用花式索引)练习 3:布尔索引实战
Section titled “练习 3:布尔索引实战”# 某班 20 位学生的数学成绩math_scores = np.array([ 78, 92, 65, 88, 45, 95, 72, 81, 56, 90, 83, 67, 94, 73, 85, 60, 98, 77, 69, 87])
# 1. 找出所有不及格(< 60)的成绩# 2. 找出 80~90 之间(含)的成绩# 3. 计算及格学生的平均分# 4. 把所有不及格的成绩改成 60# 5. 计算修改后的平均分参考实现与讲解
- 常见切片答案是:前五个值用
arr[:5],按“一位计数”的偶数位置用arr[1::2],后三个值用arr[-3:],倒序用arr[::-1]。 - 对 5x5 矩阵,
matrix[1:4, 1:4]选中间 3x3 区域,matrix[:, 1]选第二列,matrix[np.arange(5), np.arange(5)]选主对角线。 - 成绩筛选时保留原始数据不变,再复制一份数组去把不及格分数替换为
60。这样不会把原始证据覆盖掉。