8.1.1 RAG 路线图:文档、检索、回答
RAG 解决的是一个很实际的问题:模型不知道所有最新、私有或带来源要求的事实,所以应用必须先检索证据,再让模型回答。
先看 RAG 流水线
Section titled “先看 RAG 流水线”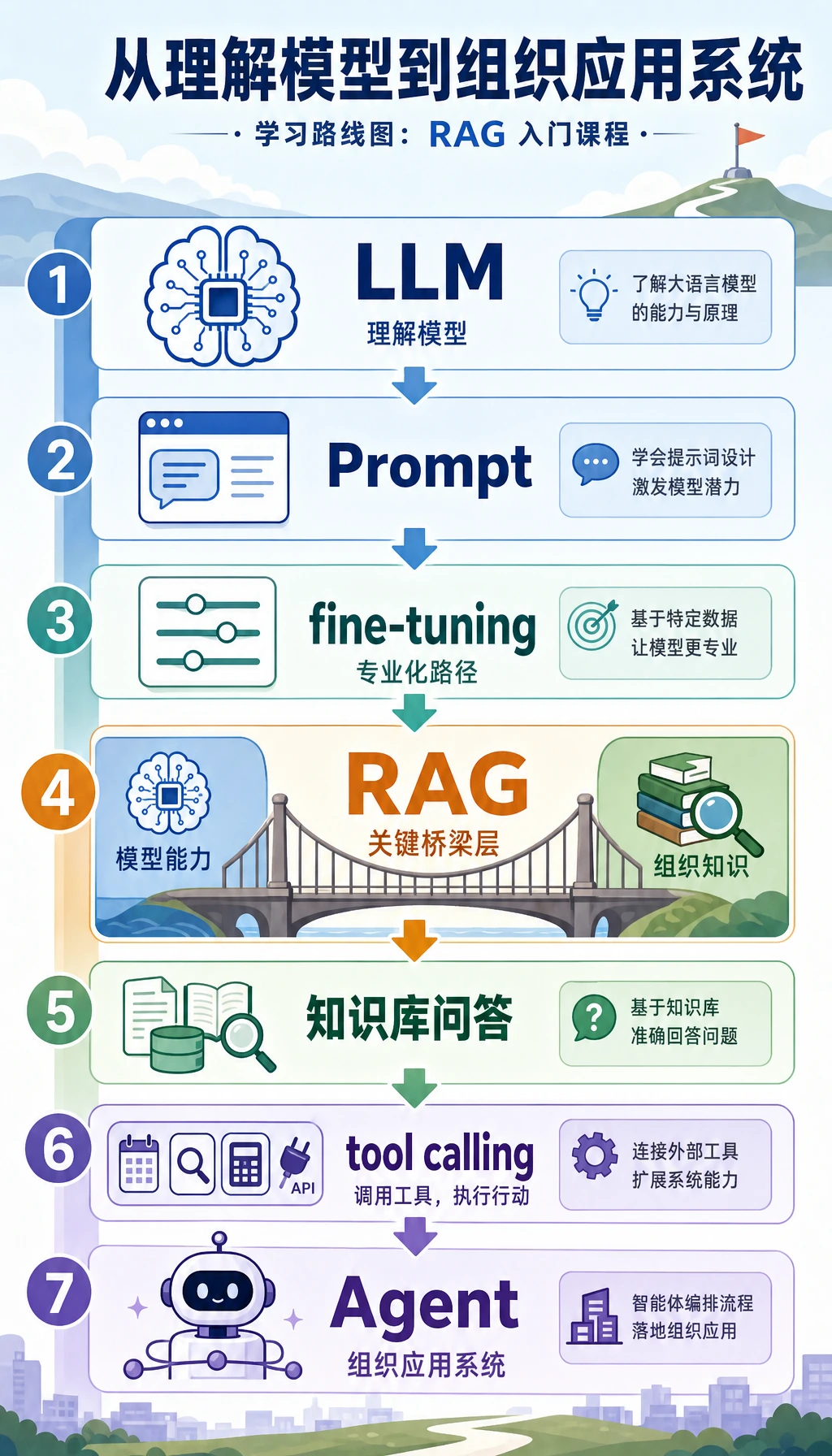
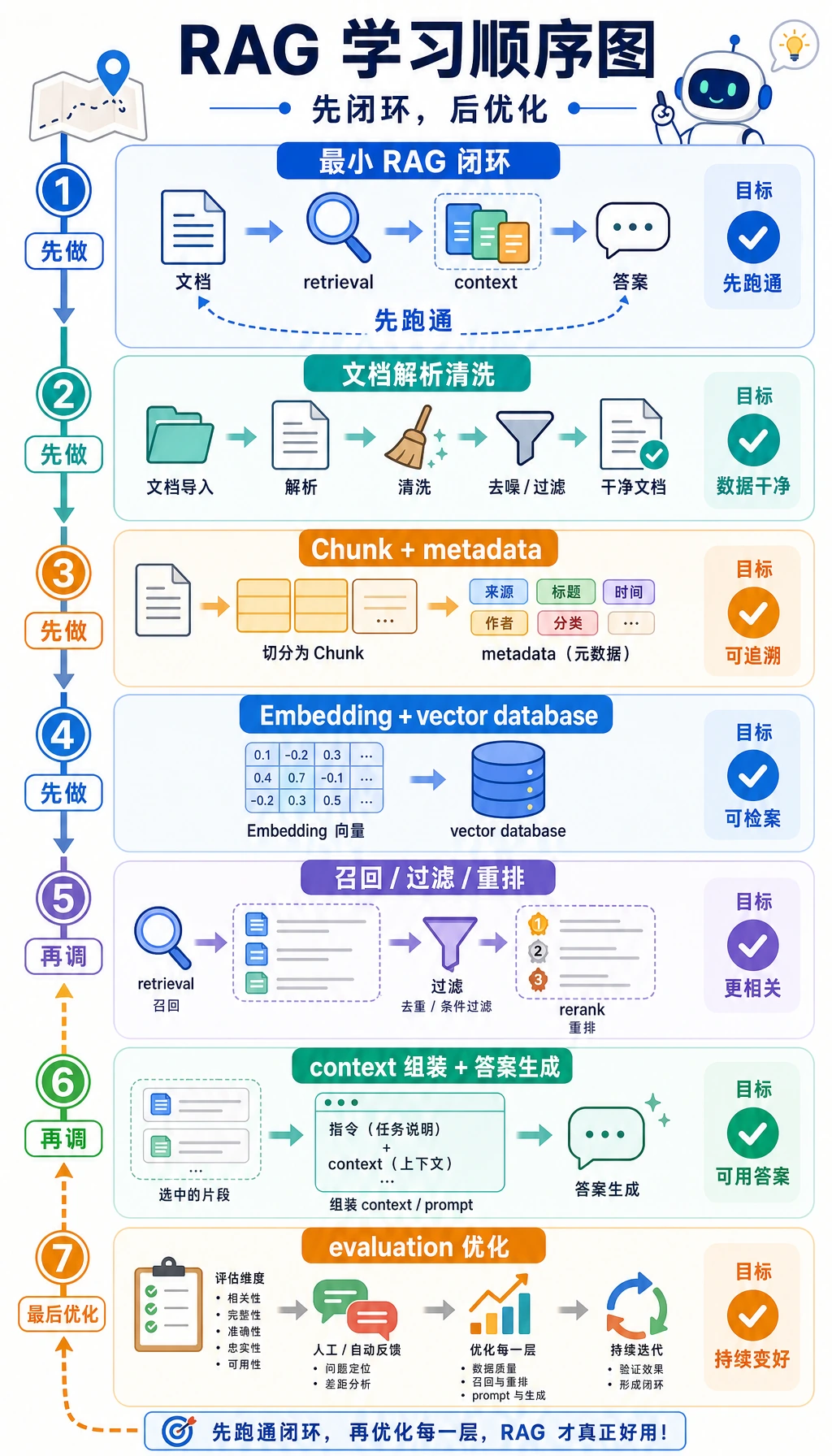

核心闭环是:加载文档、切分 chunk、添加 metadata、embedding、检索、重排序、组装上下文、回答、引用来源、评估。
跑一个极小检索检查
Section titled “跑一个极小检索检查”这还不是向量数据库,而是检索习惯的离线迷你版:给分块打分,打印来源,确认证据是否匹配问题。
chunks = [ {"source": "rag.md", "text": "RAG retrieves source chunks before the model answers."}, {"source": "eval.md", "text": "Citations let users verify whether an answer is grounded."}, {"source": "deploy.md", "text": "Deployment exposes the model through a stable API."},]
query = "why do RAG answers need citations"query_terms = set(query.lower().split())
def score(chunk): words = set(chunk["text"].lower().replace(".", "").split()) return len(query_terms & words)
for chunk in sorted(chunks, key=score, reverse=True)[:2]: print(chunk["source"], score(chunk))预期输出:
rag.md 2eval.md 1如果排在最前面的来源不相关,不要先改最终 Prompt。先检查文档解析、分块、metadata 和检索覆盖率。
按这个顺序学
Section titled “按这个顺序学”| 步骤 | 阅读 | 实操产出 |
|---|---|---|
| 1 | RAG 基础 | 画出问题 → 证据 → 回答闭环 |
| 2 | 文档处理 | 产出带来源和 metadata 的 chunks |
| 3 | 向量数据库 | 解释 embedding、向量记录和相似度搜索 |
| 4 | 检索策略 | 比较关键词、向量、混合、过滤和重排序 |
| 5 | 优化与高级 RAG | 排查召回差、排序差和上下文弱的问题 |
| 6 | RAG 评估 | 测试回答正确性、引用支撑和无答案处理 |
学完这一页,至少保留这张证据卡:
- 查询
- 一个用户问题或测试用例
- 已检索分块
- 分块 ID、分数和来源标题
- 答案
- 带引用或来源说明的最终回答
- 失败检查
- 缺少证据、切分错误、文档过时或论断无依据
- 下一步动作
- 分块、embedding、重排、Prompt 或评估改动
如果你能为至少 10 个固定问题构建一个最小知识库问答闭环,并打印检索分块、回答文本和来源引用,就通过了本章。
本章出口小项目是课程知识库助手:准备 3 到 5 篇 Markdown 文档、top-k 检索输出、来源显示和一张简单评估表。
检查思路与讲解
- 合格答案要能追踪 query、chunks、检索分数、引用证据、最终回答和兜底行为。
- 证据应包含检索片段、source metadata、带引用的回答,以及至少一个空检索或误检索案例。
- 自检时要能判断失败来自 chunking、检索、排序、prompt 拼装、资料缺失,还是无依据生成。