E.A.6 模型服务化
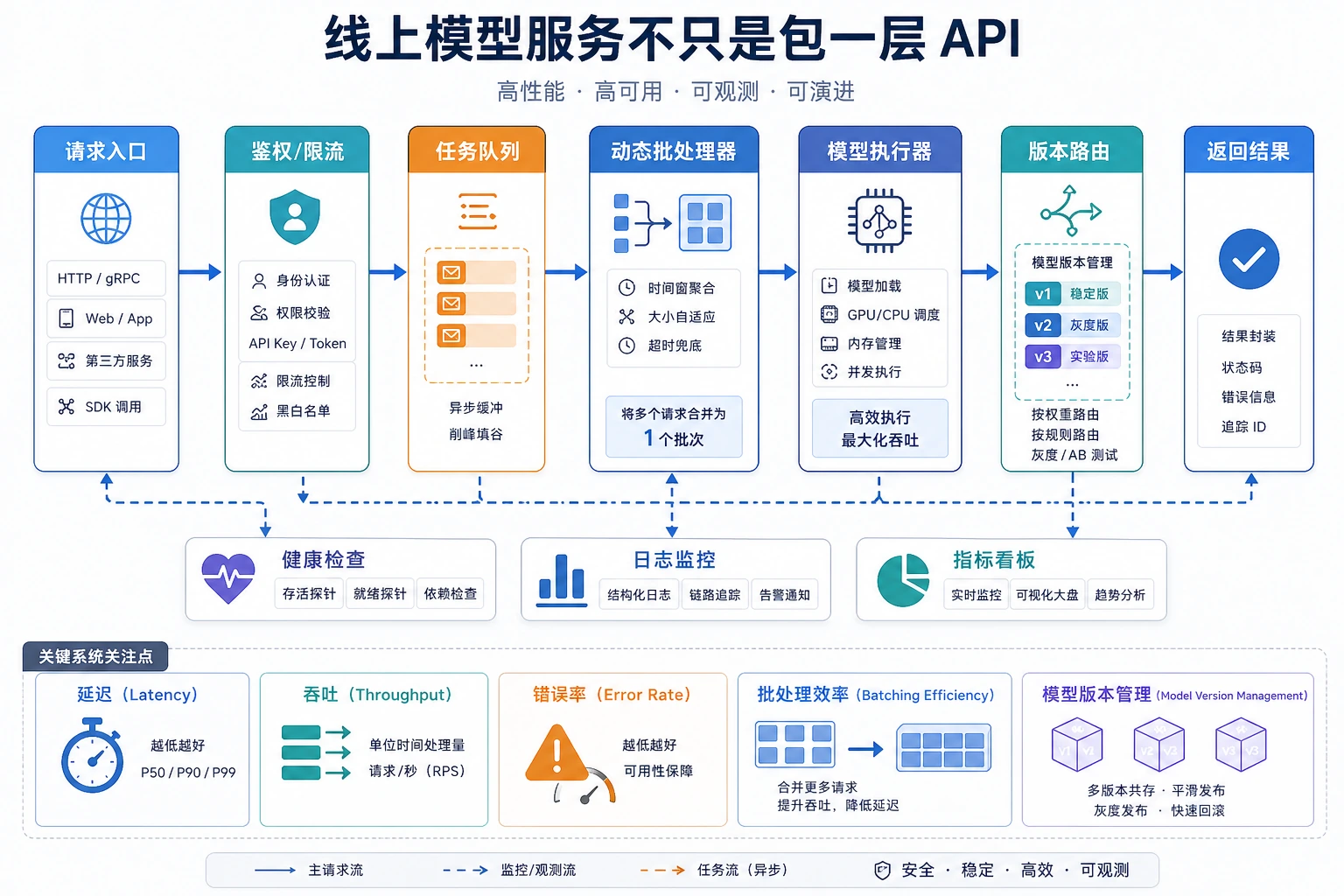
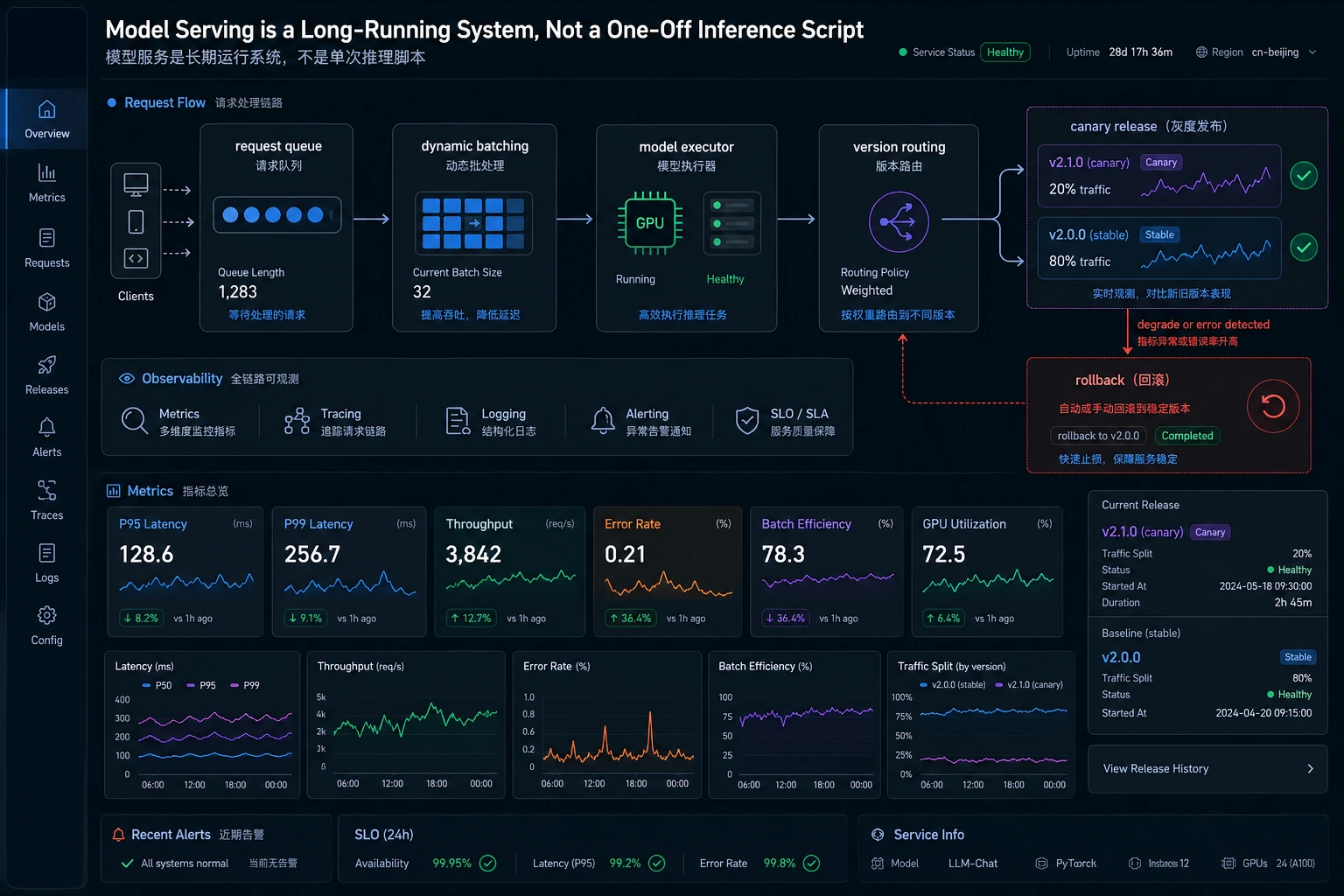
把模型服务化,和在脚本里调用一次模型不是一回事。服务要接很多请求,把它们排队、批处理、发到正确的模型版本、记录指标,并在某个版本失败时可以恢复。
- Python 3.10+
- 不需要第三方包
- 理解字典和列表即可
- Queue(队列):请求临时等待的地方。
- Batch(批):多个请求一起处理。
- Version routing(版本路由):把流量发到
v1、v2或灰度模型。 - P95 latency(P95 延迟):95% 的请求能在这个时间内完成。
- Rollback(回滚):把流量切回更稳定的旧版本。
运行一个微型 Serving 循环
Section titled “运行一个微型 Serving 循环”创建 serving_loop.py:
requests = [ {"id": 1, "version": "v1", "text": "refund"}, {"id": 2, "version": "v1", "text": "invoice"}, {"id": 3, "version": "v2", "text": "change address"}, {"id": 4, "version": "v2", "text": "shipping"}, {"id": 5, "version": "v1", "text": "certificate"},]
batches = {}for request in requests: batches.setdefault(request["version"], []).append(request)
for version, items in batches.items(): print(version, "batch_size=", len(items), "ids=", [item["id"] for item in items])
for item in items: item["answer"] = f"{version}:{item['text']}:ok"
print("answers:")for request in requests: print(request["id"], request["answer"])运行:
python serving_loop.py预期输出:
v1 batch_size= 3 ids= [1, 2, 5]v2 batch_size= 2 ids= [3, 4]answers:1 v1:refund:ok2 v1:invoice:ok3 v2:change address:ok4 v2:shipping:ok5 v1:certificate:ok这个小脚本展示了服务化的核心循环:请求进入、按版本分组、批处理,然后返回可追踪的答案。
加一条安全规则
Section titled “加一条安全规则”在批处理循环前加入:
requests = [ {"id": 1, "version": "v1", "text": "refund"}, {"id": 2, "version": "v1", "text": "invoice"}, {"id": 3, "version": "v2", "text": "change address"},]healthy_versions = {"v1": True, "v2": False}routed_requests = [ request if healthy_versions[request["version"]] else {**request, "version": "v1"} for request in requests]
print([request["version"] for request in routed_requests])预期输出:
['v1', 'v1', 'v1']再次运行。原本请求 v2 的流量会回到 v1。这就是健康检查和回滚的基本思路。
上线前先看这些指标
Section titled “上线前先看这些指标”优先记录:
- 队列等待时间
- 平均延迟和 P95 延迟
- 错误率
- 平均 batch 大小
- 每个模型版本的流量占比
模型服务复盘不要只看模型推理时间。一次请求还包含排队、预处理、batch 等待、后处理、网络传输和日志写入。用户感受到的是整条链路,而不是单个模型函数。
发布新版本时,至少保存请求 ID、版本路由、错误率、P95 延迟和回滚条件。这样模型变慢或出错时,团队才能知道该回滚哪个版本,而不是凭感觉猜。
交付检查时,模拟一次坏版本:让 v2 变慢、报错或返回异常格式,然后确认流量能回到 v1。如果只能演示成功路径,这个服务还不能算可上线,因为真实服务一定会遇到慢请求和失败请求。
学完这一页,至少保留这张证据卡:
- 部署目标
- 本地推理、边缘设备、模型服务器或优化实验
- 工件
- C++ 代码片段、基准测试、模型工件、服务配置或部署说明
- 指标
- 延迟、内存、吞吐量、模型大小、准确率下降或可靠性
- 失败检查
- ABI/构建问题、硬件不匹配、量化损失或服务瓶颈
- 期望产出
- 可复现的部署或优化证据,而不只是理论笔记
- 只汇报模型推理时间,忽略队列、预处理和网络时间。
- batch 做得太大,反而伤害用户侧延迟。
- 没有版本路由就直接替换生产模型。
- 没有请求 ID,出问题后几乎无法排查。
给每个请求加 latency_ms 字段,计算每个版本的平均延迟。如果 v2 比 v1 慢超过 20 ms,就把后续请求全部切回 v1。
参考实现与讲解
可靠做法是按 version 分组请求,计算每组 latency_ms 的平均值,再比较两个版本。如果 avg_v2 - avg_v1 > 20,就把 v2 标成不健康,或把下一批流量权重设为 0。
关键解释是:回滚应由真实服务指标驱动,而不是凭感觉。真实服务还应比较 P95 延迟和错误率,因为平均值可能掩盖长尾慢请求。