10.2.2 数据增强策略

- 理解数据增强为什么能提升泛化能力
- 区分几种常见增强方式适合处理什么问题
- 理解“标签保持不变”这个增强前提
- 通过可运行示例建立增强链路的直觉
先建立一张地图
Section titled “先建立一张地图”如果你是从第 6 站过来的,可以先把这节理解成:
- 前面你已经知道卷积网络会从图像里学特征
- 这一节开始解决“怎样让它别只记住训练集里的表面样子”
所以数据增强不是视觉里的小技巧,而是在补:
- 模型如何面对真实世界中的视角、亮度、裁剪、遮挡变化
数据增强这节最适合新人的理解顺序不是“记住多少变换名”,而是先看清:
flowchart LR A["原始图像"] --> B["做合理变换"] B --> C["标签尽量不变"] C --> D["模型看到更多变化形式"] D --> E["泛化更稳"]所以这节真正想解决的是:
- 为什么图像分类特别需要增强
- 增强什么时候是在帮忙,什么时候会伤害语义
一、为什么图像任务特别需要数据增强?
Section titled “一、为什么图像任务特别需要数据增强?”真实世界本来就在变化
Section titled “真实世界本来就在变化”同一只猫在不同图片里会有:
- 角度变化
- 光照变化
- 背景变化
- 局部遮挡
如果训练集覆盖不够,模型就很容易把偶然背景当成真正特征。
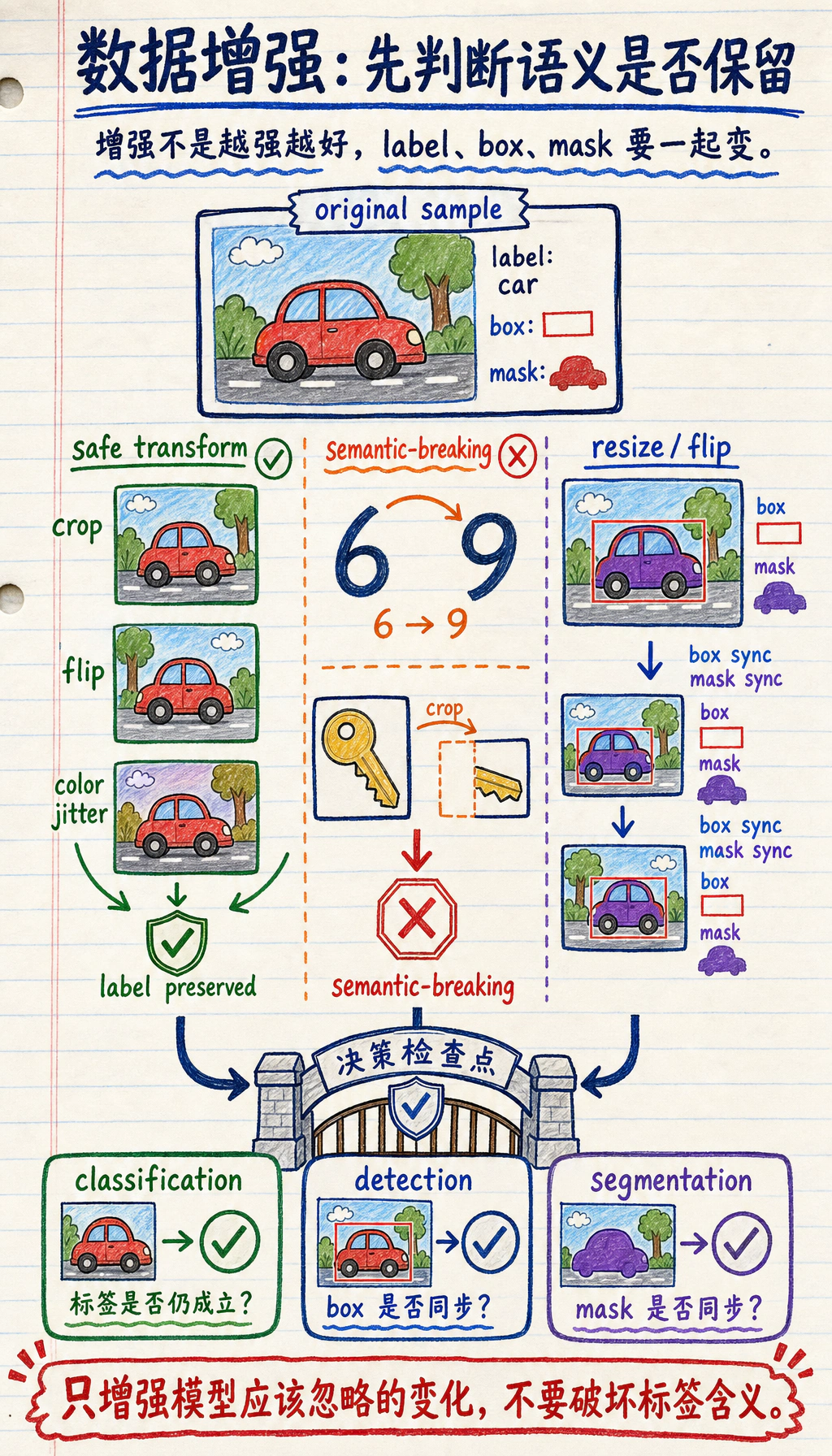
增强不是“造更多数据”,而是“模拟合理变化”
Section titled “增强不是“造更多数据”,而是“模拟合理变化””一张图片经过合理变换后, 语义通常还没变。
例如:
- 左右翻转后的猫还是猫
- 轻微裁剪后的狗还是狗
这就是为什么增强能帮助模型学得更稳。
第一次学数据增强,最该先抓住什么?
Section titled “第一次学数据增强,最该先抓住什么?”最该先抓住的不是一串 API,而是这一句:
增强是在模拟“同一个目标可能以不同合理样子出现”。
只要这句话稳住了,后面你看到:
- 翻转
- 裁剪
- 颜色扰动
- Mixup / CutMix
都会更容易判断它们到底是在帮忙,还是已经开始伤语义了。
数据增强像考前练变式题。 不是换知识点,而是让你别死记某一道题的表面样子。
二、最常见的几类增强
Section titled “二、最常见的几类增强”例如:
- 翻转
- 平移
- 裁剪
- 旋转
它主要帮助模型应对:
- 视角和位置变化
例如:
- 亮度
- 对比度
- 饱和度
它主要帮助模型应对:
- 光照和拍摄条件变化
组合与混合增强
Section titled “组合与混合增强”例如:
- Cutout
- Mixup
- CutMix
它们更激进,但也往往更有效。
第一次做图像分类时,最值得先从哪类增强开始?
Section titled “第一次做图像分类时,最值得先从哪类增强开始?”更稳的顺序通常是:
-
先从几何增强开始 因为它最直观,也最容易和“真实视角变化”对应起来。
-
再加轻量颜色增强 用来应对光照和拍摄条件变化。
-
最后再试更激进的混合增强 因为这时你已经有 baseline,比较容易判断到底有没有真的收益。
三、先跑一个最小增强流水线示例
Section titled “三、先跑一个最小增强流水线示例”下面这个例子不依赖图像库, 而是用二维列表模拟一张灰度图,帮助你抓住增强的核心思想。
image = [ [1, 2, 3], [4, 5, 6], [7, 8, 9],]
def horizontal_flip(img): return [list(reversed(row)) for row in img]
def center_crop(img, size=2): return [row[:size] for row in img[:size]]
def brightness_shift(img, delta=1): return [[pixel + delta for pixel in row] for row in img]
print("original:")for row in image: print(row)
print("\nflip:")for row in horizontal_flip(image): print(row)
print("\ncrop:")for row in center_crop(image): print(row)
print("\nbrightness:")for row in brightness_shift(image): print(row)预期输出:
original:[1, 2, 3][4, 5, 6][7, 8, 9]
flip:[3, 2, 1][6, 5, 4][9, 8, 7]
crop:[1, 2][4, 5]
brightness:[2, 3, 4][5, 6, 7][8, 9, 10]这个例子最该抓住什么?
Section titled “这个例子最该抓住什么?”增强的本质不是图像库 API, 而是:
- 对输入做合理变换
- 同时尽量不改变标签语义
为什么“合理”很重要?
Section titled “为什么“合理”很重要?”如果你把“6”和“9”这类数字图像乱旋转, 标签可能就真的变了。
所以增强不是无脑越强越好, 而要考虑任务语义。
这一点为什么对视觉任务特别重要?
Section titled “这一点为什么对视觉任务特别重要?”因为视觉里的很多标签,其实依赖几何和方向。
比如:
- 普通自然图像左右翻转可能没问题
- 数字识别里随便旋转就可能把类别语义改掉
- 检测和分割里增强还会连着框和 mask 一起变
所以增强不是“加得越多越先进”,而是:
- 是否还在尊重任务本身的语义边界
四、Mixup 为什么值得单独记住?
Section titled “四、Mixup 为什么值得单独记住?”它不是简单改图,而是连标签也一起混
Section titled “它不是简单改图,而是连标签也一起混”Mixup 的核心思想是:
- 两张图按比例混合
- 标签也按比例混合
一个纯数字直觉示例
Section titled “一个纯数字直觉示例”img_a = [1.0, 2.0, 3.0]img_b = [7.0, 8.0, 9.0]label_a = [1.0, 0.0]label_b = [0.0, 1.0]alpha = 0.7
mixed_img = [round(alpha * a + (1 - alpha) * b, 2) for a, b in zip(img_a, img_b)]mixed_label = [round(alpha * a + (1 - alpha) * b, 2) for a, b in zip(label_a, label_b)]
print("mixed_img:", mixed_img)print("mixed_label:", mixed_label)预期输出:
mixed_img: [2.8, 3.8, 4.8]mixed_label: [0.7, 0.3]为什么这种方法会有效?
Section titled “为什么这种方法会有效?”它会让模型更少学到极端边界, 更倾向于形成平滑决策面。
五、增强最容易踩的坑
Section titled “五、增强最容易踩的坑”误区一:增强越重越好
Section titled “误区一:增强越重越好”增强过头可能会把有效特征破坏掉。
误区二:所有任务共用同一套增强
Section titled “误区二:所有任务共用同一套增强”分类、检测、分割对增强的敏感点并不完全一样。
误区三:只加增强,不做验证
Section titled “误区三:只加增强,不做验证”增强是手段,不是目标。 最终还是要看验证集是否真的受益。
新人第一次做图像分类时,最稳的增强顺序
Section titled “新人第一次做图像分类时,最稳的增强顺序”如果你刚开始做视觉分类,建议先按这个顺序来:
- 先用水平翻转
- 再加轻量裁剪
- 再加轻量颜色扰动
- 确认 baseline 稳定后,再尝试 Mixup / CutMix
这样更容易知道到底是哪类增强在起作用。
验证增强是否真的有效,最值得先看什么?
Section titled “验证增强是否真的有效,最值得先看什么?”不要只看训练集 loss。 更稳的判断是:
- 验证集指标有没有提升
- 错例类型有没有变得更合理
- 模型是不是不再特别依赖背景或拍摄姿态
也就是说,增强真正的价值不只是“分数高一点”,而是让模型学到更稳定的视觉特征。
学完这一页,至少保留这张证据卡:
- 数据集划分
- 训练/测试图像、类别名和类别平衡
- 预测
- 标签、置信度和至少一张分类错误的图像
- 指标
- 准确率、F1、混淆矩阵和类别级错误
- 失败检查
- 增强改变标签含义、类别不平衡、数据泄漏或过拟合
- 期望产出
- 模型结果表和保存的错误示例
这节最重要的是建立一个判断:
数据增强的核心,是通过模拟合理变化,让模型学会抓住更稳定的视觉特征,而不是死记训练集里的偶然细节。
只要这层直觉在,后面你看更复杂增强策略就不会迷路。
这节最该带走什么
Section titled “这节最该带走什么”- 增强不是越猛越好,而是要和任务语义匹配
- 第一次做项目时,先从最稳的几类增强开始
- 验证集是否变好,才是增强值不值得保留的真正标准
如果再压成一句话,那就是:
数据增强的本质不是“把图改花”,而是在不改语义的前提下,让模型见过更多合理变化。
- 给示例再写一个
vertical_flip函数。 - 想一想:为什么某些任务里旋转增强可能是有害的?
- 用自己的话解释:Mixup 和普通增强最大的不同是什么?
- 如果验证集效果下降,你会先怀疑增强太弱还是太强?
参考实现与讲解
- 简单的
vertical_flip可以用image[::-1]或np.flipud(image)。如果标签里有 mask 或 box,也必须跟着图像一起翻转。 - 当方向本身有语义时,旋转增强可能有害,例如数字、交通标志、医学图像,或任何倒置样本不真实的任务。
- Mixup 会同时混合图像和标签;普通增强通常只改变单张图像,同时保持原标签不变。
- 如果验证集表现下降,先可视化增强后的样本。常见原因是增强太强或语义错误;当然,增强太弱也可能让模型继续过拟合。