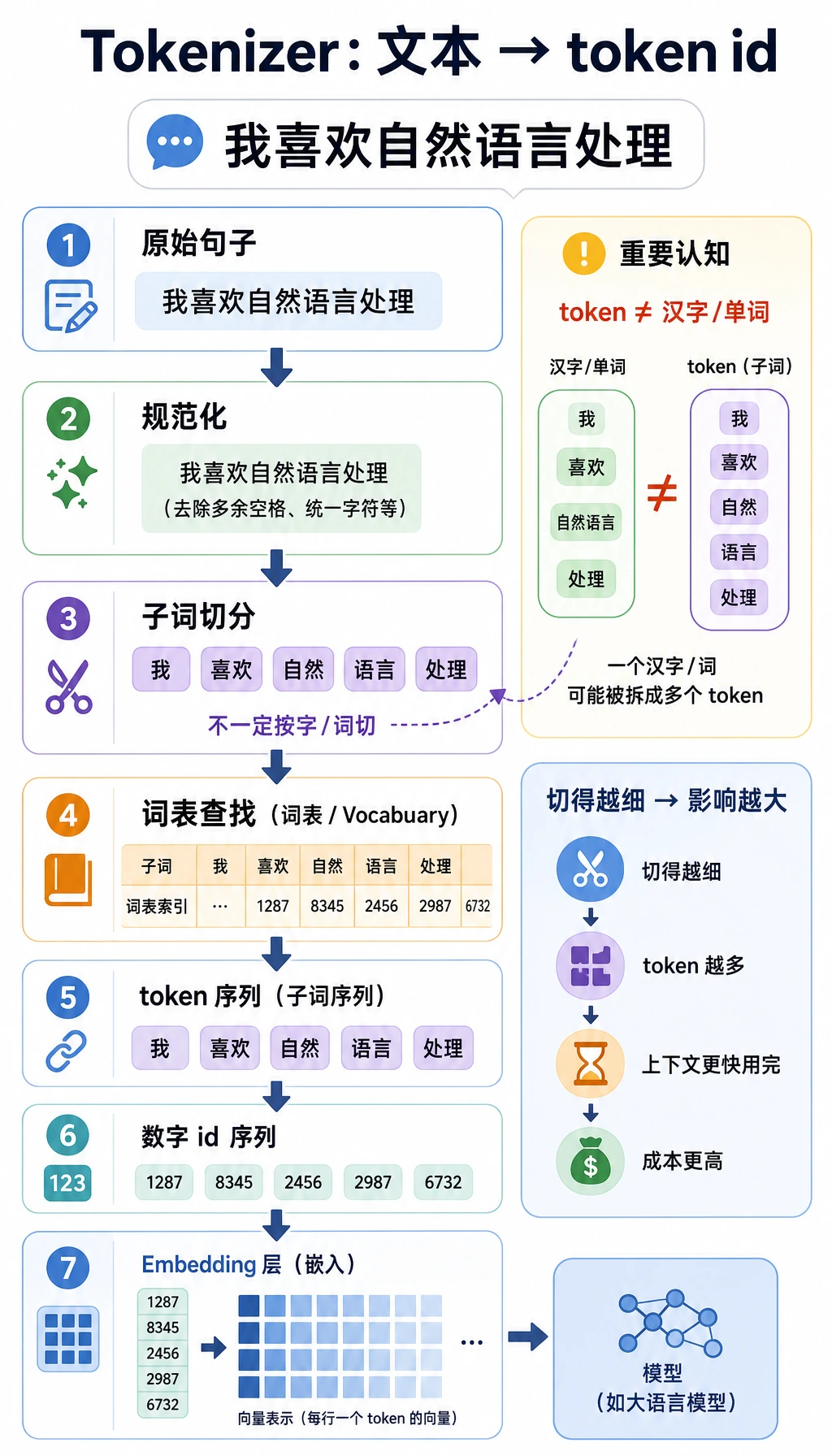
7.1.2 分词与 Tokenizer
先建立心智模型
Section titled “先建立心智模型”神经网络不能直接读字符串,它接收的是张量。Tokenizer 是人类文字和模型张量之间的契约:
raw texttokensinput_idsmodel
很多看起来很玄的大模型问题,只要检查这个契约就会变清楚:
- 一个词可能被拆成多个 token;
- 标点、大小写、中文、代码、emoji 都可能显著改变 token 数;
- padding 让同一批样本长度一致;
- truncation 会在序列过长时静默删掉内容;
- chat template 会在 system、user、assistant 消息周围加入隐藏结构 token。
切分粒度的取舍
Section titled “切分粒度的取舍”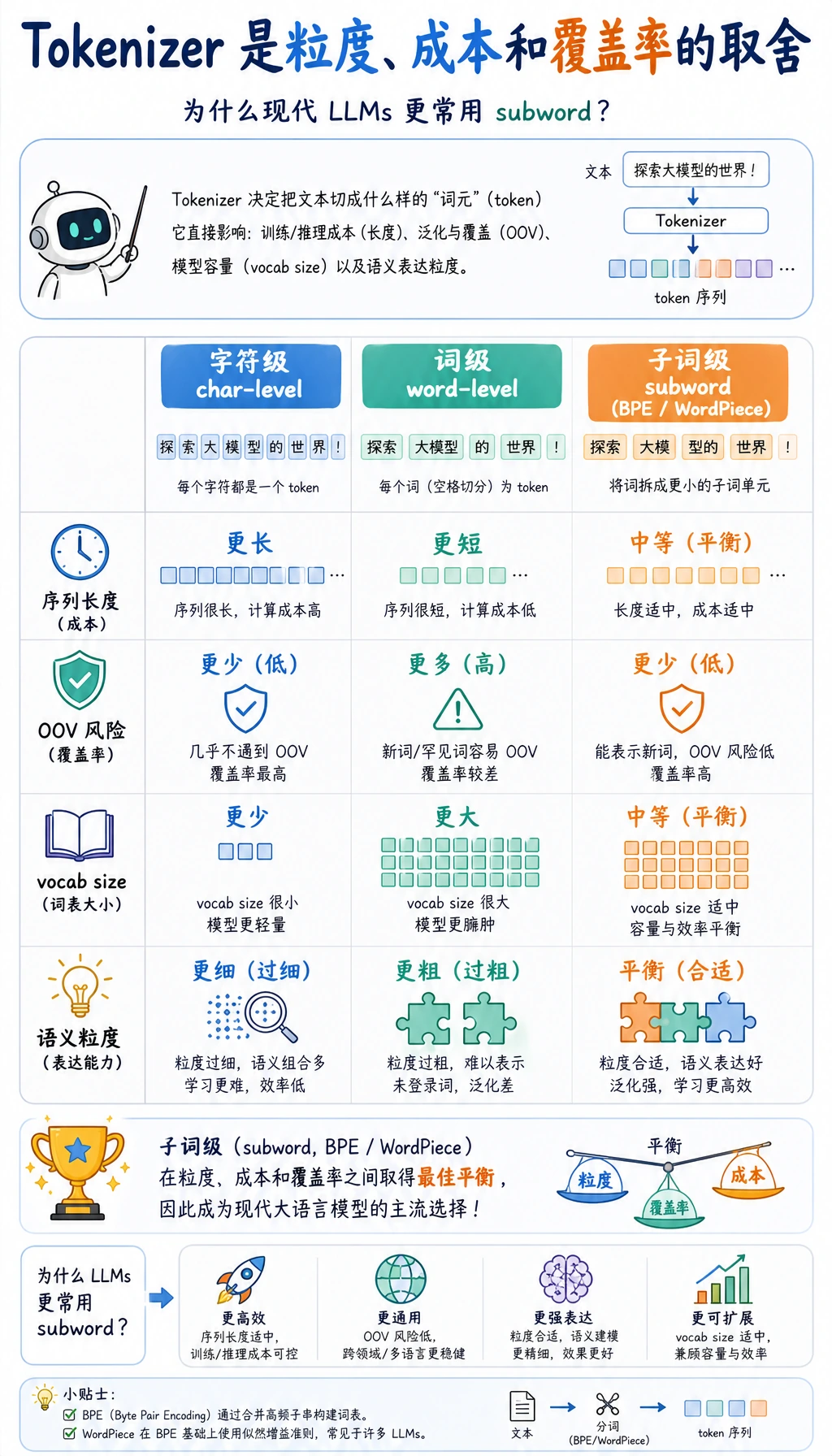
常见切法有三类:
| 方法 | 例子 | 优点 | 缺点 |
|---|---|---|---|
| 字符级 | r e f u n d | 几乎没有未知词 | 序列很长 |
| 词级 | refund policy | 语义直观 | 很多词会超出词表 |
| 子词级 | token ##ization | 工程上更平衡 | 肉眼不如整词好读 |
现代 LLM 通常使用子词分词。BPE、WordPiece、SentencePiece 是从语料中学习可复用片段的不同方法。核心思想一致:高频片段有稳定 ID,低频新词也能由更小片段组合出来。
实验 1:手写一个极小 WordPiece 风格 Tokenizer
Section titled “实验 1:手写一个极小 WordPiece 风格 Tokenizer”先跑这个版本。它足够小,可以逐行看懂,但包含真实模型 API 里会出现的关键对象。
import re
VOCAB = { "[PAD]": 0, "[UNK]": 1, "[CLS]": 2, "[SEP]": 3, "refund": 4, "policy": 5, "reset": 6, "password": 7, "transform": 8, "##er": 9, "##s": 10, "token": 11, "##ization": 12, "please": 13, "help": 14, "need": 15, "evidence": 16,}
def words(text): return re.findall(r"[A-Za-z]+", text.lower())
def split_wordpiece(word): if word in VOCAB: return [word]
pieces = [] start = 0 while start < len(word): match = None for end in range(len(word), start, -1): piece = word[start:end] if start == 0 else "##" + word[start:end] if piece in VOCAB: match = piece break if match is None: return ["[UNK]"] pieces.append(match) start = end return pieces
def encode(text, max_length=10): tokens = ["[CLS]"] for word in words(text): tokens.extend(split_wordpiece(word)) tokens.append("[SEP]")
original_len = len(tokens) if len(tokens) > max_length: tokens = tokens[:max_length] tokens[-1] = "[SEP]"
input_ids = [VOCAB.get(token, VOCAB["[UNK]"]) for token in tokens] attention_mask = [1] * len(input_ids)
while len(input_ids) < max_length: tokens.append("[PAD]") input_ids.append(VOCAB["[PAD]"]) attention_mask.append(0)
return { "text": text, "original_len": original_len, "tokens": tokens, "input_ids": input_ids, "attention_mask": attention_mask, }
for example in [ "Please help reset password", "Transformers refund policy", "Tokenization needs evidence",]: row = encode(example, max_length=10) print("-" * 64) print("text:", row["text"]) print("original_len:", row["original_len"]) print("tokens:", row["tokens"]) print("input_ids:", row["input_ids"]) print("attention_mask:", row["attention_mask"])预期输出:
----------------------------------------------------------------text: Please help reset passwordoriginal_len: 6tokens: ['[CLS]', 'please', 'help', 'reset', 'password', '[SEP]', '[PAD]', '[PAD]', '[PAD]', '[PAD]']input_ids: [2, 13, 14, 6, 7, 3, 0, 0, 0, 0]attention_mask: [1, 1, 1, 1, 1, 1, 0, 0, 0, 0]----------------------------------------------------------------text: Transformers refund policyoriginal_len: 7tokens: ['[CLS]', 'transform', '##er', '##s', 'refund', 'policy', '[SEP]', '[PAD]', '[PAD]', '[PAD]']input_ids: [2, 8, 9, 10, 4, 5, 3, 0, 0, 0]attention_mask: [1, 1, 1, 1, 1, 1, 1, 0, 0, 0]----------------------------------------------------------------text: Tokenization needs evidenceoriginal_len: 7tokens: ['[CLS]', 'token', '##ization', 'need', '##s', 'evidence', '[SEP]', '[PAD]', '[PAD]', '[PAD]']input_ids: [2, 11, 12, 15, 10, 16, 3, 0, 0, 0]attention_mask: [1, 1, 1, 1, 1, 1, 1, 0, 0, 0]这样读输出:
[CLS]和[SEP]是结构 token;transformers被拆成transform、##er、##s,因为词表里没有完整单词;input_ids是模型真正接收的整数;attention_mask=0标记[PAD]位置,提醒模型忽略它们。
实验 2:把 truncation 当成产品风险看
Section titled “实验 2:把 truncation 当成产品风险看”
现在故意把上下文窗口调小。
row = encode("Please help reset password refund policy evidence", max_length=6)print("original_len:", row["original_len"])print("tokens:", row["tokens"])print("input_ids:", row["input_ids"])print("attention_mask:", row["attention_mask"])预期输出:
original_len: 9tokens: ['[CLS]', 'please', 'help', 'reset', 'password', '[SEP]']input_ids: [2, 13, 14, 6, 7, 3]attention_mask: [1, 1, 1, 1, 1, 1]refund policy evidence 不见了。在真实客服助手里,这可能正好删掉用户真正想问的内容。所以 tokenizer 不是小小的预处理细节,它会影响成本、检索片段长度、prompt 设计和失败模式。
实验 3:检查真实 Hugging Face 分词器(Tokenizer)
Section titled “实验 3:检查真实 Hugging Face 分词器(Tokenizer)”第一次下载模型 tokenizer 时需要网络。
python -m pip install "transformers>=4.0" torchfrom transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
batch = tokenizer( ["Please help reset password", "Tokenization needs evidence"], padding="max_length", truncation=True, max_length=10, return_tensors="pt",)
print(batch.keys())print(batch["input_ids"].shape)print(tokenizer.convert_ids_to_tokens(batch["input_ids"][1]))print(batch["attention_mask"][1].tolist())预期形状级输出:
dict_keys(['input_ids', 'token_type_ids', 'attention_mask'])torch.Size([2, 10])['[CLS]', 'token', '##ization', 'needs', 'evidence', '[SEP]', '[PAD]', '[PAD]', '[PAD]', '[PAD]'][1, 1, 1, 1, 1, 1, 0, 0, 0, 0]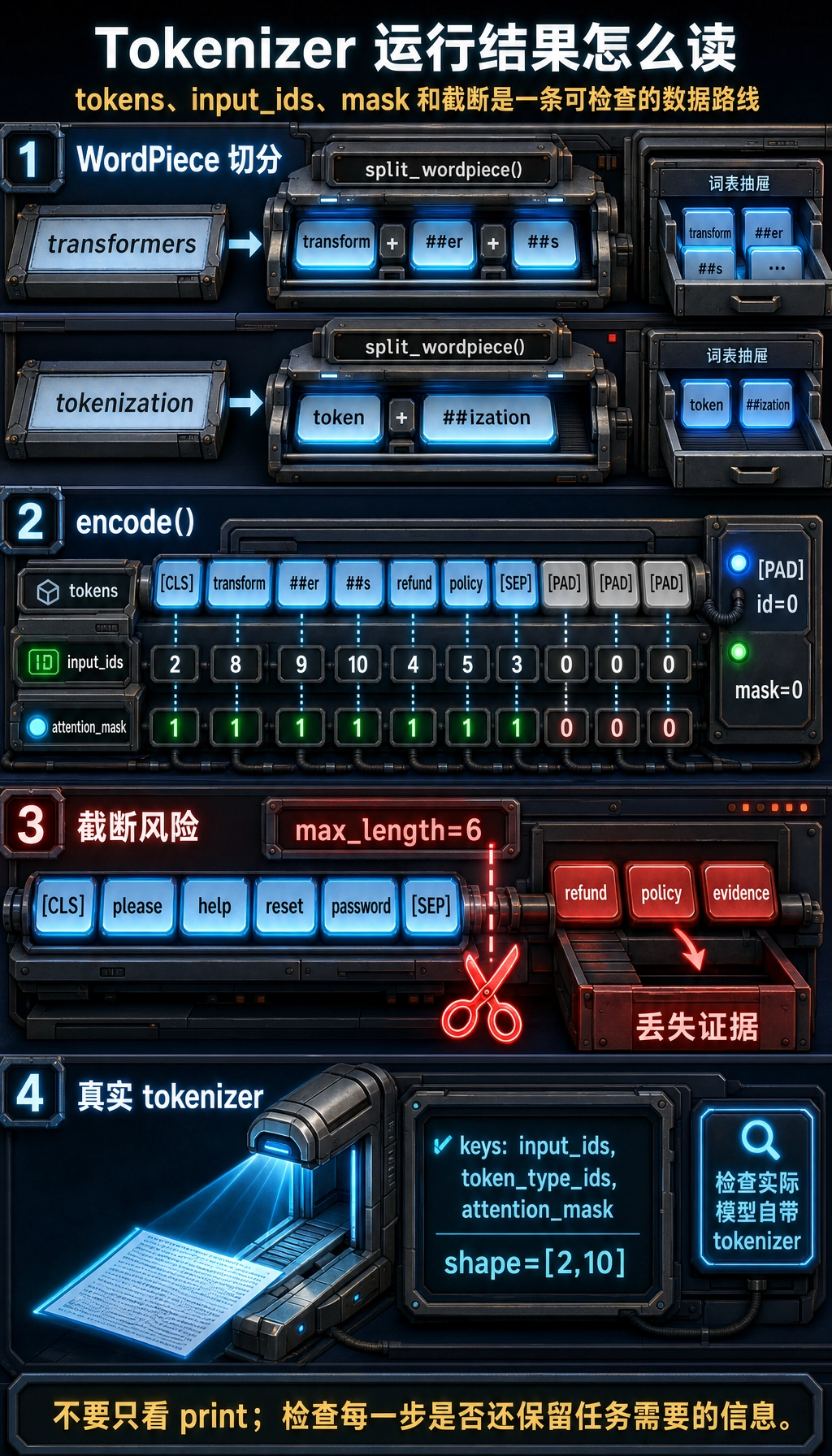
不同 tokenizer 的具体切法可能不同。这正是重点:永远检查你实际使用的模型自带 tokenizer。
值得记住的术语
Section titled “值得记住的术语”| 术语 | 实操含义 |
|---|---|
vocab | tokenizer 训练得到的 token 到 ID 字典 |
| OOV | out-of-vocabulary,超出词表;通常用 [UNK] 或子词组合处理 |
| BPE | 把高频字符对合并成可复用子词 |
| WordPiece | 类似的子词思想,常见于 BERT 类 tokenizer |
| SentencePiece | 把文本当成原始字符流处理,适合多语言和无空格语言 |
padding_side | padding 加在左边还是右边;某些解码器模型很敏感 |
| 上下文长度 | 输入和生成输出共享的最大 token 预算 |
| chat template | tokenizer 层面的对话格式,会加入角色和边界 token |
Prompt 表现异常时,先检查 tokenizer,再怀疑模型:
- 打印完整 prompt 的 tokens 和 token IDs;
- 统计 chat template 之后的 token 数,不只看原始用户文本;
- 检查 truncation 是否删掉了指令、检索证据或最新问题;
- 批处理解码器模型时确认 padding 方向和
attention_mask; - 对比中文、英文、代码、emoji 输入,它们的 token 数可能差很多。
学完这一页,至少保留这张证据卡:
- 样本文本
- 一个英文/CJK/代码风格示例
- token 列表
- 打印的 token 列表和 token 数量
- 截断案例
- 哪些内容被截断以及为什么重要
- 产品风险
- 成本、上下文限制或丢失指令
- 调试动作
- 先检查分词,再怪模型
- 从
VOCAB删除transform,观察Transformers refund policy会怎样。 - 把
max_length从10改成5,看哪些有用 token 先消失。 - 加入
"##ing",测试resetting password能不能被表示。 - 用实验 3 换一个模型 tokenizer,对比中文、英文、代码的 token 数。
- 为一个 RAG prompt 分配 token 预算:system 指令、检索证据、用户问题、回答空间各留多少?
参考实现与讲解
- 删除
transform后,Transformers会更难表示。根据玩具规则,它可能退化成[UNK],或者被切成更不稳定的片段,这说明词表覆盖很重要。 max_length=5时,通常后面的 token 会先被截断。真实 prompt 中,被截掉的可能是约束、检索证据,或者用户问题的尾部。"##ing"只有在 tokenizer 还能找到合适词干时才有帮助。子词能缓解很多词形变化,但不会自动理解词义。- 不同 tokenizer 对同一段文本的 token 数可能差很多。中文、代码和 emoji 多的输入尤其应该先实际检查,再估算成本和上下文长度。
- 一个起步分配可以是:system 指令 10-15%,检索证据 60-70%,用户问题 5-10%,剩余留给回答。最终比例要看产品风险。
Tokenizer 不只是切文字。它定义了模型能看见的世界:
text boundarytoken boundaryID sequenceattention maskcontext budget
只要能检查这条路径,很多 LLM 工程问题在看模型结构之前就能先定位。