4 AI 数学:最小必要基础
第 4 章只解决一件事:让模型里的数学变成能运行、能解释的工具,而不是一面公式墙。
你在主线中的位置
Section titled “你在主线中的位置”你已经建立了基本编码和数据分析工作流。现在这一章会把这些能力转换成模型语言:数据变成向量或矩阵,不确定性变成概率,错误变成损失,改进变成基于梯度的参数更新。
你不需要先变成数学家才能继续。你需要做的是跑最小例子、读懂输出,并解释每个公式支持哪个模型动作。第 5 章会把这些基础落到 sklearn 模型训练和评估里。
先看模型数学闭环
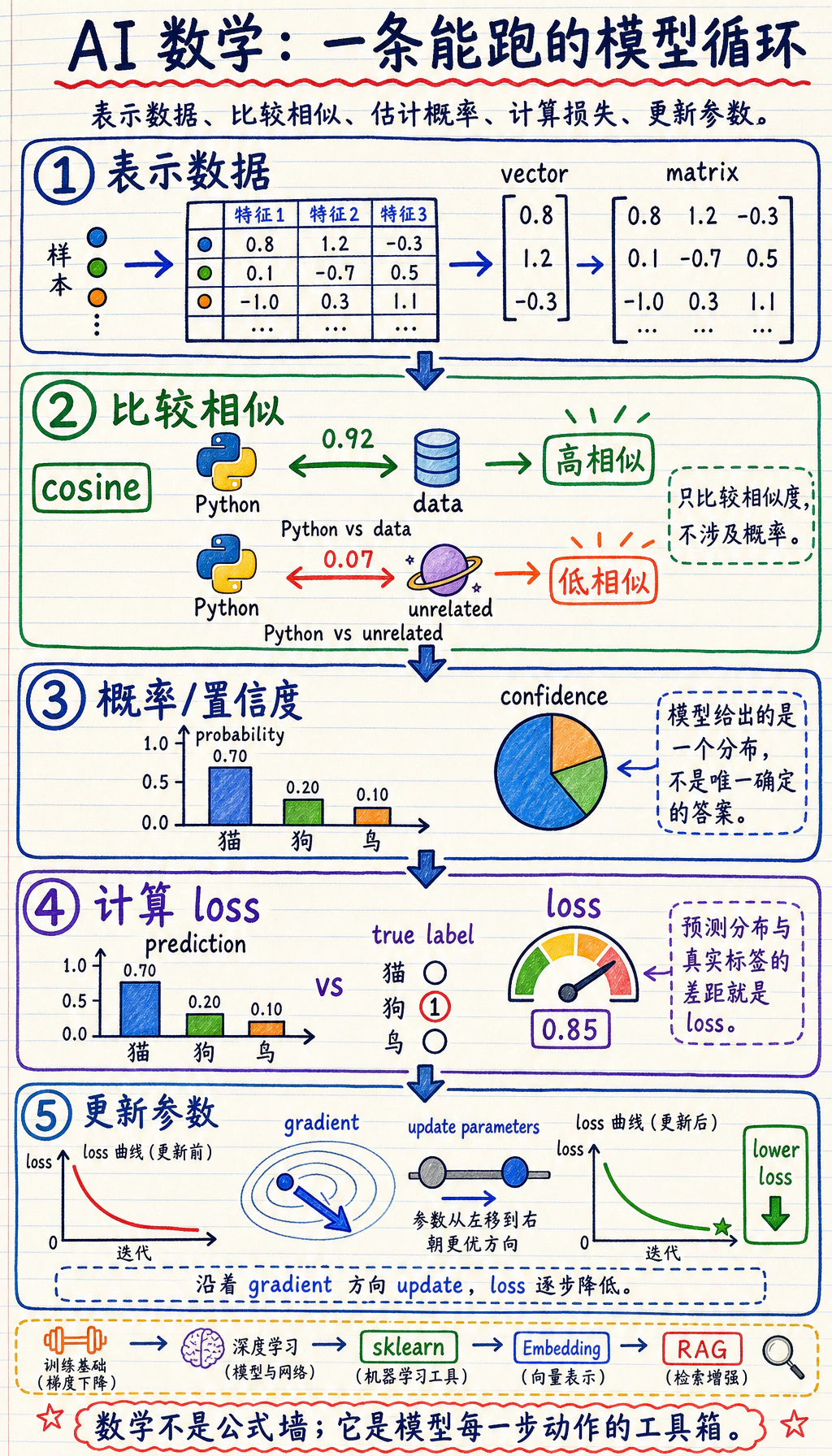
Section titled “先看模型数学闭环”
先看图。本课程里大多数 AI 数学都服务于这个闭环:
向量和矩阵负责表示数据,概率负责表达不确定性,损失告诉模型错得多不多,梯度告诉模型往哪里改。
为什么 AI 总离不开这三类数学
Section titled “为什么 AI 总离不开这三类数学”AI 模型看起来有很多名字,但底层经常在重复三件事:表示、判断不确定性、更新参数。这也是线性代数、概率统计、微积分会反复出现的原因。
| 数学分支 | AI 里的角色 | 没有它会怎样 |
|---|---|---|
| 线性代数 | 把样本、参数、Embedding、图像和注意力组织成向量、矩阵或张量 | 数据无法批量表示、变换和比较 |
| 概率统计 | 描述不确定性、分布、采样、置信度和评估波动 | 模型只能给硬判断,很难表达“有多确定” |
| 微积分与优化 | 计算 loss 怎样随参数变化,并指导参数更新 | 参数不知道该往哪里改,训练无法推进 |
所以不要把本章当成三块孤立知识。更好的记法是:线性代数负责把东西放进可计算空间,概率统计负责解释模型有多不确定,微积分和优化负责让模型从错误中调整。
这些数学后面会在哪里用?
Section titled “这些数学后面会在哪里用?”学数学时最容易卡住的地方,是不知道公式之后会服务谁。先把本章概念和后面章节连起来:
| 数学工具 | 后面会用在哪里 | 你现在先抓住什么 |
|---|---|---|
| 向量 / 矩阵 | Embedding、RAG 检索、神经网络输入、图像张量 | 数据会被组织成可以计算的形状 |
| 点积 / 余弦相似度 | 向量搜索、推荐、attention 分数 | 比较两个表示是否方向接近 |
| 概率 / 分布 | 分类置信度、采样、生成模型、异常检测 | 模型输出常常是在表达不确定性 |
| 熵 / KL | VAE、语言模型损失、RLHF、分布对齐 | 衡量“不确定”或“两个分布差多远” |
| 导数 / 梯度 | PyTorch backward()、梯度下降、微调 | 告诉参数往哪个方向改会让 loss 变小 |
| 链式法则 | 反向传播、深度网络训练 | 多层模型的误差怎样一层层传回去 |
这张表不是让你提前学完后面的内容,而是提醒你:本章每个小公式,后面都会变成一个模型动作。
学习顺序与任务表
Section titled “学习顺序与任务表”先学理论,再做完整工作坊。工作坊放在最后,因为它是把这些概念串起来,而不是从零介绍概念。
- 4.1 线性代数:用向量、矩阵、点积、范数和余弦相似度比较样本。
- 4.2 概率与统计:模拟不确定性、分布、均值、方差、熵和损失。
- 4.3 微积分与优化:跟踪导数、梯度、学习率和梯度下降。
- 4.4 完整数学工作坊:用一个可运行脚本串起完整链条,并保留
ch04_math_workshop_evidence/。
必修主线、扩展和深度挑战
Section titled “必修主线、扩展和深度挑战”| 层级 | 现在学什么 | 怎么使用 |
|---|---|---|
| 必修核心 | 向量相似度、矩阵形状、概率直觉、损失、梯度下降 | 后面会变成特征、指标、embedding、检索分数和训练更新 |
| 可选扩展 | 特征值、向量空间、历史与基础 | 遇到 PCA、表示几何或模型历史问题时再回来 |
| 深度挑战 | 改一个输入、概率、损失或学习率,先预测结果再运行代码 | 训练“先推理、再实验”的习惯 |
本章常见术语:
| 术语 | 含义 |
|---|---|
Embedding | 文本、图片、用户或物品的向量表示 |
dot product | 两个向量方向有多一致 |
norm | 向量长度或强度 |
entropy | 不确定性或惊讶程度 |
loss | 衡量模型错误的数字 |
gradient | 让数值变化最快的方向 |
GD / SGD | 梯度下降 / 随机梯度下降:沿损失往低处走 |
第一个可运行闭环
Section titled “第一个可运行闭环”如果还没有 NumPy,先安装:
python -m pip install numpy然后运行下面脚本。它会先让你看到:为什么向量相似度会出现在 Embedding 和检索里。
import numpy as np
python_topic = np.array([1.0, 1.0, 0.0])data_topic = np.array([1.0, 0.8, 0.2])unrelated_topic = np.array([0.0, 0.1, 1.0])
def cosine(a, b): return a @ b / (np.linalg.norm(a) * np.linalg.norm(b))
print("Python vs data:", round(cosine(python_topic, data_topic), 3))print("Python vs unrelated:", round(cosine(python_topic, unrelated_topic), 3))预期输出:
Python vs data: 0.982Python vs unrelated: 0.071代码很小,但这个想法后面会反复出现在 Embedding、检索、推荐、注意力和 RAG 里。
如何读这个输出
Section titled “如何读这个输出”0.982表示两个向量方向非常接近。0.071表示无关向量几乎和 Python 主题正交。- 这些数不是神秘分数,而是点积除以两个向量长度得到的。
- 改一个维度前,先预测结果方向,再运行代码验证。
| 层级 | 你能证明什么 |
|---|---|
| 最低通过 | 能运行一个向量相似度例子,并解释每个维度代表什么。 |
| 项目可用 | 能把向量、概率、损失和梯度对应到同一个模型动作,而不是当成互不相关的公式。 |
| 深度检查 | 能修改一个输入或学习率,先预测结果变化方向,再用代码验证。 |
学完这一页,至少保留这张证据卡:
- 概念桥接
- 哪种数学思想支撑模型训练或 AI 应用
- 计算
- 可手算或用 NumPy 检查的小例子
- 输出
- 数值、曲线、向量、矩阵、概率,或梯度 trace
- 失败检查
- 只会背公式,却不知道它解释的是模型行为
- 期望产出
- 说明一个真实 AI 操作的数学笔记
| 现象 | 先检查什么 | 常见修复 |
|---|---|---|
| 公式太抽象 | 它支持哪个模型动作 | 翻译成表示、比较、衡量不确定性、衡量损失或更新参数 |
| 向量例子看不懂 | 每个维度是什么意思 | 计算前先给维度写标签 |
| 概率概念混在一起 | 什么是随机变量,什么是事件 | 用小表列出样本、结果和概率 |
| 梯度下降发散 | 学习率是否太大 | 每步打印或画出 loss,并调小学习率 |
| 工作坊像魔法 | 是否跳过了理论 | 先读 4.1、4.2、4.3 的路线页 |
能回答下面五个问题,就可以进入第 5 章:
- 一个样本怎样变成向量?
- 为什么模型输出可以理解成概率或置信度?
- 损失衡量的是什么?
- 梯度怎样告诉参数往哪里移动?
- 能不能运行 4.4 完整数学工作坊,并解释生成文件?
需要打印式清单时,打开 4.0 学习指南与任务单。下一章会把这些数学直觉落到 sklearn 模型训练和评估里。
检查思路与讲解
- 完整通关检查要把公式、代码和模型行为连起来。不要停在“我知道公式”;要展示一个小计算,并说明它解释了哪个 AI 任务。
- 向量和矩阵的证据应包含 shape 检查,以及一个相似度或变换结果;概率部分要有重复采样估计或 Bayes 更新;微积分部分要有梯度和一次更新步骤。
- 如果你不能用白话解释某个数字的含义,先别关掉这一章,补一张图或一个很小的 NumPy 例子。