0.5 贯穿项目线:课程知识助手
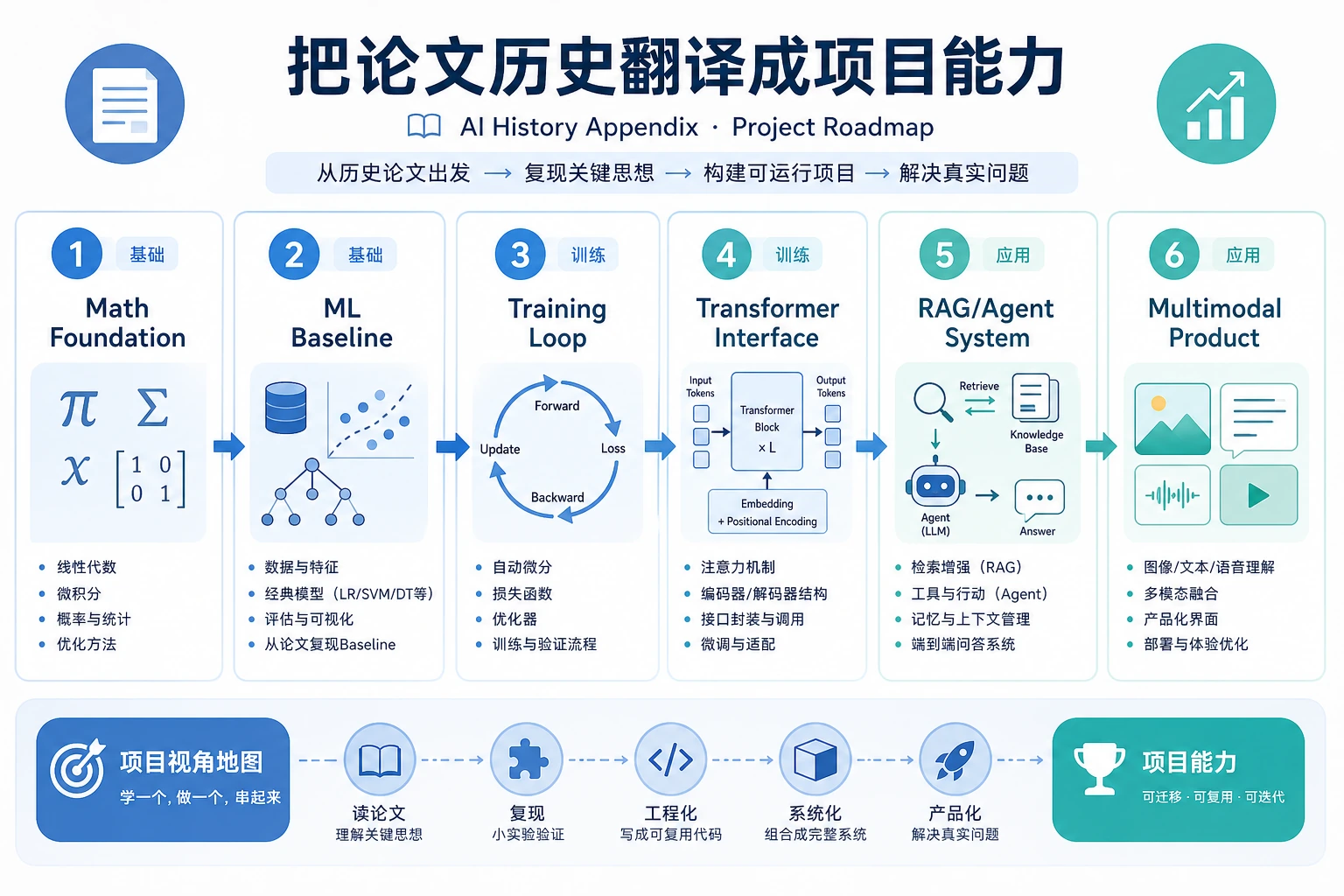
如果还没有自己的项目,默认做一个课程知识助手。它不是额外作业,而是一条贯穿全课的作品集线:每章只给它加一层能力,最后得到一个能解释、能运行、能评估、能部署的 AI 应用。
这个项目最终应该能做到:
- 读取一组课程笔记、PDF、网页摘录或自己的学习记录;
- 清洗数据并保存来源、时间、字段和质量说明;
- 用 Prompt、RAG 或 Agent 回答问题,并留下检索和工具 trace;
- 有固定评估问题、失败样本、成本/延迟记录和安全边界;
- 可选地接入图片、OCR、多模态素材或本地开源模型运行时;
- 任何审阅者都可以按 README 重新运行核心路径。
capstone-course-assistant/ README.md data/ raw/ processed/ notebooks/ src/ cli.py data_pipeline.py evals.py rag.py agent_tools.py reports/ evidence_log.md failure_cases.md eval_results.csv runtime_notes.md第一天只需要建文件夹和 README。后面的文件会随着章节自然长出来。
作品集提交模板
Section titled “作品集提交模板”每个大阶段结束后,都用同一种最终打包格式。这样项目会变得可审阅,而不是一堆散乱 demo。
README.md 它做什么、如何运行、暂不支持什么run.sh or commands.md 精确重跑路径data_note.md 来源、字段、清洗规则、隐私说明eval_cases.csv 用于对比的固定问题或输入failure_cases.md 至少一个真实失败和可能原因screenshots/ or outputs/ 可见结果、图表、trace 或 API 响应release_note.md 本章新增了什么,下一步测试什么最低版本:README、一条运行命令、一个输出和一个失败备注。更强作品集版本:固定评估集、before/after 对比、成本或延迟备注、安全边界和简短演示脚本。
第 1-3 章:可复现工作台 留下环境命令、Git 提交、Python CLI、样本数据、清洗规则、图表和数据质量笔记。
第 4-6 章:模型证据 用一个小分类、回归或表示学习实验练 baseline、指标、错误样本和训练诊断。目标不是追高分,而是学会用证据判断模型。
第 7 章:LLM 行为控制 固定 5-10 个问题,比较 Prompt、结构化输出、token/上下文限制和失败样本。可选跑通 mini GPT-2,理解训练与生成路径。
第 8 章:RAG 知识回答 把课程材料切块、加 metadata、做检索、生成带引用回答。每次回答前先保存 top-k 片段,避免只看最终文本。
第 9 章:Agent 工具闭环 只给助手开放少量安全工具,例如查文件、列目录、生成报告。保存 tool schema、trace、安全拦截和回滚说明。
第 10-12 章:按项目扩展 需要图片或 OCR 就接第 10 章;需要文本标签、抽取、摘要就接第 11 章;需要 PDF、图片、音频、视频或创意包就接第 12 章。
第 13 章:开源模型运行时 用小模型先跑通本地推理、评估和 OpenAI 风格 API;有 GPU 时再尝试 vLLM 或 SGLang。保留模型许可证、环境报告、first run、评估表和停止步骤。
每章只改一件事
Section titled “每章只改一件事”每章结束时只问四个问题:
- 这个项目新增了哪一个能力?
- 哪个命令能重跑它?
- 哪个证据能证明它有效?
- 哪个失败样本提醒我不要夸大?
如果答案写不出来,先补证据,不要继续加功能。
把这一页的学习结果保存成一张项目线证据卡:
- 项目名称
- 课程知识助手,或你自己的替代项目
- 章节成长规则
- 每章只加一个能力,不堆一堆 demo
- 重跑路径
- README 命令、脚本、notebook cell,或服务端点
- 审阅包
- 数据说明、评估用例、trace、失败笔记和 release note
- 期望产出
- 一条从环境搭建成长到 RAG、Agent 和运行时证据的项目线
最低通过标准
Section titled “最低通过标准”学完主线后,这个项目至少应该包含:
- 一个能运行的 README;
- 一个小数据集或文档集;
- 一组固定评估问题;
- 一份 Prompt/RAG/Agent trace;
- 一份失败案例和改进计划;
- 一段说明:什么时候用云 API、什么时候用开源模型运行时。
这份项目线的目标不是做最大系统,而是做一个别人看完会相信你真的理解 AI 工程闭环的系统。
项目线具备一个重跑命令、一个评估证据和一个已知失败案例,就算通过这一页。