5.6.1 机器学习项目路线图:baseline、证据、改进
本小章是第 5 章出口。它证明你能把一个数据问题变成可评估、可解释、可展示的建模流程。
先看项目闭环
Section titled “先看项目闭环”
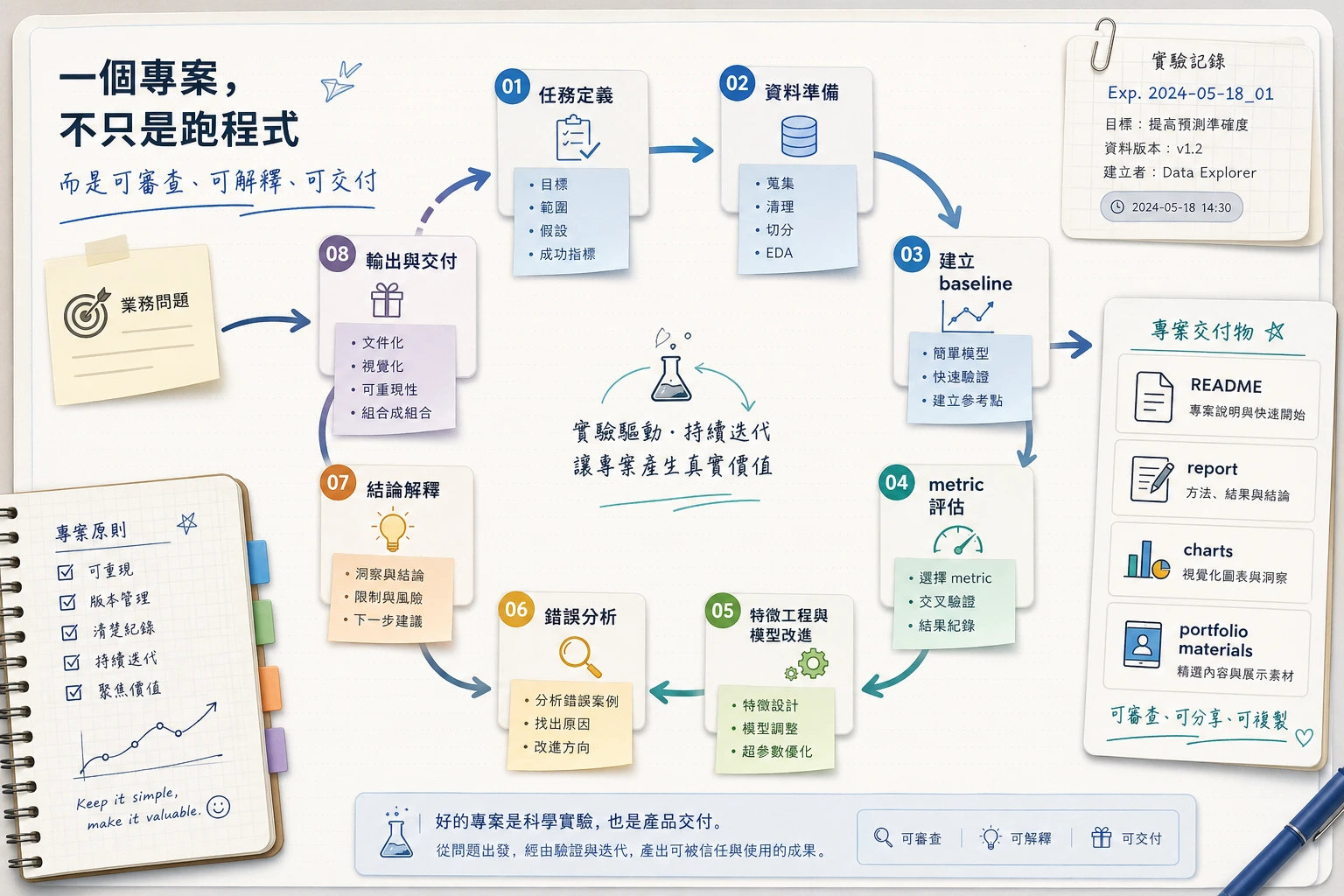
记住这个项目闭环:
问题数据baseline指标改进失败样本报告
不要一开始就冲复杂模型。没有 baseline、指标和失败分析的项目,只是一次演示性运行。
保留一份实验记录
Section titled “保留一份实验记录”创建 ml_project_log_first_loop.py。这不是模型,而是每个模型项目都需要的习惯。
experiments = [ {"version": "v1_baseline", "metric": 0.72, "change": "default model"}, {"version": "v2_features", "metric": 0.78, "change": "add ratio features"}, {"version": "v3_tuned", "metric": 0.80, "change": "tune max_depth"},]
best = max(experiments, key=lambda row: row["metric"])
print("best_version:", best["version"])print("best_metric:", best["metric"])print("next_step: inspect failure cases before adding more models")预期输出:
best_version: v3_tunedbest_metric: 0.8next_step: inspect failure cases before adding more models这一步是在转换思维:从“我跑了模型”变成“我能比较版本并解释下一步”。
按这个顺序学
Section titled “按这个顺序学”| 顺序 | 阅读 | 交付什么 |
|---|---|---|
| 1 | 5.6.2 房价预测 | 回归 baseline 和改进 |
| 2 | 5.6.3 客户流失预测 | 分类指标和阈值思维 |
| 3 | 5.6.4 用户分群 | 聚类解释和业务标签 |
| 4 | 5.6.5 Kaggle 实践 | 真实提交流程 |
| 5 | 5.6.6 ML 实操工作坊 | 一份完整证据包演练 |
工作坊放在最后,因为它把前面项目习惯整理成一份可复现证据包。
项目交付物标准
Section titled “项目交付物标准”
至少为一个项目保留这些文件:README.md、运行命令、指标表、实验记录、一个失败样本、一张图、下一步计划。
统一项目证据包
Section titled “统一项目证据包”每个 ch05 项目都按同一套证据包收尾,方便横向比较:
| 证据 | 必须包含什么 |
|---|---|
| baseline | 最简单可复现模型、固定划分、初始指标 |
| metric table | 至少包含 baseline、一次改进、最终选择 |
| failure samples | 至少 3 个错误样本或弱分群,并写明失败原因 |
| leakage check | 说明目标泄漏、时间泄漏或重复样本是否排查过 |
| next action | 下一轮只改一个变量:数据、特征、模型、阈值或调参 |
没有失败样本的项目还不算完成。模型项目真正有价值的地方,不只是“分数多少”,而是你能解释它在哪里不可靠,以及下一步准备怎样验证。
能说清:我如何定义任务、用了什么 baseline、信任哪个指标、哪里变好了、模型在哪里失败、下一步做什么,就算通过。
检查思路与讲解
- 完整回答要先定义任务类型、目标列和成功指标,再讨论模型名称。
- baseline 应该是最简单、可复现的一版:固定划分、最少预处理、一个模型和一张指标表。
- 改进必须和同一个划分或验证方案比较。一次同时改划分和模型,结果就很难解释。
- 失败分析至少要指出一个模型较弱的样本类型或业务分段,并把它变成下一轮受控实验。
- 合格的项目文件夹应该包含运行命令、README、实验日志、指标表、图表、失败样本和下一步计划。
学完这一页,至少保留这张证据卡:
- 项目目标
- 预测、分割、Kaggle,或端到端 ML 作品集目标
- 流水线
- 数据划分、预处理、模型、评估和报告工件
- 结果
- 指标表、图表、预测、失败样本和 README 说明
- 失败检查
- 运行不可复现、泄漏、过拟合、基线薄弱或缺少部署边界
- 期望产出
- 包含流水线、指标和失败复盘的 ML 项目文件夹