3.3.8 数据合并
- 掌握
merge(SQL 风格连接) - 了解
join(基于索引的连接) - 掌握
concat(拼接操作) - 理解不同合并策略的选择
先建立一张地图
Section titled “先建立一张地图”数据合并更适合按“有没有共同键”来理解:
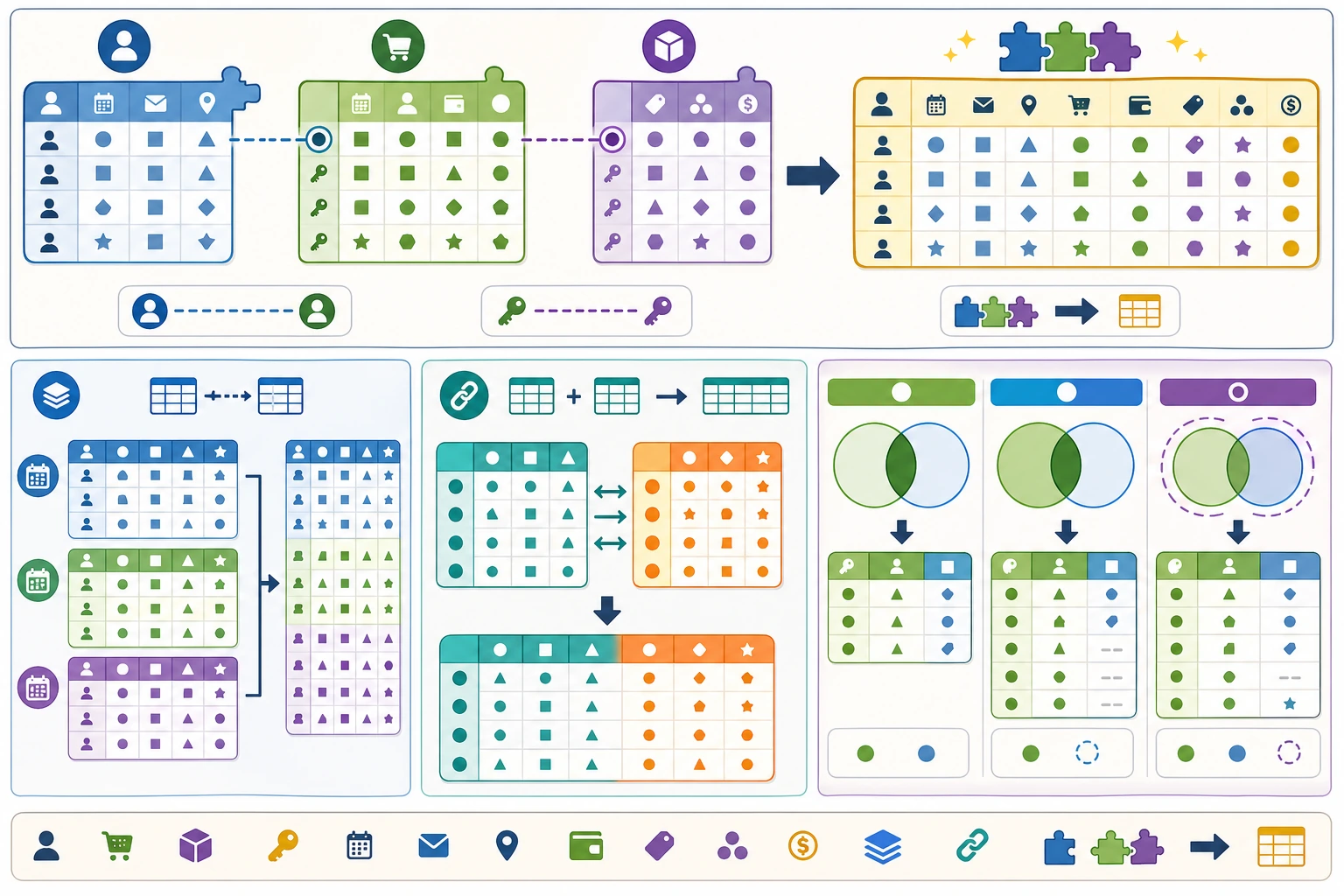
所以这节真正想解决的是:
- 你脑子里什么时候该先想到
merge - 什么时候只是普通拼接
为什么需要合并数据?
Section titled “为什么需要合并数据?”真实的数据往往分散在多张表中。比如一个电商系统可能有:
- 用户表:用户ID、姓名、注册时间
- 订单表:订单ID、用户ID、商品、金额
- 商品表:商品ID、名称、类别、价格
要分析”每个用户买了什么商品”,就需要把这些表合并起来。
flowchart LR A["用户表"] --> D["合并后的完整数据"] B["订单表"] --> D C["商品表"] --> D
style D fill:#4caf50,color:#fff一个更适合新人的总类比
Section titled “一个更适合新人的总类比”你可以把数据合并理解成:
- 把来自不同表格的线索对到同一个人或同一笔记录身上
也就是说:
merge更像按身份证号把两份档案对齐concat更像把两张表上下或左右拼起来
这个类比很重要,因为它会帮你先分清:
- “对齐”
- 和“拼接”
这两件事其实不是一回事。
merge:SQL 风格连接
Section titled “merge:SQL 风格连接”merge 是最强大的合并方式,类似 SQL 的 JOIN。
准备示例数据
Section titled “准备示例数据”import pandas as pd
# 用户表users = pd.DataFrame({ "用户ID": [1, 2, 3, 4], "姓名": ["张三", "李四", "王五", "赵六"], "城市": ["北京", "上海", "广州", "深圳"]})
# 订单表orders = pd.DataFrame({ "订单ID": [101, 102, 103, 104, 105], "用户ID": [1, 2, 1, 3, 5], # 注意:用户5不在用户表中 "商品": ["手机", "电脑", "耳机", "平板", "键盘"], "金额": [5999, 8999, 299, 3999, 199]})内连接(inner join)
Section titled “内连接(inner join)”只保留两边都有的:
result = pd.merge(users, orders, on="用户ID", how="inner")print(result)# 用户ID 姓名 城市 订单ID 商品 金额# 0 1 张三 北京 101 手机 5999# 1 1 张三 北京 103 耳机 299# 2 2 李四 上海 102 电脑 8999# 3 3 王五 广州 104 平板 3999# 用户4(赵六)没有订单 → 不出现# 用户5 不在用户表 → 不出现左连接(left join)
Section titled “左连接(left join)”保留左表所有行:
result = pd.merge(users, orders, on="用户ID", how="left")print(result)# 用户ID 姓名 城市 订单ID 商品 金额# 0 1 张三 北京 101.0 手机 5999.0# 1 1 张三 北京 103.0 耳机 299.0# 2 2 李四 上海 102.0 电脑 8999.0# 3 3 王五 广州 104.0 平板 3999.0# 4 4 赵六 深圳 NaN NaN NaN ← 赵六没有订单,用 NaN 填充右连接(right join)
Section titled “右连接(right join)”保留右表所有行:
result = pd.merge(users, orders, on="用户ID", how="right")print(result)# 用户5 出现了(姓名和城市为 NaN)外连接(outer join)
Section titled “外连接(outer join)”保留两边所有行:
result = pd.merge(users, orders, on="用户ID", how="outer")print(result)# 所有用户和所有订单都出现,缺失的用 NaN 填充四种连接方式对比
Section titled “四种连接方式对比”| 连接方式 | 保留 ID | 含义 |
|---|---|---|
inner | {1,2,3} | 两边都有的行 |
left | {1,2,3,4} | 左表全部,加上右表匹配信息 |
right | {1,2,3,5} | 右表全部,加上左表匹配信息 |
outer | {1,2,3,4,5} | 全部保留 |
一个很适合初学者先记的选择表
Section titled “一个很适合初学者先记的选择表”| 你的目的 | 更稳的第一反应 |
|---|---|
| 只保留两边都对得上的记录 | inner merge |
| 以左表为主,把右表信息补进来 | left merge |
| 两边都想保留,缺的补 NaN | outer merge |
| 只是把几张表上下接起来 | concat(axis=0) |
| 只是把几列左右拼起来 | concat(axis=1) |
这张表很适合新人,因为它会把“连接方式很多”重新压回几个最常见的业务目的。
不同列名的合并
Section titled “不同列名的合并”# 如果两表的连接列名不同df1 = pd.DataFrame({"user_id": [1, 2], "name": ["A", "B"]})df2 = pd.DataFrame({"uid": [1, 2], "score": [90, 85]})
result = pd.merge(df1, df2, left_on="user_id", right_on="uid")print(result)# 按多个列匹配result = pd.merge(df1, df2, on=["col1", "col2"])concat:拼接操作
Section titled “concat:拼接操作”concat 用于将多个 DataFrame 纵向或横向拼接(不需要共同的 key):
第一次学 concat,最该先记什么?
Section titled “第一次学 concat,最该先记什么?”最值得先记的是:
concat不是在“对齐键”,而是在“拼接表”。
所以如果你脑子里想的是:
- 用户ID 对不对得上
那通常更该先想到的是:
merge
纵向拼接(上下叠加)
Section titled “纵向拼接(上下叠加)”# 1 月和 2 月的销售数据jan = pd.DataFrame({ "商品": ["苹果", "牛奶"], "销量": [100, 80], "月份": ["1月", "1月"]})
feb = pd.DataFrame({ "商品": ["苹果", "面包"], "销量": [120, 90], "月份": ["2月", "2月"]})
# 上下拼接all_sales = pd.concat([jan, feb], ignore_index=True)print(all_sales)# 商品 销量 月份# 0 苹果 100 1月# 1 牛奶 80 1月# 2 苹果 120 2月# 3 面包 90 2月info = pd.DataFrame({"姓名": ["张三", "李四"], "年龄": [22, 25]})scores = pd.DataFrame({"数学": [90, 85], "英语": [88, 92]})
# 左右拼接combined = pd.concat([info, scores], axis=1)print(combined)# 姓名 年龄 数学 英语# 0 张三 22 90 88# 1 李四 25 85 92merge vs concat vs join
Section titled “merge vs concat vs join”| 方法 | 适用场景 | 类比 |
|---|---|---|
merge | 按共同列连接两表 | SQL JOIN |
concat | 简单的上下/左右拼接 | 胶水粘合 |
join | 按索引连接 | 特殊的 merge |
flowchart TD A["我要合并数据"] --> B{"有共同的 key 列吗?"} B -->|"有"| C["用 merge"] B -->|"没有,只是简单叠加"| D{"上下叠加还是左右?"} D -->|"上下"| E["concat(axis=0)"] D -->|"左右"| F["concat(axis=1)"]一个新人可直接照抄的数据合并检查表
Section titled “一个新人可直接照抄的数据合并检查表”第一次做多表题时,最稳的检查表通常是:
- 我有没有共同键?
- 键的类型和取值范围一致吗?
- 合并后行数为什么会变多或变少?
- 现在更像“对齐”,还是更像“拼接”?
只要这 4 个问题先想清楚,很多 merge / concat 题就不会再像黑魔法。
实战:多表合并分析
Section titled “实战:多表合并分析”import pandas as pd
# 创建三张表# 任务表tasks = pd.DataFrame({ "任务 ID": [1, 2, 3, 4, 5], "功能": ["登录 API", "RAG 演示", "图表视图", "部署脚本", "评估报告"], "模块": ["后端", "AI", "前端", "运维", "AI"]})
# 工时记录表(某些任务可能有多条工作记录)work_logs = pd.DataFrame({ "任务 ID": [1, 1, 2, 2, 3, 3, 4, 4, 5, 5], "阶段": ["设计", "构建", "设计", "构建", "设计", "构建", "构建", "验证", "设计", "验证"], "小时": [2.0, 5.0, 3.0, 6.5, 1.5, 4.0, 3.5, 1.0, 2.5, 2.0]})
# 模块负责人表modules = pd.DataFrame({ "模块": ["后端", "AI", "前端", "运维"], "负责人": ["Mina", "Kai", "Riley", "Noah"], "冲刺目标": ["稳定 API", "可溯源回答", "清晰界面", "可复现发布"]})
# 合并 1:任务 + 工时记录task_logs = pd.merge(tasks, work_logs, on="任务 ID")print(task_logs.head())
# 合并 2:再加上模块负责人full = pd.merge(task_logs, modules, on="模块")print(full.head())
# 分析:每个模块的平均工时print(full.groupby(["模块", "负责人"])["小时"].mean())
# 分析:每个任务的总工时排名total_hours = full.groupby(["任务 ID", "功能"])["小时"].sum().reset_index()total_hours["排名"] = total_hours["小时"].rank(ascending=False, method="dense")print(total_hours.sort_values("排名"))学完这一页,至少保留这张证据卡:
- 数据框状态
- 列、数据类型、行数、缺失值和样本行
- 操作
- 读/写、select/filter、清洗、转换、groupby、merge,或时间序列步骤
- 输出
- 结果表、保存的文件、聚合、连接结果,或时间索引视图
- 失败检查
- dtype 不匹配、缺失数据、重复键、链式赋值或时间频率错误
- 期望产出
- 前后对比表格样本,以及转换原因
| 操作 | 函数 | 关键参数 |
|---|---|---|
| SQL 风格连接 | pd.merge() | on, how (inner/left/right/outer) |
| 纵向拼接 | pd.concat(axis=0) | ignore_index=True |
| 横向拼接 | pd.concat(axis=1) | |
| 索引连接 | df.join() | how |
这节最该带走什么
Section titled “这节最该带走什么”merge是按共同键对齐,concat是把表拼起来- 先问“有没有共同键”,通常就知道该先用哪种方法
- 多表分析里,很多问题不是后面的统计错,而是一开始就没对齐好
练习 1:基本 merge
Section titled “练习 1:基本 merge”# 有两张表:员工表和部门表# 1. 用 inner join 合并# 2. 用 left join 找出没有分配部门的员工# 3. 用 outer join 找出没有员工的部门练习 2:多表合并分析
Section titled “练习 2:多表合并分析”# 创建:商品表、订单表、客户表# 1. 三表合并成一张完整的表# 2. 分析每个客户购买了哪些类别的商品# 3. 找出购买金额最高的 Top 3 客户练习 3:concat 拼接
Section titled “练习 3:concat 拼接”# 有 4 个季度的销售数据(4 个独立的 DataFrame)# 1. 纵向拼接成全年数据# 2. 添加"季度"列标识数据来源# 3. 统计全年各季度的销售趋势参考实现与讲解
- 只需要匹配键时用
innerjoin;左表是事实来源时用leftjoin;要检查两边不匹配记录时用outerjoin。 - 合并前先检查重复键,并判断关系是一对一、一对多还是多对多。能用时加上
validate=,让 Pandas 帮你抓到意外重复。 - 每次 merge 后都要比较行数,检查合并列里的 null,并抽样查看未匹配键。只有把这些检查写下来,合并才算完成。