6.8.2 项目:图像分类系统
- 定义边界清晰的分类任务。
- 组织 train/validation/test 证据。
- 跑一个能产生预测的极小基线。
- 构建混淆矩阵并提取错误样本。
- 知道真实 CNN 或 transfer-learning 项目应该展示什么。
先看项目闭环
Section titled “先看项目闭环”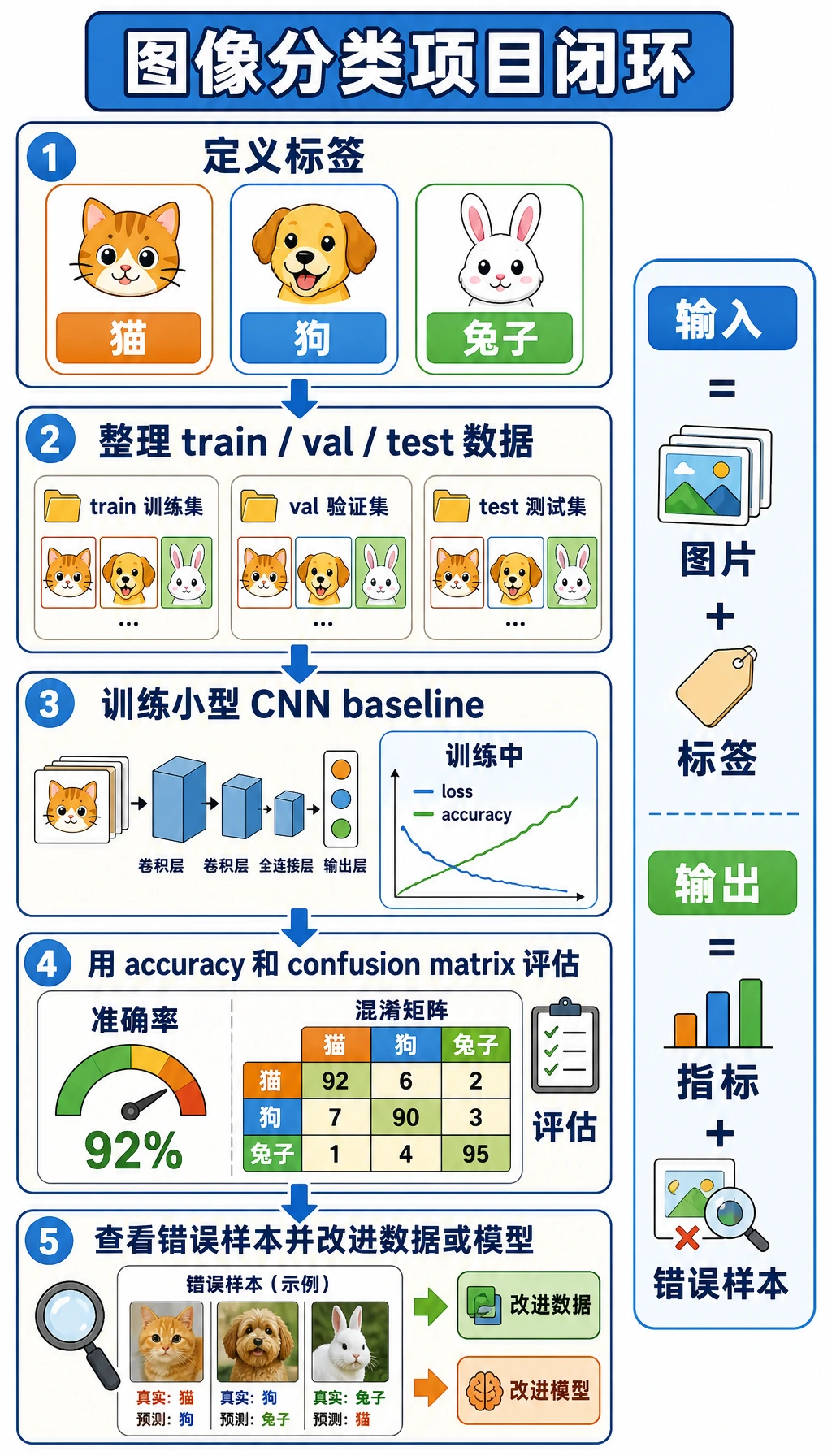
labelsdata splitbaselinemetricserror casesnext data/model action
选题要满足:
- 类别边界清楚;
- 数据真的能收集到;
- 错误可以解释。
不要一开始就做几百个细分类别,也不要选择人类都难以一致标注的标签。
项目计划模板
Section titled “项目计划模板”from dataclasses import dataclass, field
@dataclassclass CVProjectPlan: name: str classes: list[str] dataset_split: dict[str, int] baseline: str metrics: list[str] risks: list[str] = field(default_factory=list)
plan = CVProjectPlan( name="pet_image_classifier", classes=["cat", "dog", "rabbit"], dataset_split={"train": 900, "val": 180, "test": 180}, baseline="small_cnn_then_transfer_learning", metrics=["accuracy", "confusion_matrix", "error_cases"], risks=["class imbalance", "background leakage", "label noise"],)
print(plan)这个对象是项目边界。如果你填不出来,说明还没到选模型的时候。
实验:原型基线与混淆矩阵
Section titled “实验:原型基线与混淆矩阵”这个 toy 示例用三个伪特征代替真实图片。它训练的是之后 CNN 项目也要用的评估闭环。
创建 image_project_baseline.py:
from collections import defaultdict
train_data = [ ("cat", [0.9, 0.8, 0.4]), ("cat", [0.8, 0.7, 0.5]), ("dog", [0.7, 0.5, 0.8]), ("dog", [0.6, 0.4, 0.9]), ("rabbit", [0.5, 0.9, 0.3]), ("rabbit", [0.4, 0.8, 0.2]),]
val_data = [ ("cat", [0.85, 0.75, 0.45]), ("dog", [0.65, 0.45, 0.85]), ("rabbit", [0.45, 0.85, 0.25]), ("dog", [0.82, 0.72, 0.42]),]
labels = ["cat", "dog", "rabbit"]
def prototypes(data): groups = defaultdict(list) for label, features in data: groups[label].append(features)
result = {} for label, rows in groups.items(): result[label] = [ round(sum(row[i] for row in rows) / len(rows), 3) for i in range(len(rows[0])) ] return result
def l1(a, b): return sum(abs(x - y) for x, y in zip(a, b))
def predict(features, protos): distances = {label: round(l1(features, proto), 3) for label, proto in protos.items()} pred = min(distances, key=distances.get) return pred, distances
protos = prototypes(train_data)print("prototypes")for label in labels: print(label, protos[label])
rows = []for gold, features in val_data: pred, distances = predict(features, protos) rows.append({"gold": gold, "pred": pred}) print("prediction", gold, "->", pred, distances)
cm = {g: {p: 0 for p in labels} for g in labels}for row in rows: cm[row["gold"]][row["pred"]] += 1
print("confusion_matrix")for gold in labels: print(gold, [cm[gold][p] for p in labels])
errors = [row for row in rows if row["gold"] != row["pred"]]print("accuracy:", round((len(rows) - len(errors)) / len(rows), 3))print("errors:", errors)运行:
python image_project_baseline.py预期输出:
prototypescat [0.85, 0.75, 0.45]dog [0.65, 0.45, 0.85]rabbit [0.45, 0.85, 0.25]prediction cat -> cat {'cat': 0.0, 'dog': 0.9, 'rabbit': 0.7}prediction dog -> dog {'cat': 0.9, 'dog': 0.0, 'rabbit': 1.2}prediction rabbit -> rabbit {'cat': 0.7, 'dog': 1.2, 'rabbit': 0.0}prediction dog -> cat {'cat': 0.09, 'dog': 0.87, 'rabbit': 0.67}confusion_matrixcat [1, 0, 0]dog [1, 1, 0]rabbit [0, 0, 1]accuracy: 0.75errors: [{'gold': 'dog', 'pred': 'cat'}]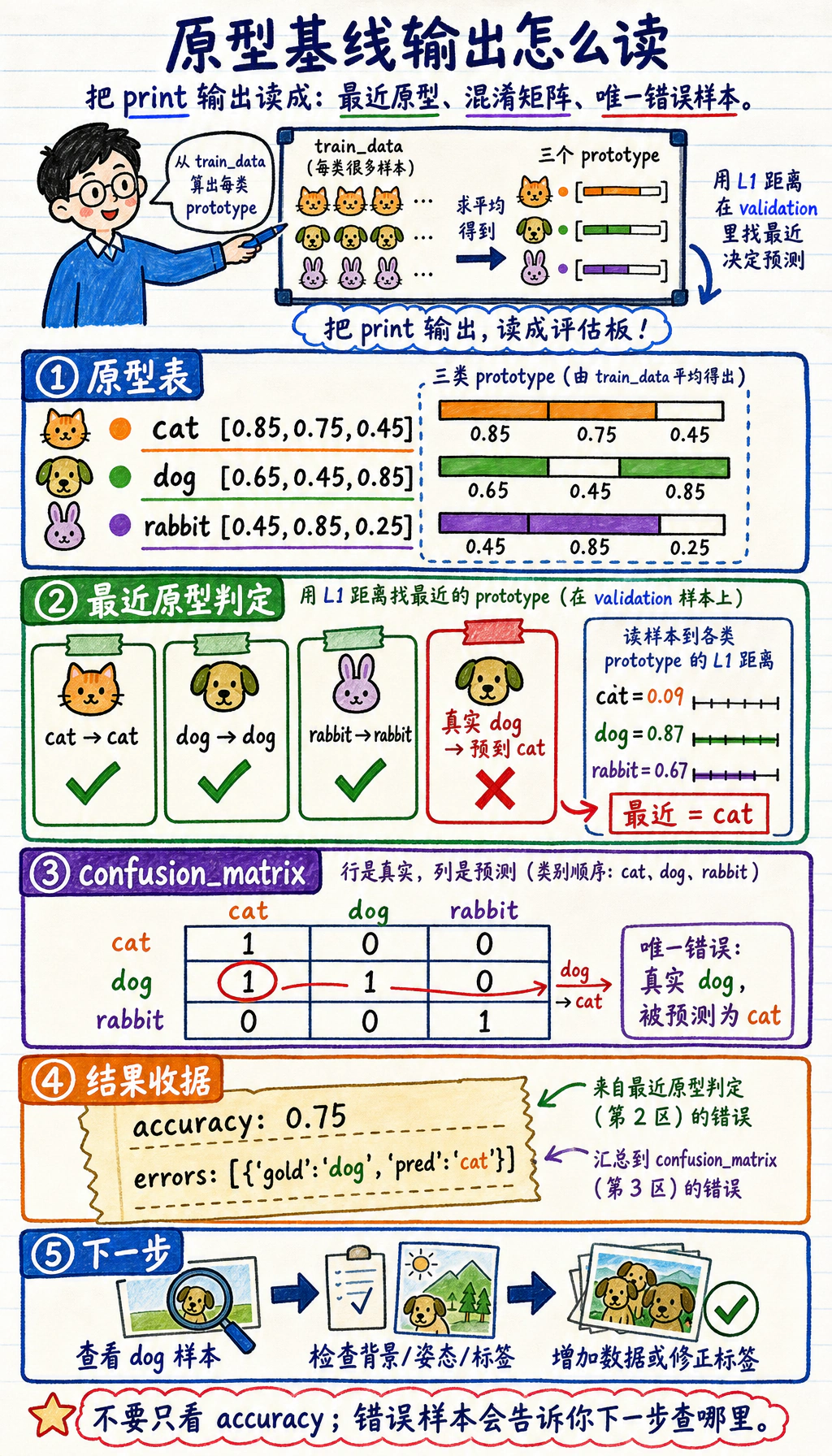
读这个错误:
- 最后一个
dog样本更接近cat原型; - 混淆矩阵显示
dog -> cat; - 下一步不要立刻换大模型,先检查 dog 图片是否有像 cat 的背景、姿态或标签问题。
真实项目升级路线
Section titled “真实项目升级路线”| 版本 | 增加什么 | 展示证据 |
|---|---|---|
| 基线 | small CNN 或迁移学习基线 | train/val 曲线、accuracy |
| 评估 | 混淆矩阵和错误样本 | 类别级错误 |
| 鲁棒性 | augmentation 和 leakage 检查 | 前后对比 |
| 作品集 | README 和演示命令 | 可复现运行 |
真实 CNN 项目至少保留:
- 数据目录截图或类别数量表;
- train/validation/test 划分规则;
- 基线模型摘要;
- 指标表;
- 混淆矩阵;
- 6 到 12 个正确和错误样本;
- 下一步计划。
图像分类项目至少留下这些证据:
- 标签规则
- 类别如何定义
- 拆分规则
- 训练/验证/测试和防止数据泄漏
- 基线
- 简单的 CNN 或迁移学习基线
- 指标
- 准确率加混淆矩阵
- 错误案例
- 一个错误预测及其可能原因
- 下一步动作
- 数据、增强、模型或划分改动
| 错误 | 修复 |
|---|---|
| 只报告 accuracy | 展示混淆矩阵和错误样本 |
| 类别定义模糊 | 收集数据前先定义标签边界 |
| 相似图片泄漏到 train/test | 必要时按来源或主体划分 |
| 一开始就上大模型 | 先做小基线 |
| 隐藏失败样本 | 用失败样本说明下一步改进 |
- 增加两个
dogvalidation 样本,再重跑 confusion matrix。 - 增加新类别
hamster。labels和 matrix 要怎么变? - 为
dog -> cat错误写一个可能的数据原因。 - 在 README 中把 prototype baseline 替换成 small CNN outline。
- 做一个项目 checklist,包含 dataset、command、metric 和 failure cases。
项目交付参考与讲解
- confusion matrix 的
dog行会有更多证据。如果新增样本更难,dog recall 可能下降;如果新增样本很清晰,评估会更稳定。 labels需要加入hamster,confusion matrix 会多一行一列。所有按类别平均的指标表也要包含新类别。- 可能原因包括 dog 图片裁剪过度、模糊、姿态像 cat,或 dog 样本太少。关键是把错误和数据证据连起来,而不是只怪模型。
- README 中有用的 outline 应包含输入尺寸、convolution/ReLU/pooling blocks、classifier head、loss、metric、运行命令和预期输出。
- checklist 要证明项目可复现:dataset split、training command、metric、confusion matrix、known failure cases 和下一步改进。
- 图像分类项目看的是完整闭环,不只是模型名。
- Confusion matrix 能显示类别级失败。
- 错误样本是项目证据,不是丢脸内容。
- 强作品集项目会展示哪里改进了,哪里仍然失败。