12.3.3 语音合成
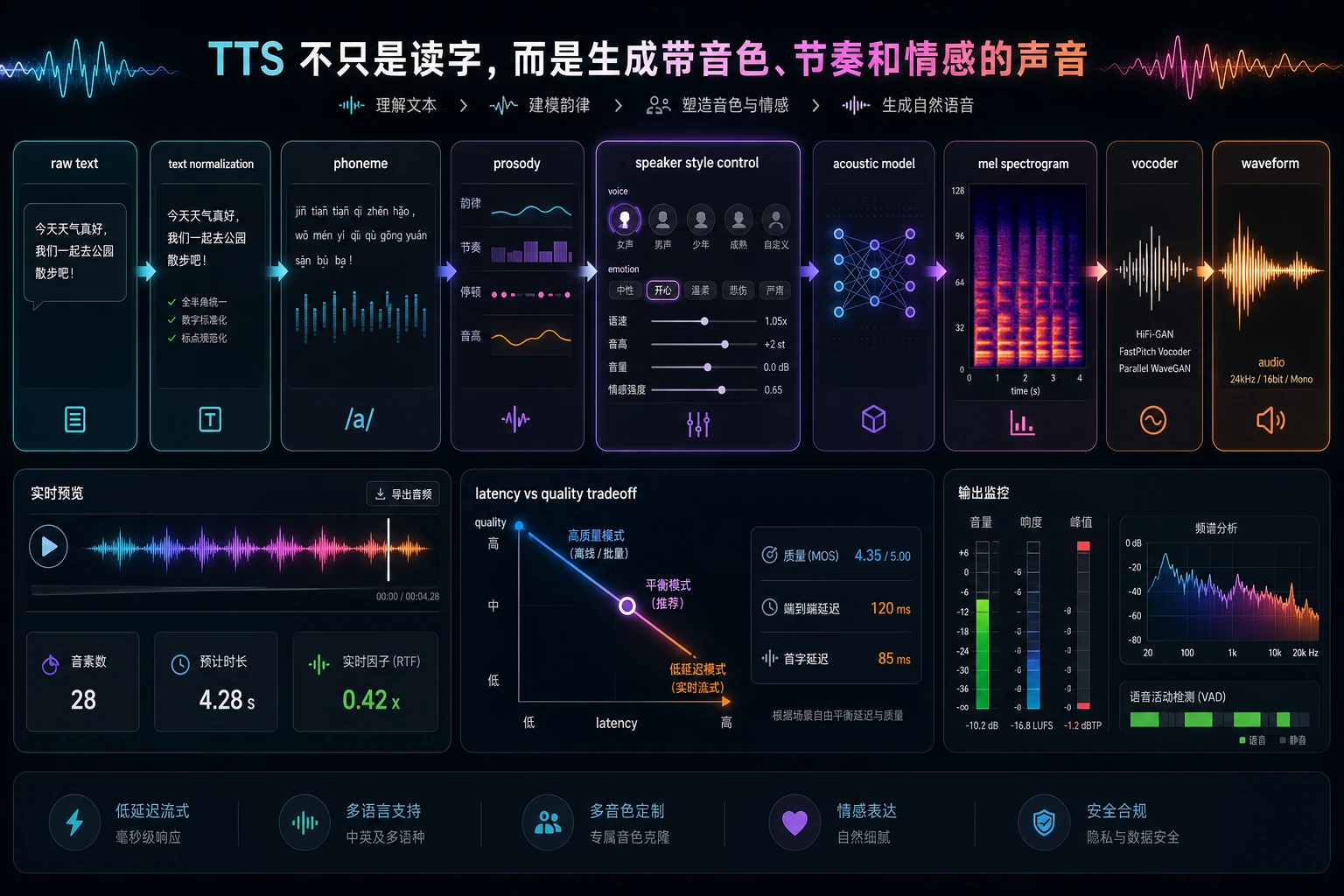
- 理解语音合成为什么比“文本转声音文件”复杂得多
- 理解 TTS 系统通常要拆成哪些模块
- 看懂一个最小的文本到语音流程示意
- 理解多说话人、情感控制和语音克隆分别在解决什么问题
先建立一张地图
Section titled “先建立一张地图”TTS 这节最适合新人的理解顺序不是“文字直接变声音”,而是先看清:
flowchart LR A["文本"] --> B["文本处理"] B --> C["声学表示"] C --> D["Vocoder"] D --> E["波形音频"]所以这节真正想解决的是:
- 为什么 TTS 是多阶段生成任务
- 为什么它既像语言任务,也像音频生成任务
一个更适合新人的总类比
Section titled “一个更适合新人的总类比”你可以把 TTS 理解成:
- 一位配音演员在录音棚里工作
他不是只看文字就机械念出来, 还会自然处理:
- 哪里停顿
- 哪个词要重读
- 语气该平静还是兴奋
这个类比很适合新人,因为它会帮助你先抓住:
- TTS 的真正目标不是“发出声音”
- 而是“发出像人在说话的声音”
一、语音合成到底在做什么?
Section titled “一、语音合成到底在做什么?”不是简单把字一个个读出来
Section titled “不是简单把字一个个读出来”如果你真的机械地把文字逐个字念出来,结果通常会非常生硬。 自然语音里包含的东西远比“文字内容”多,例如:
- 断句
- 重音
- 语气
- 说话速度
- 情绪
所以 TTS 的真正问题不是:
“能不能发出声音”
而是:
“能不能发出像人说话那样的声音”
一个很重要的直觉
Section titled “一个很重要的直觉”语音合成本质上是在做:
- 文本理解
- 发音建模
- 声学特征生成
- 波形重建
也就是说,它不是一层转换,而是一个多阶段生成问题。
二、一个最小 TTS 流程长什么样?
Section titled “二、一个最小 TTS 流程长什么样?”可以先把它粗略理解成这几步:
- 文本预处理
- 生成中间声学表示
- 通过声码器变成波形
flowchart LR A["文本"] --> B["文本处理 / 编码"] B --> C["声学表示"] C --> D["声码器 Vocoder"] D --> E["波形音频"]
style A fill:#e3f2fd,stroke:#1565c0,color:#333 style B fill:#fff3e0,stroke:#e65100,color:#333 style C fill:#f3e5f5,stroke:#6a1b9a,color:#333 style D fill:#fffde7,stroke:#f9a825,color:#333 style E fill:#e8f5e9,stroke:#2e7d32,color:#333这个流程图最重要的作用是让你先建立一个正确认知:
语音合成不是一步,而是多层管线。
一个很适合初学者先记的模块表
Section titled “一个很适合初学者先记的模块表”| 模块 | 最值得先记住的作用 |
|---|---|
| 文本处理 | 把文字整理成更适合发音的表示 |
| 声学表示 | 描述“应该怎么说” |
| Vocoder | 把声学表示真正变成波形 |
这个表很适合新人,因为它会把 TTS 从“一个黑盒”重新拆成三层比较清楚的职责。
三、为什么文本处理这一步不能省?
Section titled “三、为什么文本处理这一步不能省?”因为文字本身并不等于发音信息
Section titled “因为文字本身并不等于发音信息”例如同样一句话,不同场景下停顿和语气可能不同:
- “你来了。”
- “你来了?”
仅仅字面很像,但语音表达完全不同。
文本处理通常在做什么?
Section titled “文本处理通常在做什么?”- 分词 / 音素映射
- 数字读法转换
- 标点和停顿处理
- 语气特征提示
也就是说,TTS 系统首先要把“文字”翻译成“更接近发音的表示”。
四、声学表示是什么?
Section titled “四、声学表示是什么?”为什么不直接从文字到波形?
Section titled “为什么不直接从文字到波形?”直接从文本一步生成波形是很难的,因为波形非常长、非常细、非常敏感。
所以很多 TTS 系统会先生成一种中间表示,例如:
- mel spectrogram(梅尔频谱)
你可以先把它理解成:
声音的一张“频率热力图”。
一个直觉示意
Section titled “一个直觉示意”tts_pipeline = { "input": "你好,欢迎来到 AI 全栈课程。", "intermediate": "mel_spectrogram", "output": "waveform"}
print(tts_pipeline)预期输出:
{'input': '你好,欢迎来到 AI 全栈课程。', 'intermediate': 'mel_spectrogram', 'output': 'waveform'}关键是中间层。很多 TTS 系统会先把文本变成声学表示,再由后续模块生成真正能播放的音频。

这个例子虽然只是结构示意,但它已经说明:
- 文本不是直接变成声音
- 中间还有一层更适合建模的表示
五、Vocoder(声码器)在做什么?
Section titled “五、Vocoder(声码器)在做什么?”它的角色很像“把频谱翻译成真正能听的声音”
Section titled “它的角色很像“把频谱翻译成真正能听的声音””如果说前面模块生成的是一种“声学蓝图”,那 vocoder 就负责把蓝图真正变成波形。
一个很实用的理解
Section titled “一个很实用的理解”可以先记成:
- 声学模型:决定“该说成什么样”
- Vocoder:决定“怎样把它真的发出来”
这两个模块经常会分别设计和优化。
六、一个最小“多说话人控制”示意
Section titled “六、一个最小“多说话人控制”示意”很多现代语音合成系统不只会“读文字”,还会控制:
- 说话人
- 语速
- 情绪
例如:
tts_config = { "text": "欢迎来到课程学习。", "speaker": "female_voice_01", "speed": 1.0, "emotion": "neutral"}
print(tts_config)预期输出:
{'text': '欢迎来到课程学习。', 'speaker': 'female_voice_01', 'speed': 1.0, 'emotion': 'neutral'}这是你应该记住的实用输入形态:TTS 请求通常会把句子和“怎么说”的控制参数放在一起。

这个例子在展示什么?
Section titled “这个例子在展示什么?”它在展示一个很重要的初学者概念:
TTS 的输入经常不只是文本,还会包括“怎么说”的控制条件。
这也是现代语音合成比早期系统更强大的地方之一。
一个很适合初学者先记的选择表
Section titled “一个很适合初学者先记的选择表”| 用户需求 | TTS 系统更该优先控制什么 |
|---|---|
| 想换音色 | speaker |
| 想更快或更慢 | speed |
| 想更像客服或播音 | style / emotion |
| 想模仿某个人 | voice cloning / speaker adaptation |
这个表很适合新人,因为它会把“可控 TTS”重新变成几个具体旋钮。
七、为什么说语音合成比想象中更像生成任务?
Section titled “七、为什么说语音合成比想象中更像生成任务?”因为它也有这些典型生成难点:
- 结果要自然
- 结果要稳定
- 结果要可控
而且它和图像生成一样,也会面临:
- 风格控制
- 个性化
- 质量与速度权衡
所以你可以把 TTS 理解成:
一个音频世界里的生成模型问题。
八、TTS 真实产品里最重要的几个方向
Section titled “八、TTS 真实产品里最重要的几个方向”系统能不能切换不同音色。
情感与韵律控制
Section titled “情感与韵律控制”系统能不能表达:
- 开心
- 冷静
- 严肃
系统能不能学习某个特定人的声音特征。
如果是对话助手,延迟会非常关键。
九、初学者第一次学 TTS 最该先记什么
Section titled “九、初学者第一次学 TTS 最该先记什么”最值得先记住的是:
- 文本不等于发音信息
- 声学表示是中间层,不是可有可无
- Vocoder 决定的是“怎么真正发出来”
十、初学者最常踩的坑
Section titled “十、初学者最常踩的坑”以为 TTS 就是“把字读出来”
Section titled “以为 TTS 就是“把字读出来””实际上它更像“生成自然说话过程”。
只关注音色,不关注节奏和停顿
Section titled “只关注音色,不关注节奏和停顿”很多“不自然”的根源其实在韵律,而不是音色本身。
以为 TTS 天然就是实时的
Section titled “以为 TTS 天然就是实时的”很多高质量模型并不一定能做到很低延迟。
如果把它做成项目或系统设计,最值得展示什么
Section titled “如果把它做成项目或系统设计,最值得展示什么”最值得展示的通常不是:
- “我把文字转成了音频”
而是:
- 文本如何进入 TTS 流程
- 用了哪些控制条件
- 哪一层在决定自然度,哪一层在决定最终音质
- 延迟和质量之间怎么取舍
这样别人会更容易看出:
- 你理解的是 TTS 工作流
- 不只是调了一个配音接口
学完这一页,至少保留这张证据卡:
- 分镜脚本
- 场景列表、时长、镜头/语音/字幕/时间备注
- 资源列表
- 图像、音频、语音、字幕、片段和来源/许可证字段
- 同步检查
- 语音-文本时序、口型同步、镜头连续性或帧一致性
- 失败检查
- 闪烁、身份漂移、音频不匹配、不安全相似度或导出问题
- 期望产出
- 带复查说明的分镜或时间线产物
这一节最重要的不是记住某个 TTS 模型名字,而是建立这个直觉:
语音合成的本质,是把文字和说话控制信息,逐步变成自然、可听、可控的声音波形。
理解了这条主线,后面你再看数字人、配音系统和语音助手时,就会清楚很多。
这节最该带走什么
Section titled “这节最该带走什么”- TTS 不是把文字朗读出来那么简单
- 它本质上是一条文本到声学再到波形的生成链路
- “自然、稳定、可控”比“能发声”更接近真实产品要求
- 用自己的话解释:为什么 TTS 不能简单理解成“把字一个个念出来”?
- 想一想:为什么很多 TTS 系统会把“说话人、语速、情绪”也当作输入?
- 如果你在做实时语音助手,为什么 TTS 延迟会成为关键工程指标?
- 用自己的话说明:声学模型和 vocoder 分别更像在解决什么问题?
解题思路与讲解
- TTS 需要预测发音、停顿、节奏、重音、情绪和声学形态。逐字朗读会忽略韵律,听起来很不自然。
- 说话人、语速和情绪也是输入,因为同一句文本可以有很多合理读法。这些控制项能让系统匹配产品角色、无障碍需求或对话状态。
- 语音助手是交互系统,延迟过高会破坏轮流对话。即使音质很好,如果声音不能快速开始,用户也会感觉系统很慢。
- 声学模型把文本或语言特征映射成语音表示,例如 mel spectrogram;vocoder 再把这个表示转换成可听的 waveform。