8.1.5 检索策略
完成本节后,你将能够:
- 理解检索策略为什么直接决定 RAG 质量
- 分清关键词检索、向量检索和混合检索
- 理解 rerank、查询改写 这些常见增强手段
- 用一个可运行例子体验混合检索的思路
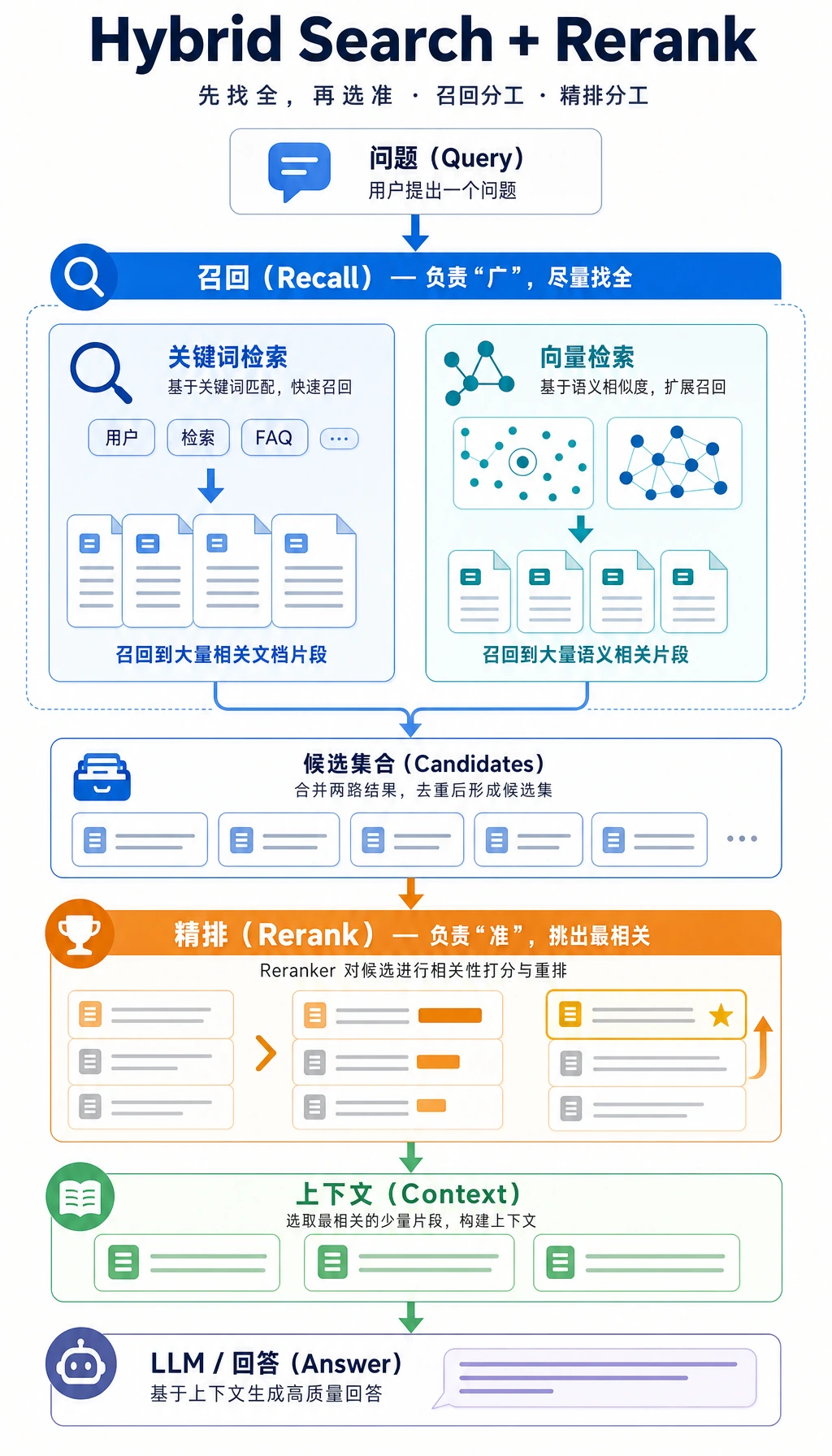
一、检索不是“只有一个 top-k”
Section titled “一、检索不是“只有一个 top-k””关键词检索:适合找明确词项
Section titled “关键词检索:适合找明确词项”关键词检索更像“查目录”。
它擅长:
- 精确术语
- 产品名
- 报错码
- 法条编号
例如用户问:
“错误码 403 是什么?”
这种场景关键词检索往往很强。
向量检索:适合找语义相近内容
Section titled “向量检索:适合找语义相近内容”向量检索更像“按意思找相似”。
它擅长:
- 同义表达
- 改写后的问题
- 用户口语化提问
例如:
“怎么退课?”
和:
“课程购买后 7 天内可申请退款”
虽然词不一样,但向量检索有机会把它们连起来。
二、为什么很多项目最后都走向混合检索?
Section titled “二、为什么很多项目最后都走向混合检索?”因为关键词和语义各有盲区
Section titled “因为关键词和语义各有盲区”只用关键词:
- 容易漏掉语义近但措辞不同的内容
只用向量:
- 有时会忽略特别关键的专有词
所以很多系统会做:
关键词分数 + 向量分数 = 混合分数
这很像“同时看字面和意思”
Section titled “这很像“同时看字面和意思””人类找资料时也会这样:
- 先看有没有明确关键词
- 再判断是不是在说同一件事
混合检索就是把这两种判断合起来。
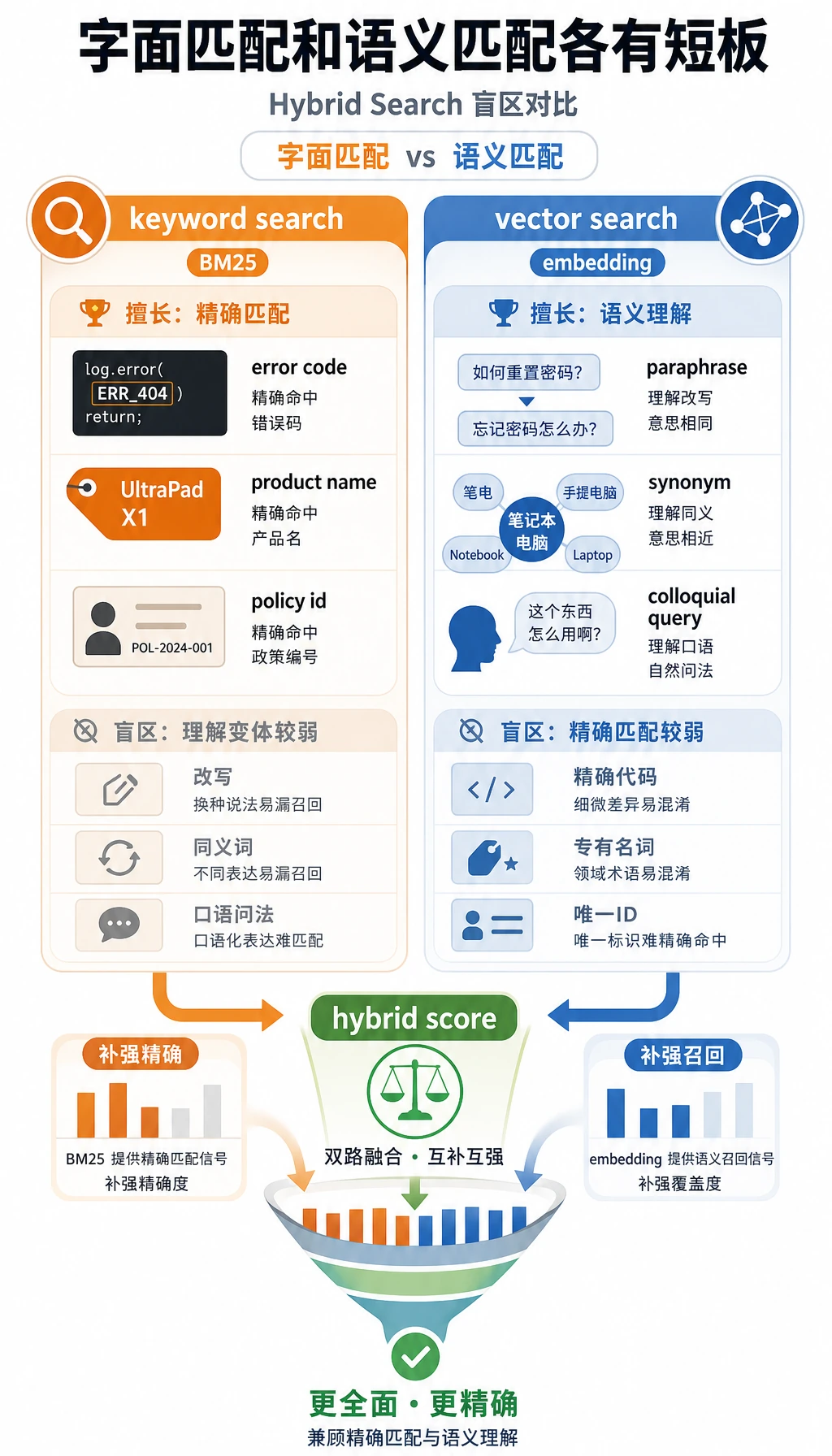
BM25 是一种经典的关键词排序方法。很多混合检索都会把 BM25 风格的分数和向量相似度结合起来,再交给 rerank 做最终排序。
三、一个最小可运行的混合检索示例
Section titled “三、一个最小可运行的混合检索示例”下面这个例子里:
keyword_score模拟关键词匹配vector_score模拟语义相似度- 最后把两者做加权组合
import mathimport refrom collections import Counterimport numpy as np
docs = [ { "id": "d1", "text": "课程购买后 7 天内可申请退款", "vector": np.array([0.95, 0.10, 0.05]) }, { "id": "d2", "text": "完成所有项目并通过测试后可获得证书", "vector": np.array([0.10, 0.95, 0.10]) }, { "id": "d3", "text": "建议先学 Python,再学机器学习和深度学习", "vector": np.array([0.20, 0.30, 0.95]) }]
query = "怎么申请退课退款"query_vector = np.array([0.90, 0.10, 0.10])
def tokenize(text): words = re.findall(r"[a-zA-Z0-9_]+", text.lower()) cjk_chars = re.findall(r"[\u4e00-\u9fff\u3040-\u30ff]", text) cjk_bigrams = ["".join(cjk_chars[i:i + 2]) for i in range(len(cjk_chars) - 1)] return words + cjk_bigrams
def keyword_score(query, text): q = Counter(tokenize(query)) t = Counter(tokenize(text)) return sum(min(q[k], t[k]) for k in q)
def cosine_similarity(a, b): return float(np.dot(a, b) / (np.linalg.norm(a) * np.linalg.norm(b)))
results = []for doc in docs: kw = keyword_score(query, doc["text"]) vec = cosine_similarity(query_vector, doc["vector"]) hybrid = 0.4 * kw + 0.6 * vec results.append((hybrid, kw, vec, doc["id"], doc["text"]))
for hybrid, kw, vec, doc_id, text in sorted(results, reverse=True): print(doc_id, "hybrid=", round(hybrid, 4), "kw=", kw, "vec=", round(vec, 4), "->", text)预期输出:
d1 hybrid= 1.799 kw= 3 vec= 0.9983 -> 课程购买后 7 天内可申请退款d3 hybrid= 0.1977 kw= 0 vec= 0.3295 -> 建议先学 Python,再学机器学习和深度学习d2 hybrid= 0.1337 kw= 0 vec= 0.2228 -> 完成所有项目并通过测试后可获得证书这个例子虽然简化,但已经很接近真实系统的核心思路。
四、Rerank:先粗召回,再精排序
Section titled “四、Rerank:先粗召回,再精排序”为什么要 rerank?
Section titled “为什么要 rerank?”很多系统不会一开始就追求“第一次就排准”,而是:
- 先用较便宜的方法召回一批候选
- 再用更强但更贵的方法重排
这就叫 rerank。
一个直觉比喻
Section titled “一个直觉比喻”像找工作时:
- 第一轮按关键词筛简历
- 第二轮再认真看候选人是否真的合适
RAG 也是一样。
五、查询改写:用户问题往往不够“适合检索”
Section titled “五、查询改写:用户问题往往不够“适合检索””用户提问不一定是好检索词
Section titled “用户提问不一定是好检索词”用户可能会说:
“我这个情况还能退吗?”
但知识库里写的是:
“购买后 7 天内且学习进度低于 20% 可退款”
这时系统常常会先把问题改写得更适合检索。
一个玩具版查询改写
Section titled “一个玩具版查询改写”def rewrite_query(query): rewrite_rules = { "怎么退课": "退款政策 课程取消", "退掉课程": "退款政策 课程取消", "我这个情况还能退吗": "退款条件 购买时间 学习进度", "我想拿证": "证书要求 完成项目 通过测试", "毕业证": "证书要求 完成项目 通过测试", } for phrase, retrieval_query in rewrite_rules.items(): if phrase in query: return retrieval_query return query
queries = ["怎么退课", "我想拿证", "我这个情况还能退吗"]
for q in queries: print(q, "->", rewrite_query(q))预期输出:
怎么退课 -> 退款政策 课程取消我想拿证 -> 证书要求 完成项目 通过测试我这个情况还能退吗 -> 退款条件 购买时间 学习进度注意,改写后的查询不一定要是一句漂亮的自然语言。它的任务是变成更适合检索的关键词组合。
真实系统里,query rewrite 可能由 LLM 来完成。

六、还有哪些常见检索增强策略?
Section titled “六、还有哪些常见检索增强策略?”多查询检索(Multi-查询)
Section titled “多查询检索(Multi-查询)”把一个问题改写成多个等价问法,再分别检索,合并结果。
元数据过滤(Metadata filter)
Section titled “元数据过滤(Metadata filter)”先按业务条件缩小范围,再做语义检索。
父子块检索(Parent-child retrieval)
Section titled “父子块检索(Parent-child retrieval)”先检索小 chunk,再回到更大块或原文段落。
自查询检索(Self-查询 retrieval)
Section titled “自查询检索(Self-查询 retrieval)”让模型自动判断需要哪些过滤条件和检索字段。
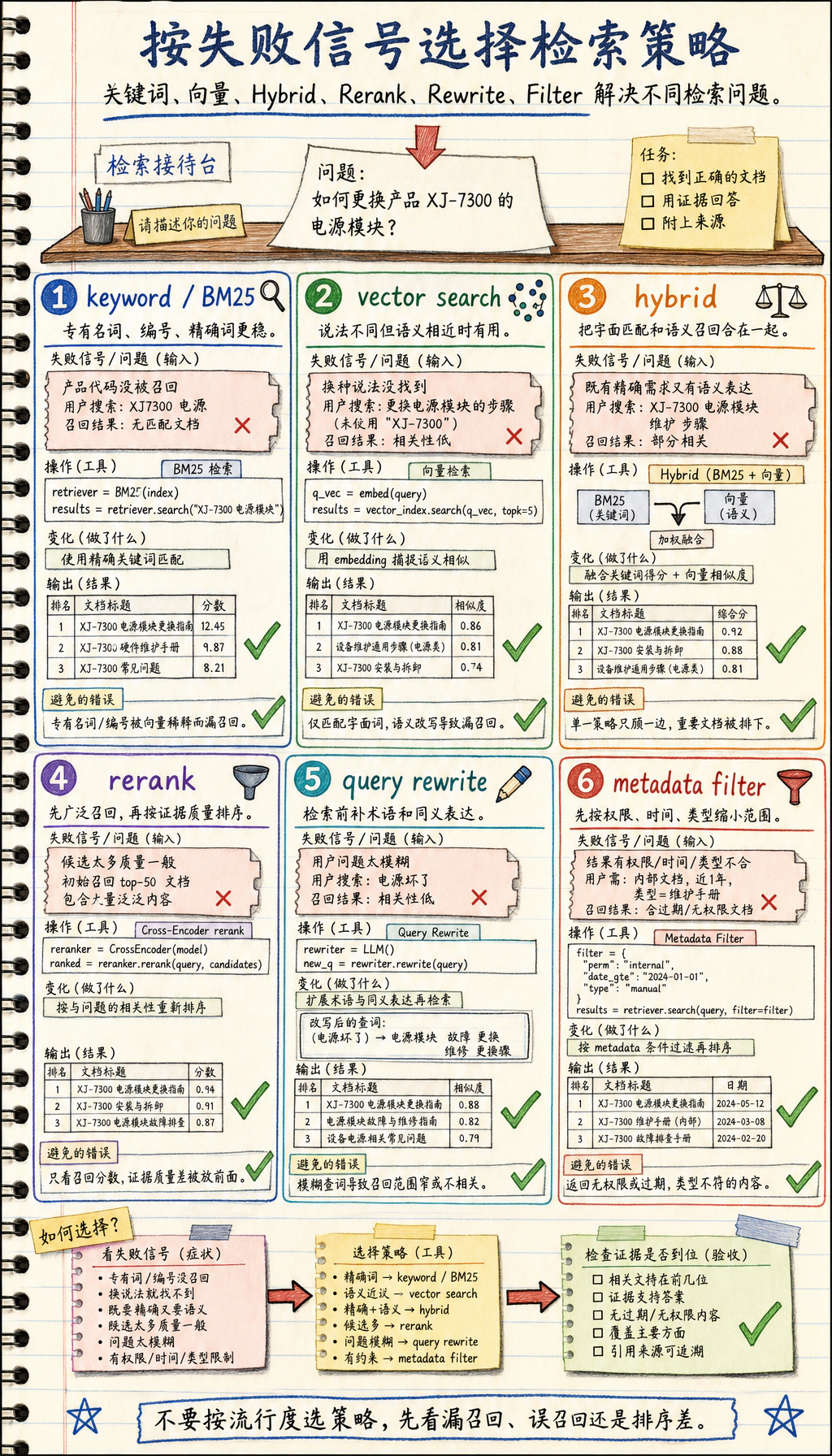
七、怎么选检索策略?
Section titled “七、怎么选检索策略?”如果你有大量专有名词
Section titled “如果你有大量专有名词”更要重视:
- 关键词检索
- 混合检索
- 元数据过滤
如果用户表达特别口语化
Section titled “如果用户表达特别口语化”更要重视:
- 向量检索
- 查询改写
- rerank
如果知识库结构化程度高
Section titled “如果知识库结构化程度高”可以考虑:
- 先路由
- 再定向检索
- 最后重排
八、如果你的目标是“知识库驱动的 SOP 文档助手”,检索策略该怎么想?
Section titled “八、如果你的目标是“知识库驱动的 SOP 文档助手”,检索策略该怎么想?”这类项目里,检索不只是“找到相关内容”, 而是更像在做两层选择:
- 先决定从内部资料找,还是从外部资料补
- 再决定要找政策、处理案例,还是复核清单
所以很适合先把检索条件写成这种样子:
| 条件 | 它在帮你控制什么 |
|---|---|
topic | 当前主题 |
content_type | 政策 / 案例 / 清单 |
source_origin | 内部资料 / 外部资料 |
team | 支持团队或适用对象 |
你可以先把这条线记成一句话:
SOP 文档项目里的检索,不只是“找相关”,而是“按栏目找对证据”。
一个最小过滤示例可以先写成:
items = [ {"topic": "退款升级", "content_type": "policy", "source_origin": "internal", "text": "重复扣费退款必须带交易证据升级处理。"}, {"topic": "退款升级", "content_type": "case", "source_origin": "internal", "text": "客服核对失败结账后的两笔成功扣款,并将案例升级给 billing。"}, {"topic": "退款升级", "content_type": "note", "source_origin": "external", "text": "外部资料补充:支付渠道可能显示临时授权占用。"},]
hits = [ x for x in items if x["topic"] == "退款升级" and x["content_type"] in {"policy", "case"}]
for hit in hits: print(hit)预期输出:
{'topic': '退款升级', 'content_type': 'policy', 'source_origin': 'internal', 'text': '重复扣费退款必须带交易证据升级处理。'}{'topic': '退款升级', 'content_type': 'case', 'source_origin': 'internal', 'text': '客服核对失败结账后的两笔成功扣款,并将案例升级给 billing。'}这个例子特别适合新人,因为它会让你先看到:
- metadata filter 往往比“换更大的模型”更先见效
九、初学者常见误区
Section titled “九、初学者常见误区”只测向量检索,不测关键词检索
Section titled “只测向量检索,不测关键词检索”很多企业场景里,关键词检索并不弱,甚至是基础盘。
检索策略一开始就做太复杂
Section titled “检索策略一开始就做太复杂”建议先从:
- 一个 基线
- 一个明确评估集
- 一次只改一个策略
开始。
只看召回,不看最终回答
Section titled “只看召回,不看最终回答”检索分数高,不代表最终答案一定更好。 因为生成阶段也会影响表现。
检索策略调参表
Section titled “检索策略调参表”调检索时,不要只说“效果不好”,要把现象映射到可以调整的杠杆。
| 现象 | 优先调整 | 为什么 |
|---|---|---|
| 明确术语、报错码搜不到 | 增加关键词检索或混合检索 | 向量检索可能弱化精确词 |
| 用户口语化问题搜不到 | 查询改写、multi-查询、向量检索 | 用户表达和文档表达不一致 |
| top-k 里相关内容排得靠后 | rerank | 粗召回能找到,但排序不够准 |
| 检索结果主题对但版本错 | metadata filter | 需要按版本、日期、来源缩小范围 |
| 答案需要跨多个片段 | parent-child retrieval 或更合理的 chunk | 小 chunk 命中但上下文不足 |
这张表适合和评估集一起使用。每次只改一个策略,然后记录 Hit@k、MRR、引用质量和失败样本变化。
一个检索实验记录模板
Section titled “一个检索实验记录模板”baseline:关键词检索,top-k=3,不 rerank。能命中精确词,但漏掉同义问法,适合报错和术语。exp-1:向量检索,top-k=3,不 rerank。同义问法更好,但专有词有时不准,需要保留关键词通道。exp-2:混合检索,top-k=5,加 rerank。整体质量最好,但延迟增加;如果延迟可接受,可以作为标准版本。
检索优化的关键不是一次找到完美策略,而是让每次改动都有记录、有指标、有失败样本。
学完这一页,至少保留这张证据卡:
- 查询
- 一个用户问题或测试用例
- 已检索分块
- 分块 ID、分数和来源标题
- 答案
- 带引用或来源说明的最终回答
- 失败检查
- 缺少证据、切分错误、文档过时或论断无依据
- 下一步动作
- 分块、embedding、重排、Prompt 或评估改动
这节课最关键的认识是:
RAG 的“找资料”不是机械步骤,而是一个可以不断设计和优化的系统环节。
很多时候,检索策略升级带来的收益,比换一个更大的模型还直接。
- 修改混合检索示例里的权重,比较关键词权重更高和向量权重更高时排序变化。
- 给文档再加一条包含“退课”字样的句子,观察关键词检索优势。
- 自己设计一个更丰富的
rewrite_query()规则表。
参考实现与讲解
- 关键词权重更高时会偏向精确词匹配;向量权重更高时会偏向语义相似。更好的设置取决于用户是使用精确产品术语,还是使用模糊自然语言提问。
- 当精确短语、ID、课程名、政策术语或错误码很重要时,关键词检索很强。它能抓住 embedding 可能“抹平”的细粒度词。
- 有用的 rewrite 表应规范同义词、扩展缩写、把用户说法映射到领域术语,并避免改变用户意图。Rewrite 必须记录日志,因为错误 rewrite 会悄悄毁掉检索。