3.5.3 SQL 基础
- 掌握 SQL 的四大操作:增、删、改、查
- 熟练使用 SELECT 查询语句
- 学会 WHERE 条件过滤
- 掌握 JOIN 多表连接
- 理解 GROUP BY 分组聚合
先建立一张地图
Section titled “先建立一张地图”SQL 最适合新人的理解顺序不是“从头背语法书”,而是先看清:
flowchart LR A["SELECT 选什么"] --> B["FROM 从哪张表来"] B --> C["WHERE 先筛掉什么"] C --> D["GROUP BY 怎么分组"] D --> E["ORDER BY 最后怎么排"]所以这节真正想解决的是:
- SQL 查询在脑子里到底该怎么走
- 为什么它和
Pandas的筛选、分组、合并能对应起来
SQL 是什么?
Section titled “SQL 是什么?”SQL(Structured Query Language,结构化查询语言)是和数据库”对话”的语言。无论你用的是 SQLite、MySQL 还是 PostgreSQL,SQL 语法基本一致。
flowchart LR A["你(人类)"] -->|"写 SQL"| B["数据库引擎"] B -->|"返回结果"| A
style A fill:#e3f2fd,stroke:#1565c0,color:#333 style B fill:#e8f5e9,stroke:#2e7d32,color:#333一个更适合新人的总类比
Section titled “一个更适合新人的总类比”你可以把 SQL 理解成:
- 你在对数据库提问
而这些问题通常都很朴素:
- 我要哪些列?
- 我只要哪些行?
- 我按什么分组?
- 我怎么把两张表接起来?
这个类比很适合新人,因为它会把 SQL 从“另一门语言”重新拉回到“我怎样问表问题”。
准备工作:创建练习数据库
Section titled “准备工作:创建练习数据库”本节所有示例都基于这个练习数据库,请先运行:
import sqlite3
conn = sqlite3.connect(":memory:") # 内存数据库,关闭即消失cursor = conn.cursor()
# 创建用户表cursor.execute(""" CREATE TABLE users ( id INTEGER PRIMARY KEY, name TEXT NOT NULL, age INTEGER, city TEXT, salary REAL )""")
# 创建订单表cursor.execute(""" CREATE TABLE orders ( order_id INTEGER PRIMARY KEY, user_id INTEGER, product TEXT, amount REAL, order_date TEXT, FOREIGN KEY (user_id) REFERENCES users(id) )""")
# 插入用户数据users_data = [ (1, "张三", 28, "北京", 15000), (2, "李四", 35, "上海", 22000), (3, "王五", 22, "广州", 8000), (4, "赵六", 42, "北京", 35000), (5, "钱七", 30, "上海", 18000), (6, "孙八", 26, "深圳", 12000),]cursor.executemany("INSERT INTO users VALUES (?, ?, ?, ?, ?)", users_data)
# 插入订单数据orders_data = [ (101, 1, "iPhone", 7999, "2024-11-01"), (102, 1, "AirPods", 999, "2024-11-05"), (103, 2, "MacBook", 14999, "2024-11-10"), (104, 3, "iPad", 3999, "2024-11-15"), (105, 2, "键盘", 599, "2024-11-20"), (106, 4, "显示器", 2999, "2024-12-01"), (107, 5, "鼠标", 299, "2024-12-05"),]cursor.executemany("INSERT INTO orders VALUES (?, ?, ?, ?, ?)", orders_data)
conn.commit()
# 定义一个方便查询的辅助函数def query(sql): cursor.execute(sql) cols = [desc[0] for desc in cursor.description] rows = cursor.fetchall() # 打印表头 print(" | ".join(cols)) print("-" * (len(" | ".join(cols)))) for row in rows: print(" | ".join(str(v) for v in row)) print()一、查询数据(SELECT)
Section titled “一、查询数据(SELECT)”SELECT 是 SQL 中最常用的语句,用来从表中取数据。
-- 查询所有列SELECT * FROM users;
-- 查询指定列SELECT name, age, city FROM users;
-- 给列起别名SELECT name AS 姓名, age AS 年龄 FROM users;query("SELECT * FROM users")# id | name | age | city | salary# 1 | 张三 | 28 | 北京 | 15000# 2 | 李四 | 35 | 上海 | 22000# ...DISTINCT:去重
Section titled “DISTINCT:去重”-- 查询所有不重复的城市SELECT DISTINCT city FROM users;LIMIT:限制行数
Section titled “LIMIT:限制行数”-- 只取前 3 条SELECT * FROM users LIMIT 3;第一次写查询时,最稳的默认顺序
Section titled “第一次写查询时,最稳的默认顺序”更稳的顺序通常是:
- 先写
SELECT - 再写
FROM - 再看要不要加
WHERE - 最后再补排序和分组
这会比一上来就把所有子句混在一起更不容易乱。
二、条件过滤(WHERE)
Section titled “二、条件过滤(WHERE)”WHERE 就像 Pandas 的布尔索引,用来筛选满足条件的行。
-- 年龄大于 30SELECT * FROM users WHERE age > 30;
-- 城市是北京SELECT * FROM users WHERE city = '北京';
-- 薪资在 10000 到 20000 之间SELECT * FROM users WHERE salary BETWEEN 10000 AND 20000;-- AND:同时满足SELECT * FROM users WHERE city = '北京' AND age > 25;
-- OR:满足其一SELECT * FROM users WHERE city = '北京' OR city = '上海';
-- IN:在列表中SELECT * FROM users WHERE city IN ('北京', '上海', '深圳');
-- NOT:取反SELECT * FROM users WHERE city NOT IN ('北京');模糊匹配(LIKE)
Section titled “模糊匹配(LIKE)”-- % 匹配任意字符(类似 Pandas 的 str.contains)SELECT * FROM users WHERE name LIKE '张%'; -- 以"张"开头SELECT * FROM users WHERE name LIKE '%三'; -- 以"三"结尾SELECT * FROM users WHERE email LIKE '%@mail%'; -- 包含"@mail"NULL 处理
Section titled “NULL 处理”-- 判断是否为空(不能用 = NULL)SELECT * FROM users WHERE city IS NULL;SELECT * FROM users WHERE city IS NOT NULL;SQL vs Pandas 对照
Section titled “SQL vs Pandas 对照”| 需求 | SQL | Pandas |
|---|---|---|
| 年龄大于 30 | WHERE age > 30 | df[df["age"] > 30] |
| 城市是北京 | WHERE city = '北京' | df[df["city"] == "北京"] |
| 多条件与 | WHERE age > 30 AND city = '北京' | df[(df["age"] > 30) & (df["city"] == "北京")] |
| 多条件或 | WHERE city IN ('北京', '上海') | df[df["city"].isin(["北京", "上海"])] |
| 模糊匹配 | WHERE name LIKE '张%' | df[df["name"].str.startswith("张")] |
| 为空 | WHERE city IS NULL | df[df["city"].isna()] |
一个很适合初学者先记的对照表
Section titled “一个很适合初学者先记的对照表”| 你脑子里的问题 | 更像哪种 SQL |
|---|---|
| 只看满足条件的记录 | WHERE |
| 看一张表里有哪些不重复的值 | DISTINCT |
| 只拿前几条看看 | LIMIT |
| 把两张表接起来 | JOIN |
| 先分组再统计 | GROUP BY |
这张表很适合新人,因为它会把 SQL 从关键字列表重新压回几类最常见的问题。
三、排序(ORDER BY)
Section titled “三、排序(ORDER BY)”-- 按薪资升序(默认)SELECT * FROM users ORDER BY salary;
-- 按薪资降序SELECT * FROM users ORDER BY salary DESC;
-- 先按城市排序,同城市再按薪资降序SELECT * FROM users ORDER BY city, salary DESC;为什么 ORDER BY 常常最后再写?
Section titled “为什么 ORDER BY 常常最后再写?”因为排序更像:
- 结果已经出来了,我最后想按什么顺序看
这和:
- 先筛选
- 先分组
不是同一层问题。
四、聚合函数与分组(GROUP BY)
Section titled “四、聚合函数与分组(GROUP BY)”常用聚合函数
Section titled “常用聚合函数”| 函数 | 作用 | 示例 |
|---|---|---|
COUNT(*) | 计数 | 总共多少条记录 |
SUM(col) | 求和 | 总薪资 |
AVG(col) | 平均值 | 平均年龄 |
MAX(col) | 最大值 | 最高薪资 |
MIN(col) | 最小值 | 最低年龄 |
-- 基本聚合SELECT COUNT(*) AS 总人数, AVG(salary) AS 平均薪资, MAX(salary) AS 最高薪资FROM users;GROUP BY:分组统计
Section titled “GROUP BY:分组统计”-- 按城市统计人数和平均薪资SELECT city, COUNT(*) AS 人数, AVG(salary) AS 平均薪资FROM usersGROUP BY city;city | 人数 | 平均薪资北京 | 2 | 25000.0上海 | 2 | 20000.0广州 | 1 | 8000.0深圳 | 1 | 12000.0HAVING:对分组结果过滤
Section titled “HAVING:对分组结果过滤”-- 找出平均薪资超过 15000 的城市SELECT city, AVG(salary) AS avg_salaryFROM usersGROUP BY cityHAVING avg_salary > 15000;SQL 执行顺序
Section titled “SQL 执行顺序”SQL 的书写顺序和执行顺序不同:
flowchart TD A["1. FROM<br/>确定数据来源"] --> B["2. WHERE<br/>过滤原始行"] B --> C["3. GROUP BY<br/>分组"] C --> D["4. HAVING<br/>过滤分组"] D --> E["5. SELECT<br/>选择列"] E --> F["6. ORDER BY<br/>排序"] F --> G["7. LIMIT<br/>限制行数"]
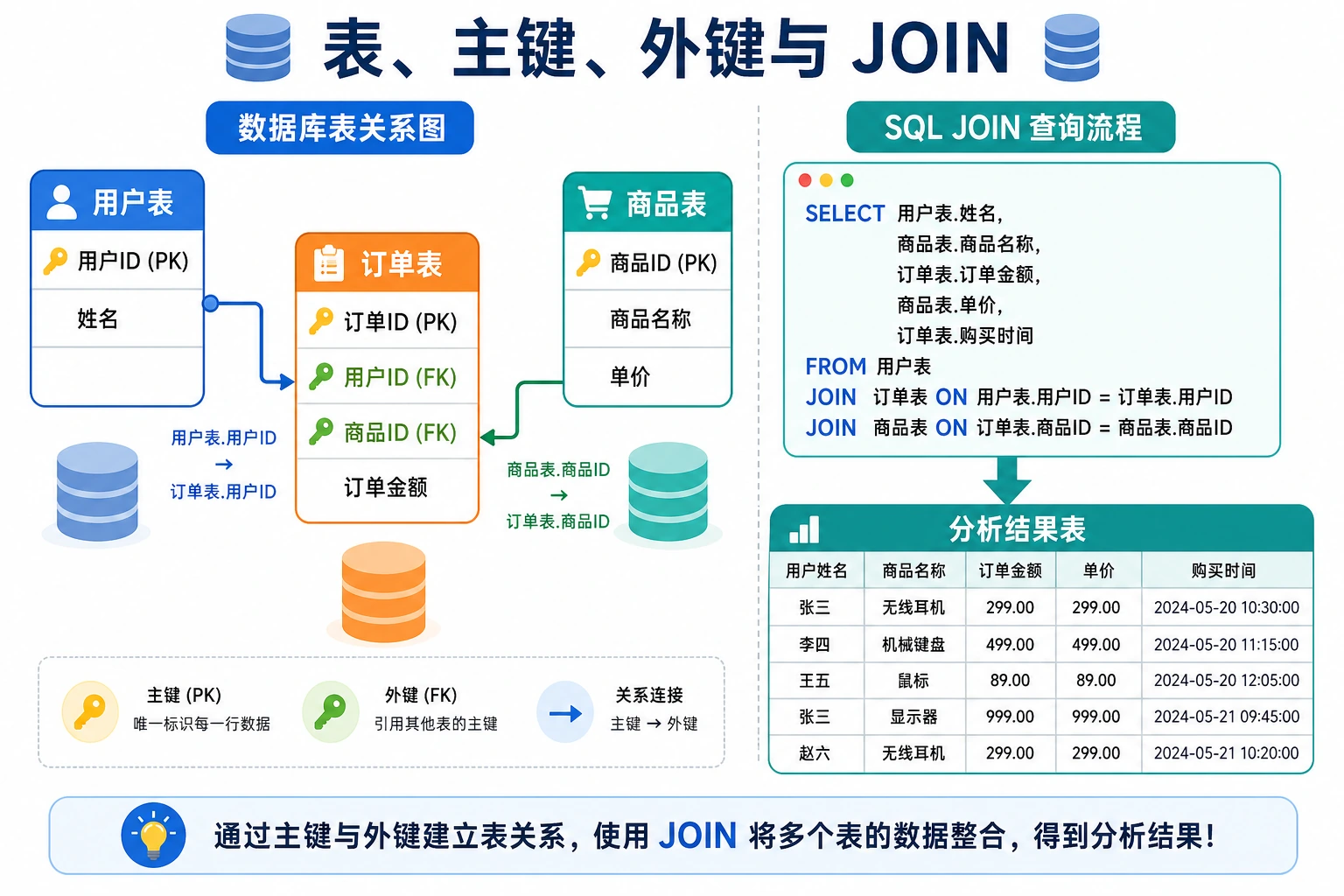
style A fill:#e3f2fd,stroke:#1565c0,color:#333 style E fill:#fff3e0,stroke:#e65100,color:#333五、多表连接(JOIN)
Section titled “五、多表连接(JOIN)”JOIN 是 SQL 最强大的功能之一,让你把多张表的数据合并在一起。
INNER JOIN:内连接
Section titled “INNER JOIN:内连接”只返回两张表都有匹配的行。
-- 查询每个用户的订单信息SELECT users.name, orders.product, orders.amountFROM usersINNER JOIN orders ON users.id = orders.user_id;| name | product | amount |
|---|---|---|
| 张三 | iPhone | 7999.0 |
| 张三 | AirPods | 999.0 |
| 李四 | MacBook | 14999.0 |
| 王五 | iPad | 3999.0 |
| 李四 | 键盘 | 599.0 |
| 赵六 | 显示器 | 2999.0 |
| 钱七 | 鼠标 | 299.0 |
注意:孙八没有订单,所以不出现在结果中。
LEFT JOIN:左连接
Section titled “LEFT JOIN:左连接”返回左表所有行,右表没匹配的显示 NULL。
-- 查询所有用户及其订单(没有订单的也显示)SELECT users.name, orders.product, orders.amountFROM usersLEFT JOIN orders ON users.id = orders.user_id;name | product | amount张三 | iPhone | 7999.0张三 | AirPods | 999.0李四 | MacBook | 14999.0...孙八 | None | None ← 没有订单,但也显示了JOIN 类型对比
Section titled “JOIN 类型对比”flowchart TD A["JOIN 类型"] --> B["INNER JOIN<br/>只要两边都有的"] A --> C["LEFT JOIN<br/>左边全要,右边没有填 NULL"] A --> D["RIGHT JOIN<br/>右边全要,左边没有填 NULL"] A --> E["FULL OUTER JOIN<br/>两边都全要"]
style B fill:#e8f5e9,stroke:#2e7d32,color:#333 style C fill:#e3f2fd,stroke:#1565c0,color:#333 style D fill:#fff3e0,stroke:#e65100,color:#333 style E fill:#f3e5f5,stroke:#7b1fa2,color:#333实用组合:JOIN + GROUP BY
Section titled “实用组合:JOIN + GROUP BY”-- 查询每个用户的订单总额SELECT users.name, COUNT(orders.order_id) AS 订单数, SUM(orders.amount) AS 总消费FROM usersLEFT JOIN orders ON users.id = orders.user_idGROUP BY users.id, users.nameORDER BY 总消费 DESC;六、增删改(INSERT / UPDATE / DELETE)
Section titled “六、增删改(INSERT / UPDATE / DELETE)”-- 插入一条INSERT INTO users (name, age, city, salary) VALUES ('周九', 29, '杭州', 16000);
-- 插入多条INSERT INTO users (name, age, city, salary) VALUES ('吴十', 33, '成都', 13000), ('郑十一', 27, '南京', 11000);-- 给张三加薪UPDATE users SET salary = 18000 WHERE name = '张三';
-- 所有北京员工加薪 10%UPDATE users SET salary = salary * 1.1 WHERE city = '北京';-- 删除指定记录DELETE FROM users WHERE name = '周九';
-- 删除所有年龄小于 20 的DELETE FROM users WHERE age < 20;第一次学 SQL 时,最稳的默认顺序
Section titled “第一次学 SQL 时,最稳的默认顺序”更稳的顺序通常是:
- 先把
SELECT / FROM / WHERE写顺 - 再补
ORDER BY - 再补
GROUP BY / HAVING - 最后再学
JOIN和增删改
这样会比一上来就背所有语法块更不容易乱。
SQL 语句速查表
Section titled “SQL 语句速查表”| 操作 | SQL 语法 | 说明 |
|---|---|---|
| 查询所有 | SELECT * FROM 表名 | 取全部数据 |
| 查询指定列 | SELECT 列1, 列2 FROM 表名 | 取部分列 |
| 条件过滤 | SELECT ... WHERE 条件 | 筛选行 |
| 排序 | ORDER BY 列 DESC | 降序排列 |
| 限制行数 | LIMIT 10 | 取前 N 条 |
| 去重 | SELECT DISTINCT 列 | 唯一值 |
| 聚合 | COUNT / SUM / AVG / MAX / MIN | 统计计算 |
| 分组 | GROUP BY 列 | 分组统计 |
| 分组过滤 | HAVING 条件 | 过滤分组 |
| 内连接 | INNER JOIN 表 ON 条件 | 两表交集 |
| 左连接 | LEFT JOIN 表 ON 条件 | 左表全部 |
| 插入 | INSERT INTO 表 VALUES (...) | 添加数据 |
| 更新 | UPDATE 表 SET 列=值 WHERE 条件 | 修改数据 |
| 删除 | DELETE FROM 表 WHERE 条件 | 删除数据 |
学完这一页,至少保留这张证据卡:
- 架构
- 表名、键、关系和示例行
- 查询
- 所使用的 SQL 或 Python 数据库代码
- 输出
- 结果行、行数,或保存的抽取结果
- 失败检查
- 错误的连接键、不安全查询、缺少事务,或 schema 不匹配
- 期望产出
- 查询、结果表和一条数据质量说明
SQL 就是和数据库”说话”的语言,核心就 4 类操作:
| 类别 | 关键字 | 作用 |
|---|---|---|
| 查 | SELECT | 数据查询(最常用) |
| 增 | INSERT | 插入新数据 |
| 改 | UPDATE | 修改已有数据 |
| 删 | DELETE | 删除数据 |
其中 SELECT 搭配 WHERE、JOIN、GROUP BY 能完成绝大部分数据分析需求。
这节最该带走什么
Section titled “这节最该带走什么”- SQL 最重要的不是关键字多,而是你能不能用它稳定地对表提问
- 先想“我要哪些列、哪些行、怎样分组”,再写 SQL,会比背语法更稳
WHERE / GROUP BY / JOIN这三层一旦顺了,后面大多数查询都能拆开理解
练习 1:基础查询
Section titled “练习 1:基础查询”-- 使用上面的练习数据库,完成以下查询:-- 1. 查询所有上海的用户-- 2. 查询薪资最高的 3 个人-- 3. 查询每个城市的平均薪资,按平均薪资降序排列练习 2:JOIN 查询
Section titled “练习 2:JOIN 查询”-- 1. 查询所有用户的姓名和他们买过的产品-- 2. 查询没有下过单的用户-- 提示:LEFT JOIN + WHERE orders.order_id IS NULL-- 3. 查询每个用户的订单总额,包括没有订单的用户(显示为 0)练习 3:综合分析
Section titled “练习 3:综合分析”-- 用一条 SQL 完成:-- 查询消费总额超过 5000 的用户姓名、订单数量和总消费-- 按总消费降序排列参考实现与讲解
- 筛选题用
WHERE,排序和 top-k 用ORDER BY ... LIMIT,城市平均值用GROUP BY city加AVG(...)。 - 订单报表中,如果只关心有订单的客户用
JOIN;如果没有订单的客户也要保留,用LEFT JOIN。COALESCE可把 null 总消费显示成 0。 - 总消费超过阈值这类汇总筛选,要先聚合再用
HAVING,不要用WHERE,因为条件依赖分组结果。