E.C.1 支持向量机
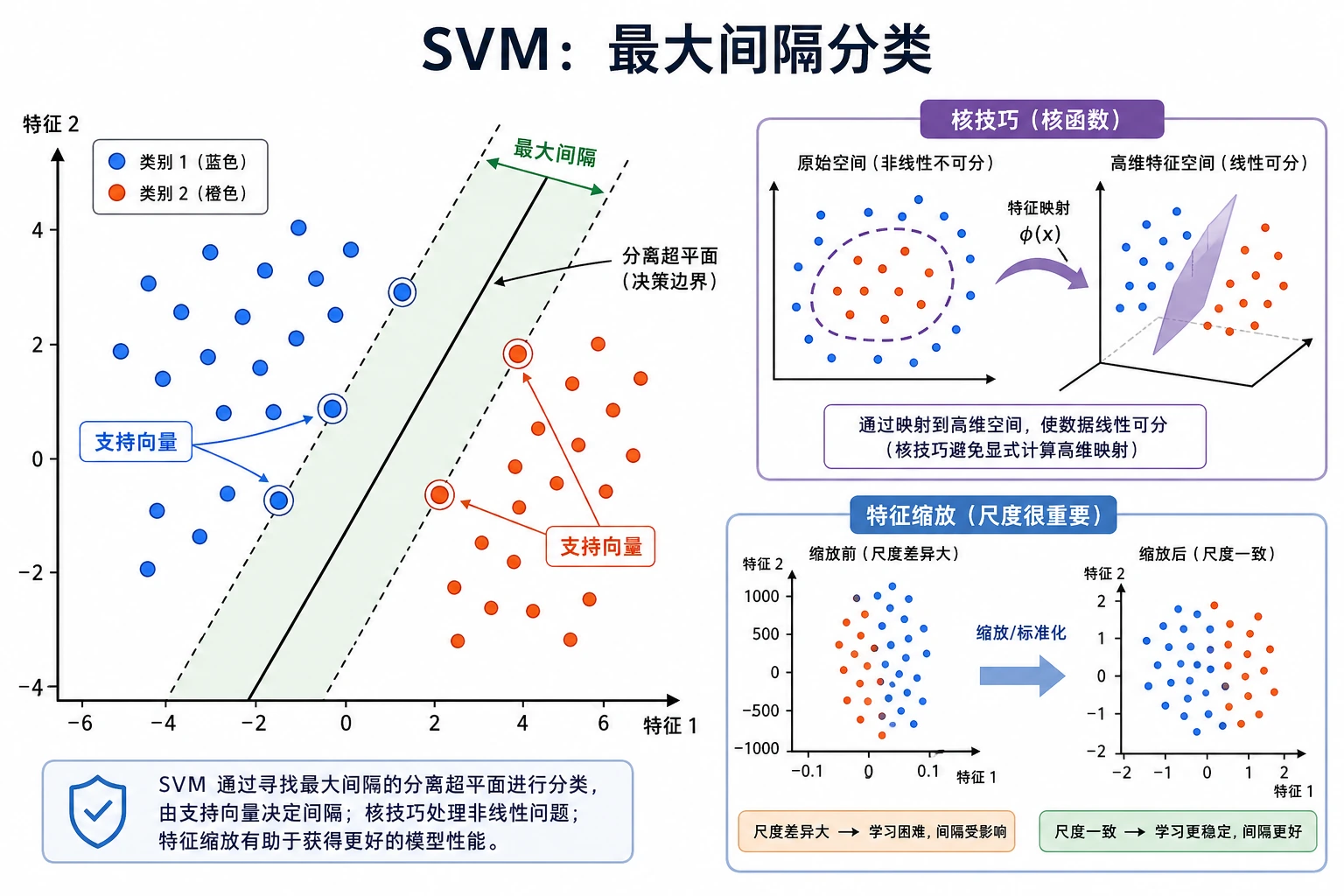
SVM 会寻找一个间隔尽量大的决策边界。离边界最近的点叫支持向量,它们是最影响边界位置的关键样本。
- Python 3.10+
- 当前稳定版
scikit-learn和numpy
python -m pip install -U scikit-learn numpy- Margin(间隔):边界到最近样本的距离。
- Support vector(支持向量):靠近边界的关键样本。
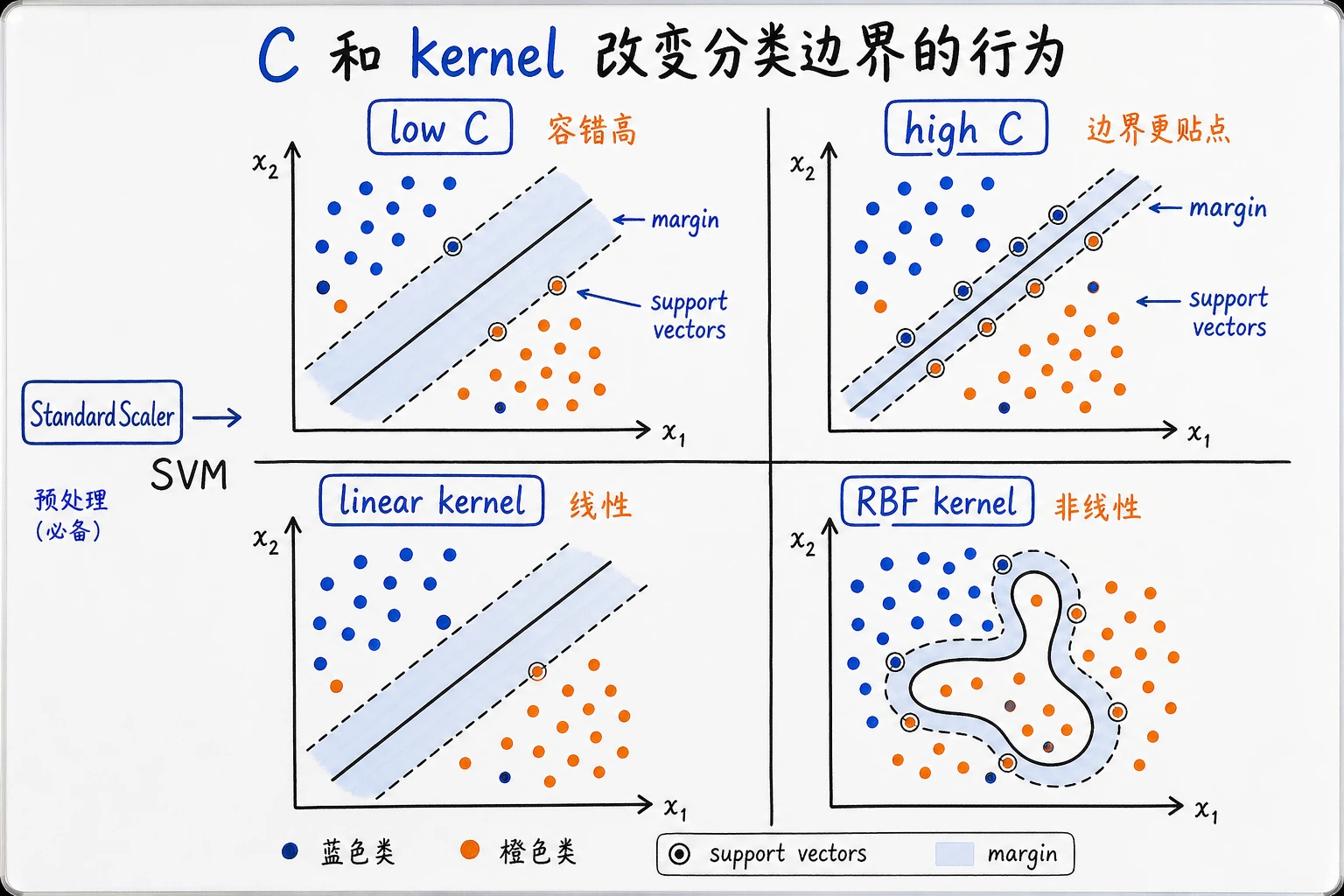
C:控制对错误的容忍度。C越大,通常越贴合训练集。- Kernel(核函数):控制边界是线性的,还是非线性的。
- Scaling(缩放):SVM 通常需要把特征范围标准化。
运行线性 SVM baseline
Section titled “运行线性 SVM baseline”创建 svm_baseline.py:
import numpy as npfrom sklearn.pipeline import make_pipelinefrom sklearn.preprocessing import StandardScalerfrom sklearn.svm import SVC
X = np.array([ [1.0, 1.2], [1.3, 0.9], [1.1, 1.0], [4.0, 4.2], [4.3, 3.8], [3.9, 4.1],])y = np.array([0, 0, 0, 1, 1, 1])
model = make_pipeline( StandardScaler(), SVC(kernel="linear", C=1.0),)
model.fit(X, y)pred = model.predict([[1.2, 1.1], [4.2, 4.0]])svc = model.named_steps["svc"]
print("predictions:", pred.tolist())print("support_per_class:", svc.n_support_.tolist())运行:
python svm_baseline.py预期输出:
predictions: [0, 1]support_per_class: [2, 1]这是最小可用 SVM 习惯:缩放特征、训练模型、预测、检查支持向量。
运行这个独立对比:
from sklearn.svm import SVC
for kernel in ["linear", "rbf"]: if kernel == "linear": model = SVC(kernel="linear", C=1.0) else: model = SVC(kernel="rbf", C=1.0, gamma="scale") print(model)预期输出开头类似:
SVC(kernel='linear')SVC()边界简单时先用 linear。如果线性 SVM 明显欠拟合,或者边界看起来是弯曲的,再尝试 rbf。
适合尝试 SVM:
- 数据量中小。
- 特征已经有意义。
- 类别边界比较清楚。
- 想在重模型之前做一个强 baseline。
如果数据很大,或者预测延迟要求极低,就要谨慎。
Baseline 复盘
Section titled “Baseline 复盘”复盘 SVM 时,不要只记录预测标签。还要记录特征是否缩放、kernel 是什么、C 如何影响边界,以及支持向量数量如何变化。
SVM 的价值在于边界解释和强 baseline。如果加入噪声点后支持向量数量大幅变化,就要写下这个限制,再决定是否换特征、换 kernel,或换更适合的模型。
交付检查时,至少比较两个 C 值,并记录支持向量数量。这个数字能提醒你模型是否过度贴合边界点。若高 C 在训练集上更好,却对新样本更不稳,就把它作为失败样本留给后续模型。
同时写清是否做了特征缩放。没有缩放的 SVM 结果,很可能只是特征尺度在影响边界。
学完这一页,至少保留这张证据卡:
- 模型家族
- SVM、KNN、朴素贝叶斯、LDA 或其他传统基线
- 数据视图
- 特征缩放、类别平衡、决策边界和训练/测试划分
- 指标
- 准确率/F1、混淆矩阵、边距、邻近行为或投影质量
- 失败检查
- 缩放、高维度、假设薄弱、泄漏或基线拟合差
- 期望产出
- 经典机器学习基线结果,以及一条局限性说明
- 忘记
StandardScaler()。 - 还没试线性就直接上复杂 kernel。
- 没检查特征质量,就先调
C和 kernel。
在边界附近加两个噪声点,对比 C=0.1、C=1.0、C=10.0。记录每个版本用了多少支持向量。
参考实现与讲解
好的答案会记录一个小表:C、预测或分数、支持向量数量。较低的 C 通常允许更宽、更软的间隔,也更能容忍噪声点;较高的 C 会更努力地把训练点分对,因此边界可能更受新噪声样本影响。
具体支持向量数量取决于你新增的点,不要编一个通用数字。正确解释应聚焦趋势:软间隔和拟合噪声训练样本之间的取舍。